2019年9月推出时,谷歌的ALBERT语言模型在GLUE、RACE和SQuAD 2.0等流行的自然语言理解(NLU)基准上取得了SOTA结果。谷歌现在发布了一个主要的V2 ALBERT更新和开源的中国ALBERT模型。
正如全名“A Lite BERT”所示,ALBERT是该公司BERT(来自变压器的双向编码器表示)语言表示模型的精简版,该模型已成为NLU研究的支柱。论文《ALBERT:语言表示的自我监督学习的精简BERT》已被今年4月在埃塞俄比亚首都亚的斯亚贝巴举行的ICLR 2020接受。
正如Synced报告中所概述的那样,谷歌的ALBERT是一个更倾斜的BERT;在3个NLP基准上实现SOTA,类似于BERT大型的ALBERT配置的参数减少了18倍,训练速度提高了1.7倍。
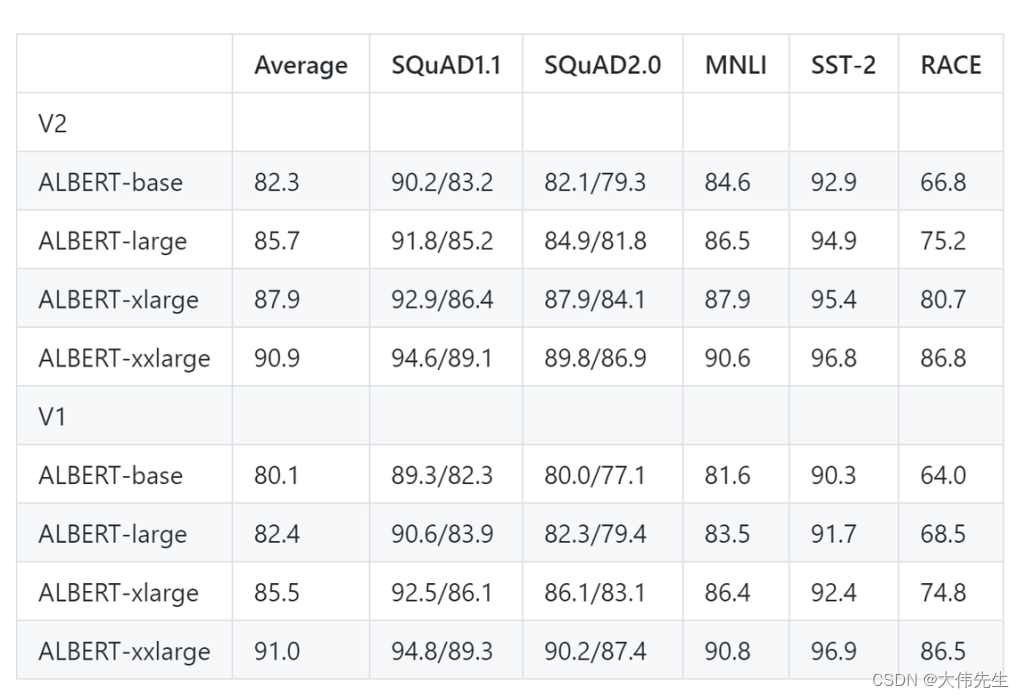
ALBERT v2模型的主要变化涉及三种新策略:无丢失、额外的训练数据和长训练时间。研究人员对ALBERT基地进行了10M步的训练,对其他模型进行了3M步的训练。结果表明,ALBERT v2的性能通常比第一个版本有显著改进。
特殊情况下,ALBERT-xxlarge v2 的性能比第一个版本略差。研究人员确定了两个可能的原因:1.额外训练150万步并没有显着提高性能;2. 对于 v1,研究人员在参数集中进行了一些超参数搜索,而对于 v2,他们采用了 v1 中的参数,但对RACE测试超参数进行了微调。“鉴于下游任务对微调超参数很敏感,我们应该小心所谓的轻微改进。
谷歌还发布了中文ALBERT模型,该模型使用来自中文语言理解评估基准(CLUE)的训练数据构建。
论文ALBERT:A Lite BERT for Self-supervised Learning of Language Representations发表在arXiv上。ALBERT models v2 GitHub