参考:蘑菇书EasyRL
演员-评论员算法是结合策略梯度和时序差分学习的强化学习方法
- Advantage Actor-Critic(A2C)
- Asynchronous Advantage Actor-Critic (A3C)(多进程)
Asynchronous Methods for Deep Reinforcement Learning
Policy Gradient梯度策略(PG)_bujbujbiu的博客-CSDN博客
Proximal Policy Optimization近端策略优化(PPO)_bujbujbiu的博客-CSDN博客
(建议学习路线:PG——A2C——PPO )
目录
1.策略梯度回顾
在策略梯度中更新策略参数公式如下:
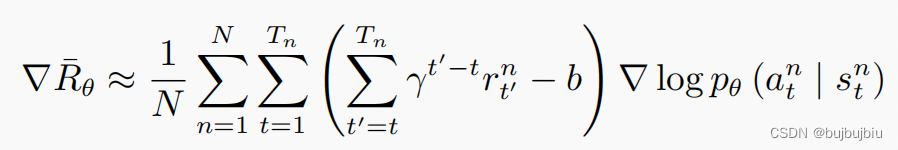
首先通过智能体与环境交互,可以计算某一状态s下采取某一动作a的概率,接下来计算从状态s执行动作a之后一直到结束的累积折扣奖励,通常将折扣因子设置为0.9或者0.99,同时减去一个基线b,这样括号里面就有正有负,用G表示累积折扣奖励,G是一个随机变量,即便有固定分布,但是方差也很大,采样次数可能不太够的情况下,结果不稳定,如正好采样到G=-10,G=100,结果就会差很多。因此为了训练的稳定性,我们希望能直接固定随机变量G的期望值,这就需要引入value-based的方法即深度Q网络。
2.深度Q网络
深度Q网络中有两种函数 ,有两种评论员
:假设演员的策略是
,使用
:在状态 s 采取动作 a,接下来用策略 π 与环境交互,累积奖励的期望值是多
少。输入s,输出每个a的Q值

3.优势演员-评论员算法
策略梯度中随机变量G的期望值便是Q值
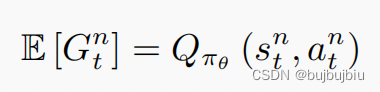
因此可以使用Q值替换策略参数更新公式中的累积奖励,Q函数表示某一个状态 s,采取某一个动作 a,假设策略是 π 的情况下所能得到的累积奖励的期望值,即 G 的期望值。这样就把演员和评论员两个方法结合。

对于基线b可以用价值函数 ,价值函数的定义为,假设策略是 π,其在某个状态 s 一直与环境交互直到游戏结束,期望奖励有多大。
没有涉及到动作,
涉及到动作,
是
的期望值,因此两者差值有正有负,将原先的权重项变成优势函数得到A2C。

如果这样实现有一个缺点,需要估计两个网络:Q网络和V网络,风险扩大。实际上确实可以只估计V,用V的值表示Q。用期望是因为在s执行a得到的r是什么,进入什么新状态是有随机性的
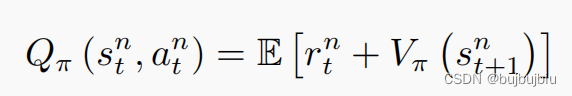
但是实际上在实现的时候,去掉了期望值,这样虽然增加了一点r的方差,但是r和G相比只是一小部分,也是合理的,并且论文作者在多次试验后发现,去掉期望值的效果更好。


注意此处说的Q网络,V网络都是评论员,用V值表示Q值后只有一个评论员,但是还有演员需要与环境交互,因此A2C还是有两个网络(一个演员网络和一个评论员网络)
我们有一个 π,有个初始的演员与环境交互,先收集资料。在策略梯度方法里收集资料以后,就来更新策略。但是在演员-评论员算法里面,我们不是直接使用那些资料来更新策略。我们先用这些资料去估计价值函数,可以用时序差分方法或蒙特卡洛方法来估计价值函数。接下来,我们再基于价值函数,使用上述参数更新公式更新 π。有了新的 π 以后,再与环境交互,收集新的资料,去估计价值函数。再用新的价值函数更新策略,更新演员。整个优势演员-评论员算法就是这么运作的。
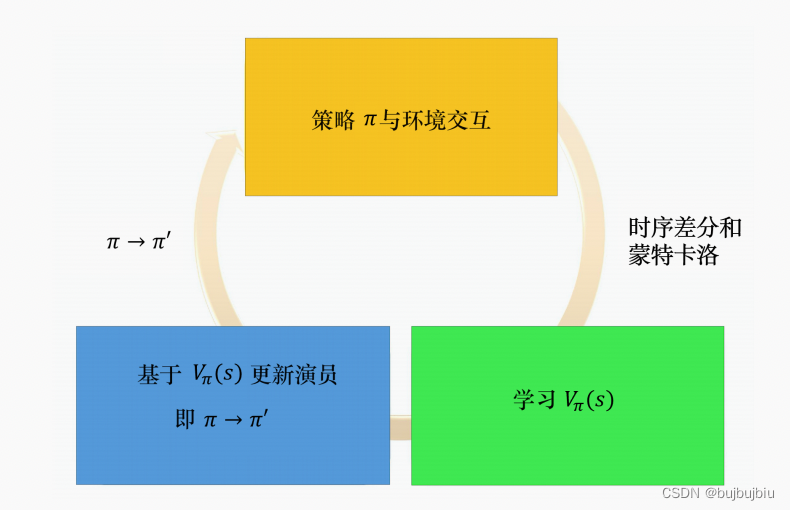
在实现演员—评论员算法时,有两个技巧:
- 演员网络和评论员网络共享一部分层,其输入都是s
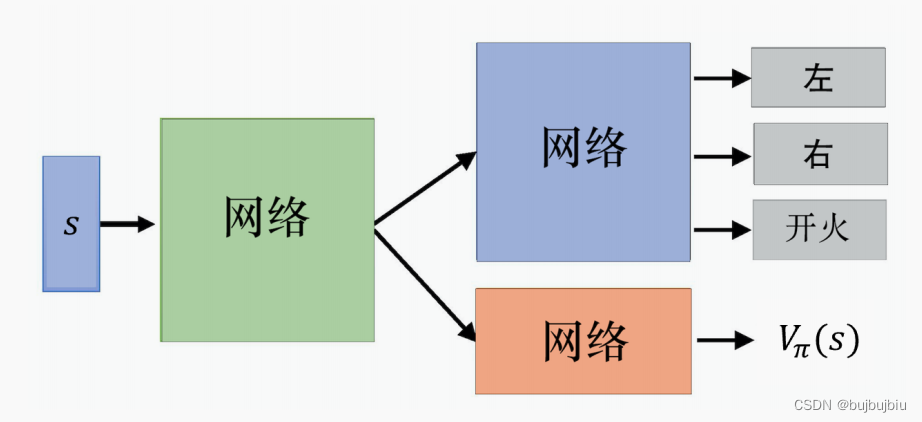
- 对
平均一些