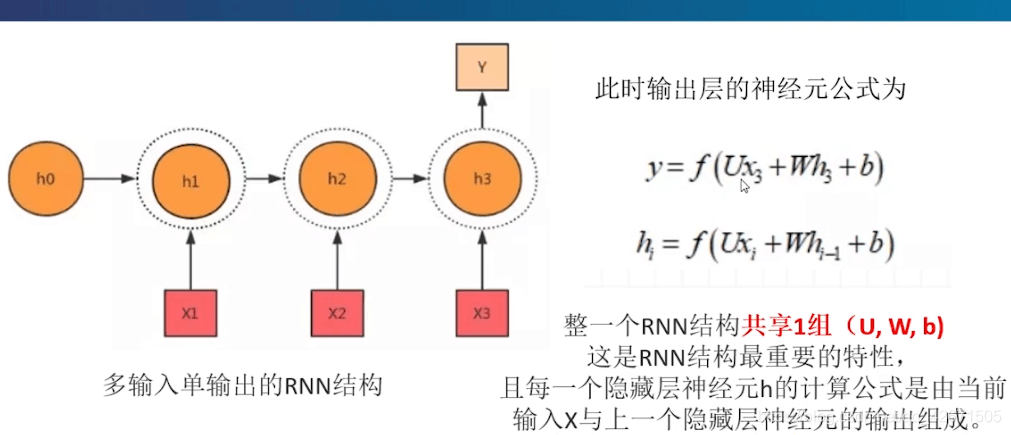
这是最基础的多输入单输出的Rnn吧。比如讲了一段话,然后发现重点。
Rnn中最明显的缺点就是共享了一组U,W,b,都是不变的,看这个输出y和hi,其中这个图中hi就是h1,h2,h3,还可以发现h2依赖于h1的结果,h3依赖于h2的结果,等等。
Rnn可以是多个并且有序,比如像人物说话,或者做事一样,都是有时间序列的,就可以模仿真实人物一样,一个接着一个。而不是比如单纯的线性预测一样,给定一个文档数据,直接用梯度下降拟合就可以了。Rnn是有时间控制的,相当于一个记忆能力,因为比如说你这个话就连接着下一句话,他们之间的w权值就比较大。所以用Rnn处理有时间序列的数据就很实用。像这个距离时间预测就很符合。
**
Seq2seq的两种形式:
**
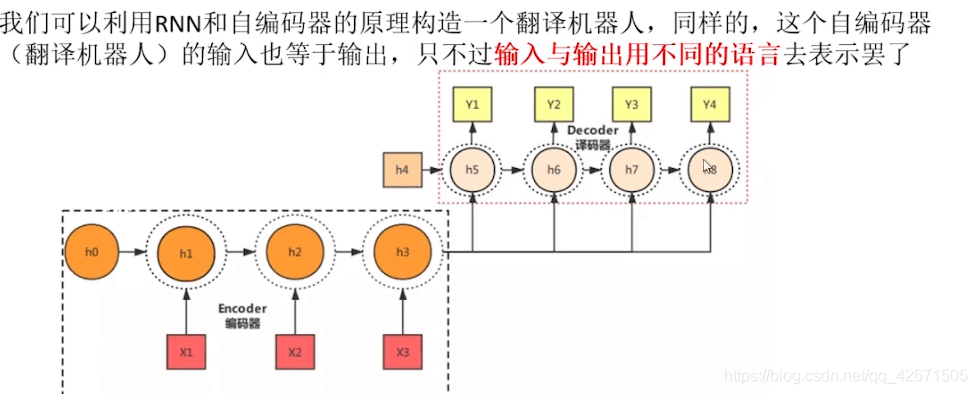
其中Encoder-Decoder比较多见,编码器与译码器,其实内部就是个黑盒子根据公式推的。这种情况是编码器的输出等于下一个译码器的输入。然后再译码,就得到一个个Y值。这里的h4给h5到h8(h6中含有h5的成分),这里的h3也是给h5-h8。
第二种形式:
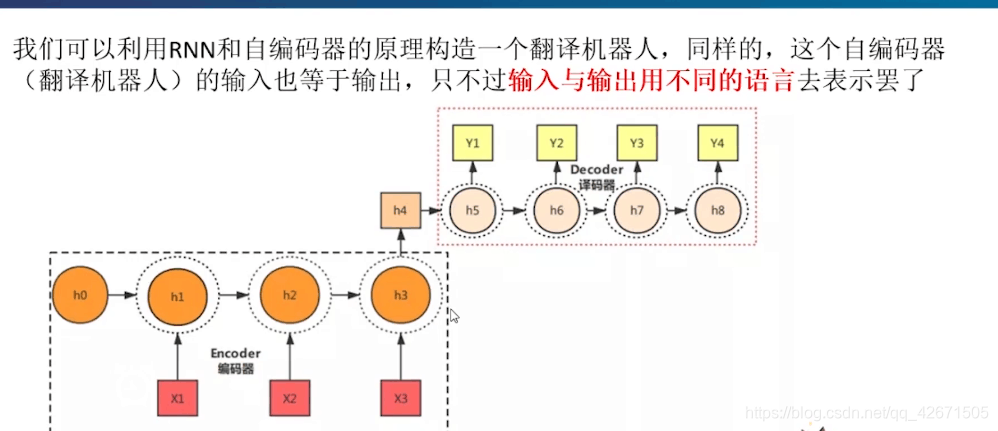
这里和上面不同的事h3全部输入给h4.
但是有一个小缺点就是,有的时候译码器的输入都是同样的,因为比如说输入了三句话(相当于三个x。有x1,x2,x3),他可能产生的中间语义c都相同。这就导致译码器收到的输入值也相同,就很有可能产生的y值也差不多,甚至一样。
所以怎么改变这种情况呢,就引入了注意力机制。
注意力机制是干啥的,就是编码器中调整权重的,每个译码器中输入的c1,c2,c3(c就是中间语义)都不相同,这样就能产生比较理想的y值了,这样说就比较清晰。
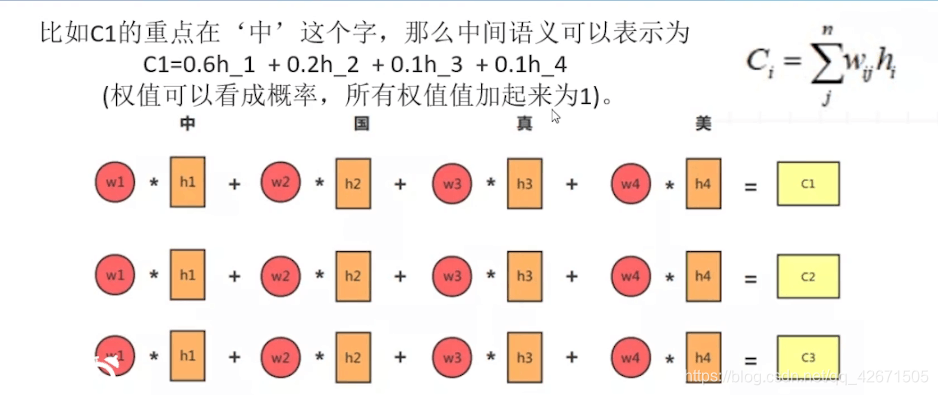
其中看那个w。0.6,0.2,0.1,0.1,反正加起来就是1.这里的w1是0.6就表示这个字是重点,因为权重比较大嘛,就加入了注意力机制。
如果要进行分类的话,要用到softmax层,这点需要看一下cnn,先不说这个了。
对Rnn不变种的总结:就是进行训练,基于梯度下降的原则去不断缩小真实值与预测值之间的差值(如果这里不明白,去百度看用代码实现线性回归的原理,就懂了)。其中还有要用到反向传播BP,所以这也是Rnn不好的地方,因为刚开始讲了(U,W,b)都是不变的,这就导致什么?比如说权值w吧,如果都是0.9或者都是1.1呢?你反向传播,这么理解吧,就是从最后的假设的值依次向前乘w找误差。如果是1.1,你乘的多了就数特别大,误差特别大吧。就没法继续进行了,这就是梯度爆炸。如果n个0.9呢?那就是梯度消失,误差也是特别大,所以为了解决这个问题引入了更好的变种:LSTM。
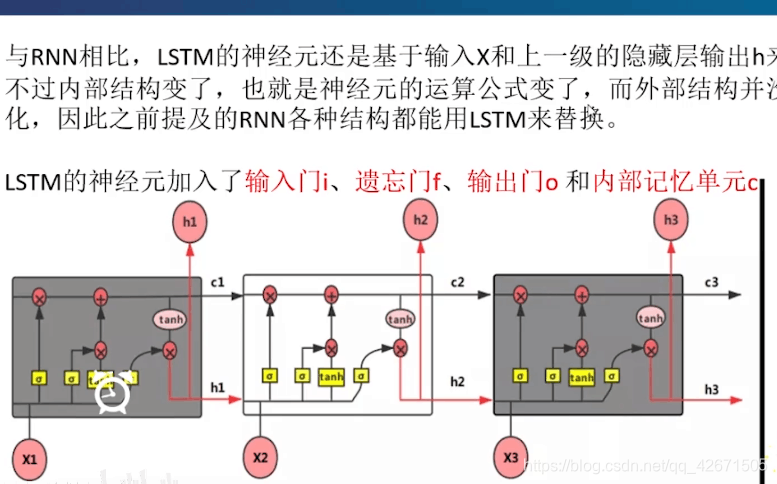
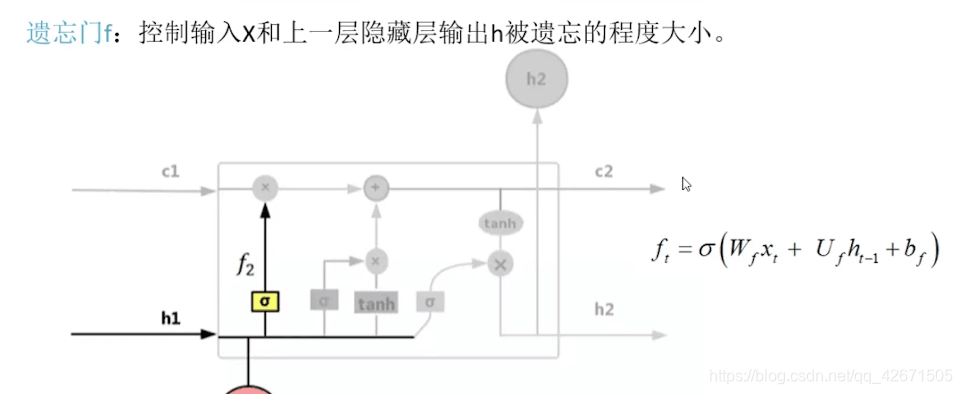
遗忘门这就很容易理解了,就是w,u,b都变了,就是根据结果不断的去改变wf,测试他的遗忘程度。
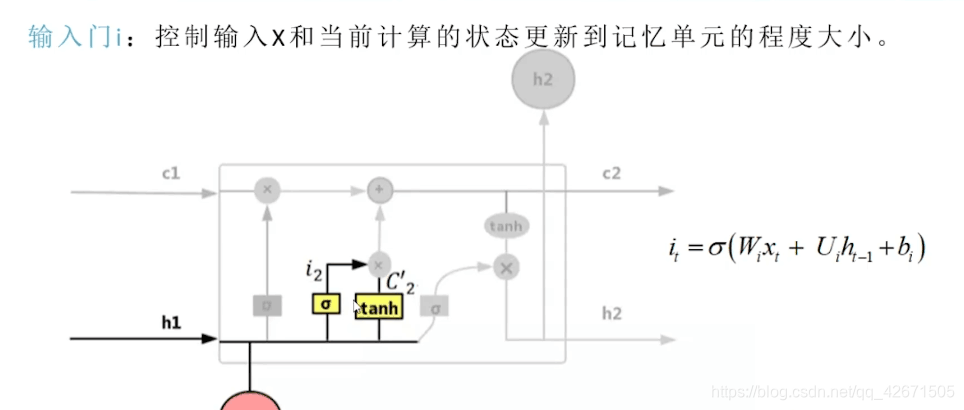
其中这个阿尔法就是一个激励函数,很多情况下选择sigmoid函数(如果不知道,百度)
就是看看这个输入值用不用得到的意思。
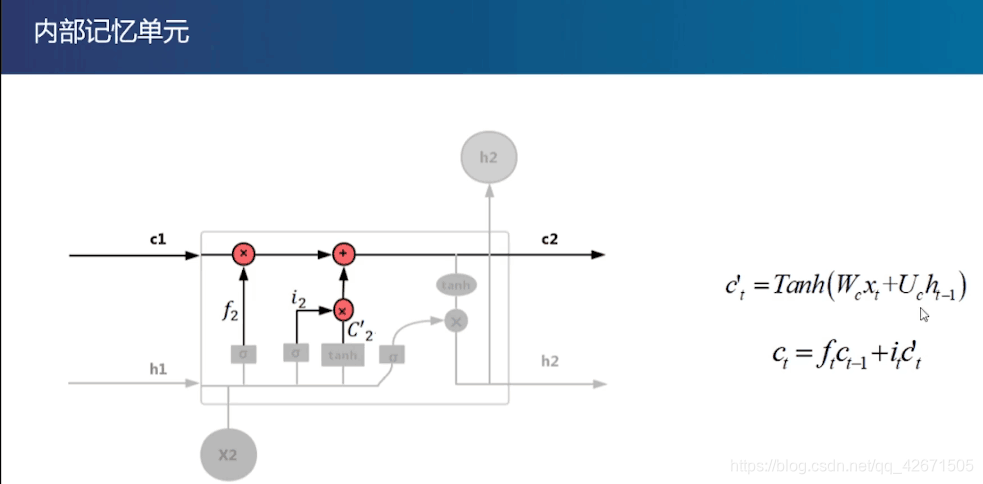
这步可以把它理解成对参数的调整(就是为了更好地拟合),数学公式ct-1,it,ft的自己看公式就能明白了。(为什么要用Tanh,分布在-1到1,满足中心分布,还不是为了拟合吗?为什么要用这个公式,前辈的经验。)
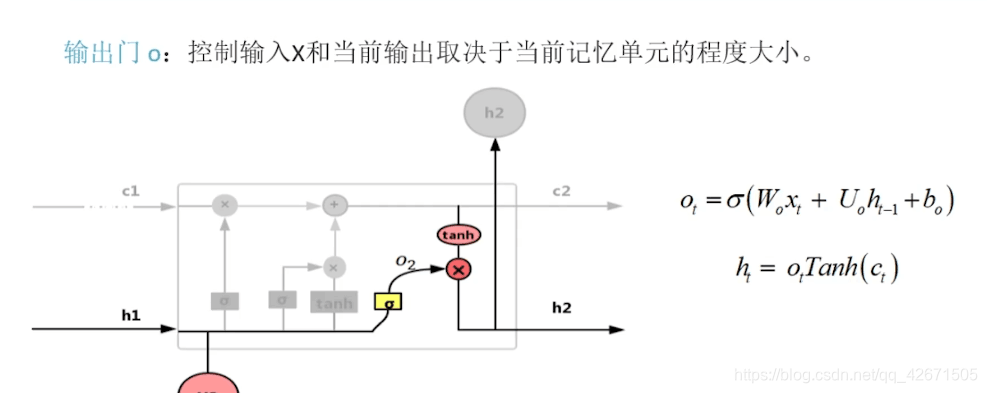
最后是一个输出门。和之前讲的Rnn原理差不多,也是需要前一个的输入值ht-1.
讲完Lstm了,就大概明白了为什么叫长短期记忆人工神经网络了。就是多添加了一些遗忘门,内部记忆单元,输入值,输出值也经过公式推导进行了处理呗。这样更符合人类大脑处理问题的思维了。