code:
import csv
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from pprint import pprint
if __name__ == '__main__':
path = "Advertising.csv"
# 这里使用pandas读取数据
data = pd.read_csv(path)
x = data[['TV', 'Radio', 'Newspaper']]
y = data['Sales']
print("X data:")
print(x)
print("Y data:")
print(y)
# 绘制出文件中的数据
plt.figure(figsize=(15,15))
plt.subplot(311)
plt.plot(data['TV'], y, 'ro')
plt.title('TV')
plt.grid()
plt.subplot(312)
plt.plot(data['Radio'], y, 'g^')
plt.title('Radio')
plt.grid()
plt.subplot(313)
plt.plot(data['Newspaper'], y, 'b*')
plt.title('Newspaper')
plt.grid()
plt.tight_layout()
plt.show()
# 使用sklearn包进行数据训练和拟合,从文件中选择80%的数据进行训练
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=1)
print("x_train:")
print(x_train)
print("y_train")
print(y_train)
# 读取线性回归模型,然后进行数据拟合
linreg = LinearRegression()
model = linreg.fit(x_train, y_train)
print('+++++++++++++++++++++')
print(model)
print('++++++++++++++++++++')
print(linreg.coef_)
print(linreg.intercept_)
y_hat = linreg.predict(np.array(x_test))
mse = np.average((y_hat - np.array(y_test)) ** 2)
rmse = np.sqrt(mse)
print(mse)
print(rmse)
t = np.arange(len(x_test))
# plt.figure(figsize=(15,15))
plt.plot(t, y_test, 'r-', lw=2, label="True data")
plt.plot(t, y_hat, 'g-', lw=2, label='Predicted data')
plt.legend(loc='upper right')
plt.title('Regression method to regress sales', fontsize=18)
plt.grid()
plt.show()


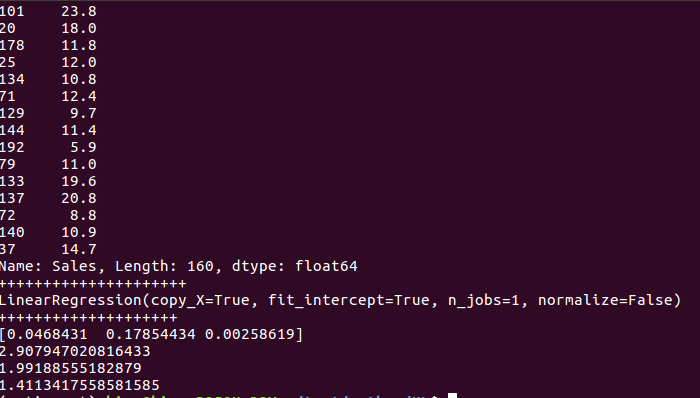
这里再使用其他的线性回归方法来实现该模型,其实大同小异,无非就是loss function不同,约束条件不同,具体可以搜索lasso和ridge regression方法。
import csv
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.linear_model import Lasso, Ridge
from pprint import pprint
if __name__ == '__main__':
path = "Advertising.csv"
# 这里使用pandas读取数据
data = pd.read_csv(path)
x = data[['TV', 'Radio', 'Newspaper']]
y = data['Sales']
print("X data:")
print(x)
print("Y data:")
print(y)
# 绘制出文件中的数据
plt.figure(figsize=(15,15))
plt.subplot(311)
plt.plot(data['TV'], y, 'ro')
plt.title('TV')
plt.grid()
plt.subplot(312)
plt.plot(data['Radio'], y, 'g^')
plt.title('Radio')
plt.grid()
plt.subplot(313)
plt.plot(data['Newspaper'], y, 'b*')
plt.title('Newspaper')
plt.grid()
plt.tight_layout()
plt.show()
# 使用sklearn包进行数据训练和拟合,从文件中选择80%的数据进行训练
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=1)
print("x_train:")
print(x_train)
print("y_train")
print(y_train)
# 读取线性回归模型,然后进行数据拟合
model = Lasso()
# model = Ridge()
alpha_can = np.logspace(-3, 2, 10)
lass_model1 = GridSearchCV(model, param_grid={'alpha':alpha_can}, cv=5)
lass_model1.fit(x_train, y_train)
print('+++++++++++++++++++++')
print(model)
print('++++++++++++++++++++')
print("hyper-parameter:\n", lass_model1.best_params_)
y_hat = lass_model1.predict(np.array(x_test))
print("lasso_models score:\n", lass_model1.score(x_test, y_test))
mse = np.average((y_hat - np.array(y_test)) ** 2)
rmse = np.sqrt(mse)
print(mse)
print(rmse)
t = np.arange(len(x_test))
# plt.figure(figsize=(15,15))
plt.plot(t, y_test, 'r-', lw=2, label="True data")
plt.plot(t, y_hat, 'g-', lw=2, label='Predicted data')
plt.legend(loc='upper right')
plt.title('New Regression method to regress sales', fontsize=18)
plt.grid()
plt.show()


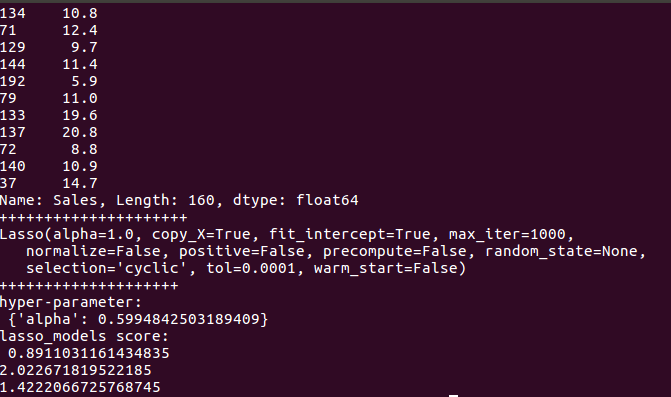
当然波士顿房价经典数据也拿来试试:
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNetCV
import sklearn.datasets
from pprint import pprint
from sklearn.preprocessing import PolynomialFeatures, StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import mean_squared_error
import warnings
def not_empty(s):
return s != ''
if __name__ == "__main__":
warnings.filterwarnings(action='ignore')
np.set_printoptions(suppress=True)
# 方法使用pandas读取数据
file_data = pd.read_csv('housing.data', header=None)
# a = np.array([float(s) for s in str if s != ''])
data = np.empty((len(file_data), 14))
for i, d in enumerate(file_data.values):
d = list(map(float, filter(not_empty, d[0].split(' '))))
data[i] = d
x, y = np.split(data, (13, ), axis=1)
# 方法使用sklearn自动导入数据,需要联网
# data = sklearn.datasets.load_boston()
# x = np.array(data.data)
# y = np.array(data.target)
print('numbers of samples:%d, numbers of features:%d' % x.shape)
print(y.shape)
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, random_state=0)
model = Pipeline([
('ss', StandardScaler()),
('poly', PolynomialFeatures(degree=3, include_bias=True)),
('linear', ElasticNetCV(l1_ratio=[0.1, 0.3, 0.5, 0.7, 0.99, 1], alphas=np.logspace(-3, 2, 5),
fit_intercept=False, max_iter=1e3, cv=3))
])
print('modeling...')
model.fit(x_train, y_train.ravel())
linear = model.get_params('linear')['linear']
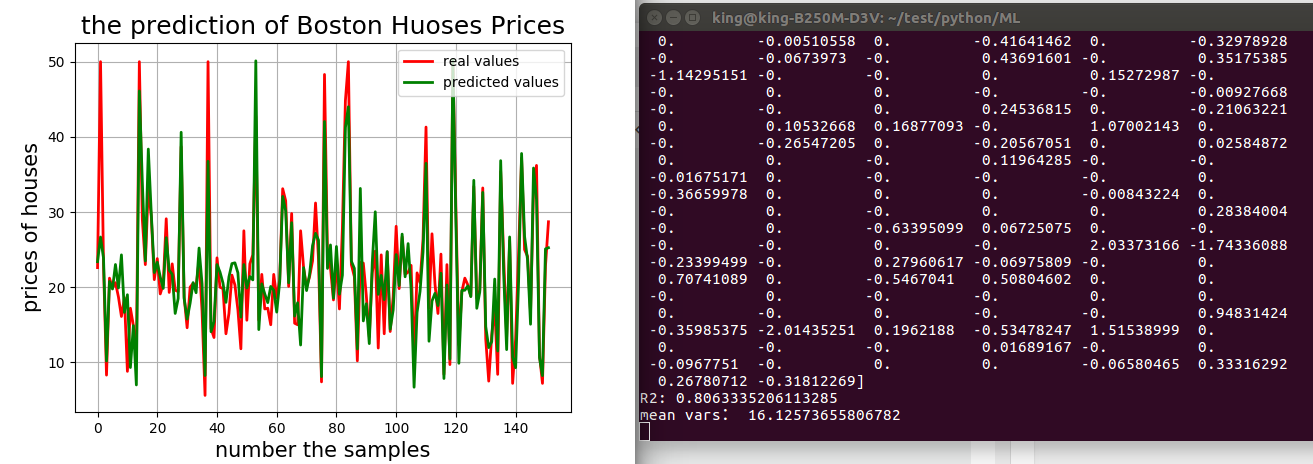
print('hyper-parameters:', linear.alpha_)
print('L1 ratio:', linear.l1_ratio_)
print('parmas:', linear.coef_.ravel())
y_pred = model.predict(x_test)
r2 = model.score(x_test, y_test)
mse = mean_squared_error(y_test, y_pred)
print('R2:', r2)
print('mean vars:', mse)
t = np.arange(len(y_pred))
plt.figure(facecolor='w')
plt.plot(t, y_test.ravel(), 'r-', lw=2, label='real values')
plt.plot(t, y_pred, 'g-', lw=2, label='predicted values')
plt.legend(loc='best')
plt.title('the prediction of Boston Huoses Prices', fontsize=18)
plt.xlabel('number the samples', fontsize=15)
plt.ylabel('prices of houses', fontsize=15)
plt.grid()
plt.show()
(向邹博老师学习ML)