利用sklearn进行线性拟合时,通常要进行数据转换,目的在于将数据集中的数据转换为可供Python进行解算的矩阵,举一个栗子来说明:
假设我们使用多项式回归来做模拟,阶次为2,有4个特征,易知,我们的多项式展开为:
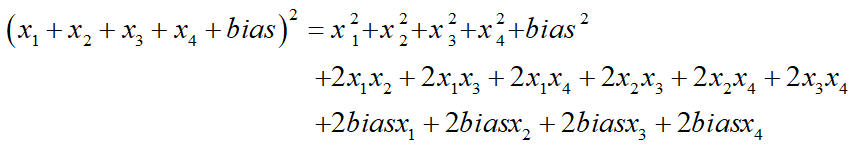
由上式易知,4个特征加一个偏置项bias,完全展开后有15项,当有m个特征,阶次为2时,展开后项数为
(m+1)*(m+2)/2,当阶次为3 4 5时请自行推导.这里就不墨迹了
那么我们就要定义的系数就有15项,代码如下,
# 导入必备的包
from sklearn.preprocessing import PolynomialFeatures
import pandas as pd
# 预先定义数据
x = pd.DataFrame(data =[[0 , 21.89, 40.000000, 20.926667],
[0 , 19.00, 40.000000, 17.500000],
[0 , 20.00, 44.433333, 19.100000],
[0 , 19.00, 42.700000, 19.100000],
[0 , 18.50, 42.500000, 17.890000]],columns=['lights','T1','RH_1','T2'])
ss = PolynomialFeatures(degree=2) # 定义多项式回归模型,阶次定义为2
'''
仅传入一个x时,fit_transform() 等价于 transform()
注意,在没有做拟合前,不可以直接使用transform(),必须使用fit_transform()
'''
x_transform = ss.fit_transform(x)
'''
等号左侧:转换后的数据尺寸
等号右侧:样本数 * (特征数 + 1) * (特征数 + 2) /2
'''
print(
x_transform.size ==
x.shape[0] * (x.shape[1] + 1) * (x.shape[1] + 2) /2
)