参考:
https://pytorch.org/docs/0.4.1/torchvision/models.html
https://zhuanlan.zhihu.com/p/436574436
https://blog.csdn.net/u014297502/article/details/125884141
Network Top-1 error Top-5 error
AlexNet 43.45 20.91
VGG-11 30.98 11.37
VGG-13 30.07 10.75
VGG-16 28.41 9.62
VGG-19 27.62 9.12
VGG-11 with batch normalization 29.62 10.19
VGG-13 with batch normalization 28.45 9.63
VGG-16 with batch normalization 26.63 8.50
VGG-19 with batch normalization 25.76 8.15
ResNet-18 30.24 10.92
ResNet-34 26.70 8.58
ResNet-50 23.85 7.13
ResNet-101 22.63 6.44
ResNet-152 21.69 5.94
SqueezeNet 1.0 41.90 19.58
SqueezeNet 1.1 41.81 19.38
Densenet-121 25.35 7.83
Densenet-169 24.00 7.00
Densenet-201 22.80 6.43
Densenet-161 22.35 6.20
Inception v3 22.55 6.44
自带预训练模型对手写数字微调
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# 定义数据转换和加载 MNIST 数据集
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64, shuffle=False)
# 加载 torchvision 中的预训练模型
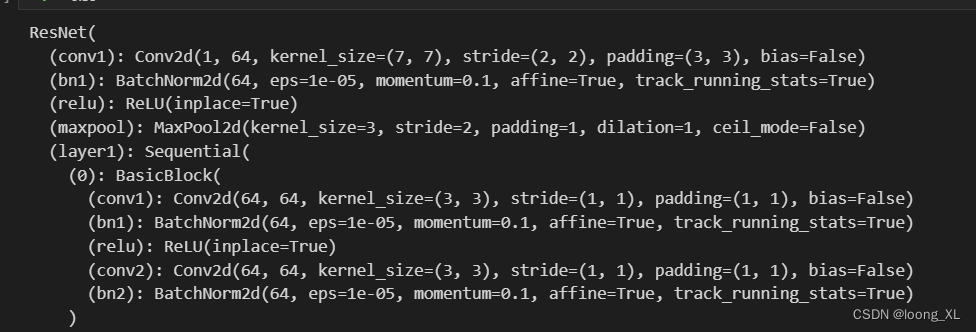
model = torchvision.models.resnet18(pretrained=True)
#下面两行冻结模型的所有参数;不加这两行就是全量训练
for param in model.parameters():
param.requires_grad = False
model.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False) # 修改输入通道数为1 (因为resnet18输入图像维度3,MNIST图片维度是1)
#修改模型的最后一层/分类器,用于适应特定任务的类别数量
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)

##训练
epochs = 10
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
# print(inputs.shape)
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 200 == 199:
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
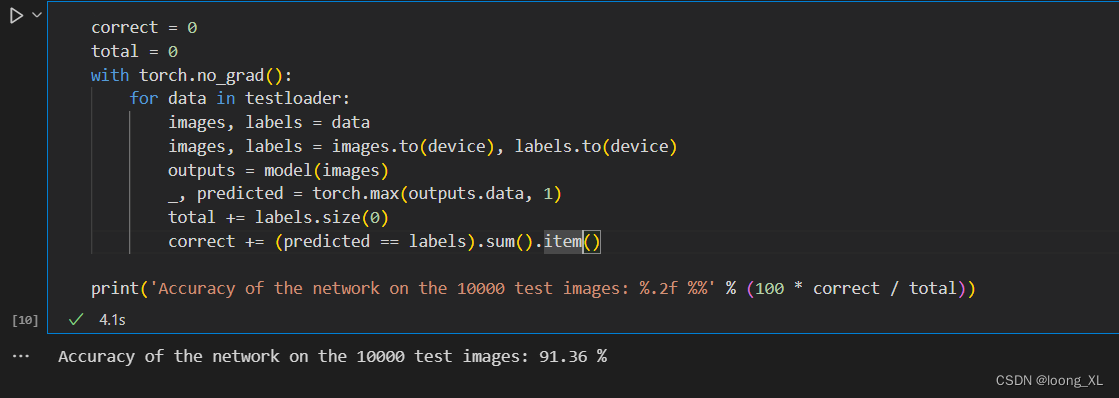
### 验证
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (100 * correct / total))