李宏毅机器学习2022课程学习笔记-L2-01overfit
概要
本节针损失值大小对应的不同情况进行讨论:
- 当Loss 值在训练集上偏大时,可从两方面进行解决:
* 增强模型的复杂度
* 改善优化函数(下一节讲) - 当Loss 值在训练集上偏小时,在测试集上Loss 值小,模型合适;
- 当Loss值在训练集上偏小,但是在测试集上偏大时:
* 过拟合 : 采集更多的训练数据集/ 数据扩展 / 简化模型
* mismatch:训练集和测试集上的数据分布不同
此外,为了使模型更好的同时适应训练集和测试集,在训练时将训练集划分为训练集合验证集
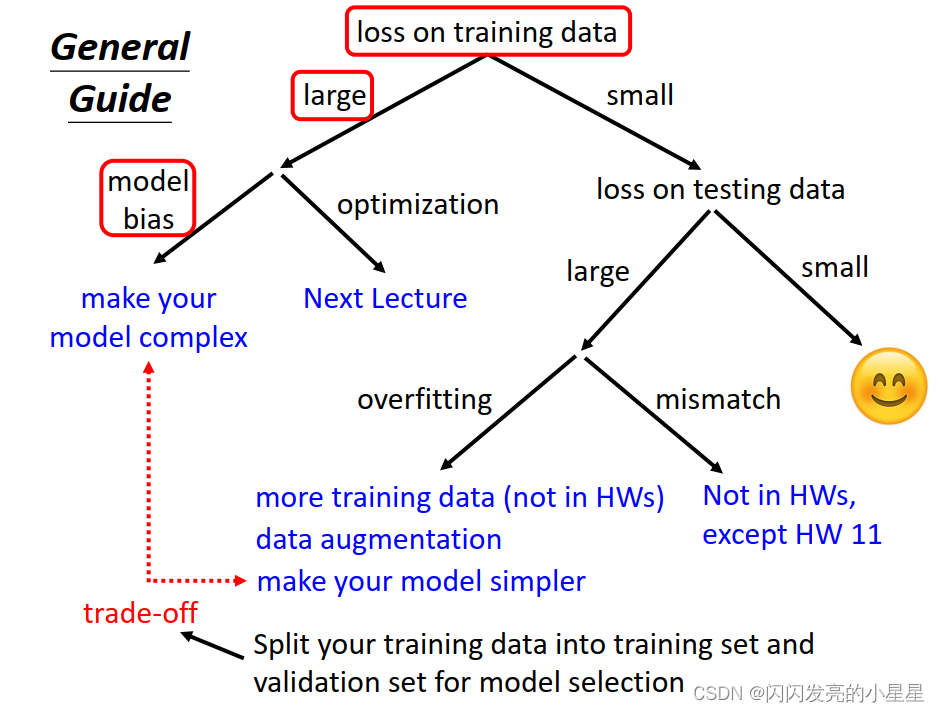
具体内容
下面对上图的各个部分进行进一步学习和介绍:
模型偏差 Model bias
问题:模型太简单,模型集合中的所有function都无法是的Loss变小;
解决办法: 重新设计模型提高模型的灵活性:
* A: 添加更多的特征
* B: DL中,增加模型层数

优化函数问题 Optimization Issue
在model 中的fuction集合中存在能使Loss 最低的fun,但是Optimization 函数无法找到该fun。
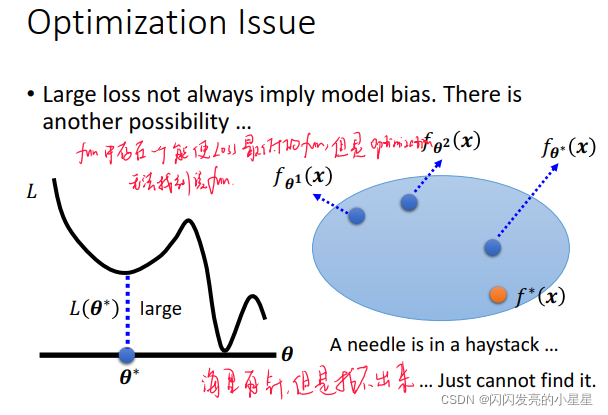
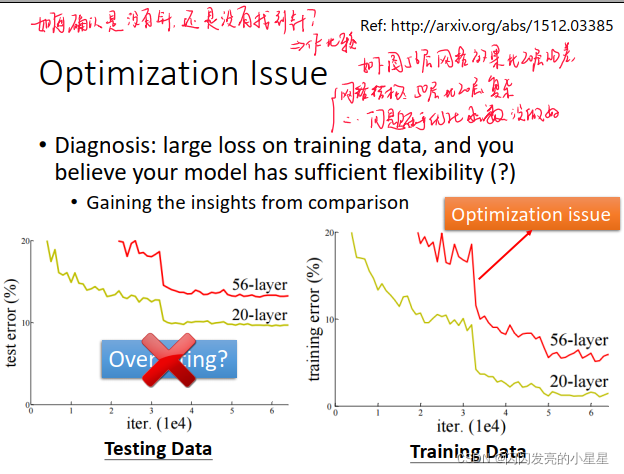
如何确认是model bias 还是 Optimization Issue?
通过比较简单模型与复杂模型的结果,如果复杂网络结果劣于简单网络,则是Optimization Issue。

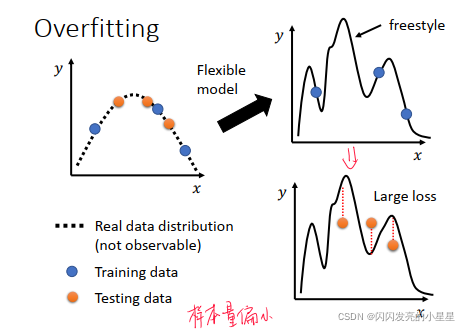
过拟合 overfitting
过拟合:在训练集上LOSS小,但是在测试集上LOSS大;
可能的原因:
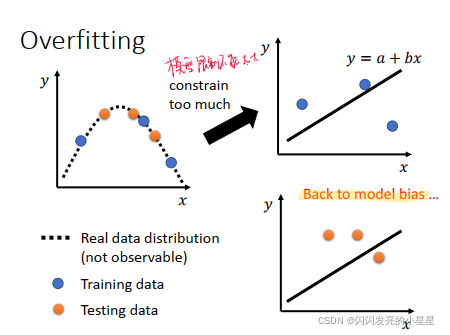
1)模型太灵活 --> 限制模型的形式,但是模型限制不能太局限,太局限的话会变成 model bias问题。
2)样本量偏小—> 收集更过的数据/ 进行数据扩展
- 过拟合的定义:

- 原因 :模型灵活性太高以及样本量偏小,
- 解决方案1:增加训练资料
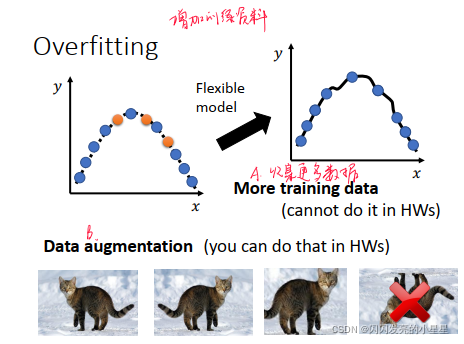
- 解决方案2:限制模型,比如使用较少的参数或者共用参数/Early spotting/Regularization/Dropout
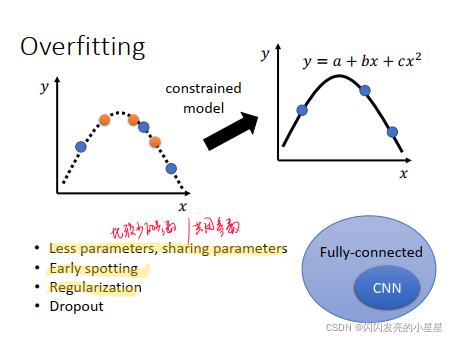
但是模型限制不能太大, 如果太大会变成Mode bias问题
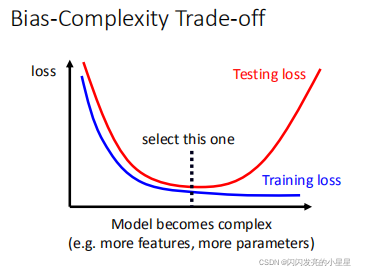
适宜的模型复杂性
模型复杂度低时,在Train和Test上的Loss 都比较高,随着模型复杂度变高,Loss都会降低,但是当模型复杂度高到一定程度时,测试集上的Loss会变高。
所以,要从中挑选合适的模型复杂度。
训练集/验证集/测试集
将训练集划分为训练集和验证集。

N折交叉验证:
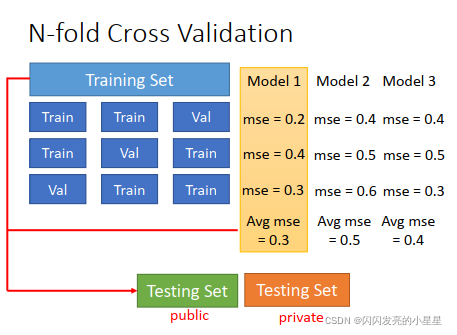
N折交叉验证有两个用途:模型评估、模型选择。
用途一: 模型选择
交叉验证最关键的作用是进行模型选择,也可以称为超参数选择。
在这种情况下,数据集需要划分成训练集、验证集、测试集三部分,训练集和验证集的划分采用N折交叉的方式。很多人会把验证集和测试集搞混,如果是这种情况,必须明确地区分验证集和测试集。
验证集是在训练过程中用于检验模型的训练情况,从而确定合适的超参数;测试集是在训练结束之后,测试模型的泛化能力。
具体的过程是,首先在训练集和验证集上对多种模型选择(超参数选择)进行验证,选出平均误差最小的模型(超参数)。选出合适的模型(超参数)后,可以把训练集和验证集合并起来,在上面重新把模型训练一遍,得到最终模型,然后再用测试集测试其泛化能力。
用途二:模型评估
交叉验证的另一个用途,就是模型是确定的,没有多个候选模型需要选,只是用交叉验证的方法来对模型的performance进行评估。
这种情况下,数据集被划分成训练集、测试集两部分,训练集和测试集的划分采用N折交叉的方式。这种情况下没有真正意义上的验证集,个人感觉这种方法叫做”交叉测试“更合理…
相比于传统的模型评估的方式(划分出固定的训练集和测试集),交叉验证的优势在于:避免由于数据集划分不合理而导致的问题,比如模型在训练集上过拟合,这种过拟合不是可能不是模型导致的,而是因为数据集划分不合理造成的。这种情况在用小规模数据集训练模型时很容易出现,所以在小规模数据集上用交叉验证的方法评估模型更有优势。
两种用途的关系
两种用途在本质上是一致的,模型评估可以看成是模型选择过程中的一个步骤:先对候选的每个模型进行评估,再选出评估表现最好的模型作为最终模型。
交叉验证的核心思想在于对数据集进行多次划分,对多次评估的结果取平均,从而消除单次划分时数据划分得不平衡而造成的不良影响。因为这种不良影响在小规模数据集上更容易出现,所以交叉验证方法在小规模数据集上更能体现出优势。
交叉验证与过拟合的关系
当用交叉验证进行模型选择时,可以从多种模型中选择出泛化能力最好的(即最不容易发生过拟合)的模型。从这个角度上讲,交叉验证是避免发生过拟合的手段。同样是解决过拟合的方法,交叉验证与正则化不同:交叉验证通过寻找最佳模型的方式来解决过拟合;而正则化则是通过约束参数的范数来解决过拟合。
当用交叉验证进行模型评估时,交叉验证不能解决过拟合问题,只能用来评估模型的performance。
总结交叉验证的使用方法
如果当前有多个候选模型,想从中选出一个最合适的模型,就可以用交叉验证的方法进行模型选择,尤其是当数据集很小时。
如果当前只有一个模型,想获得对这个模型的performance最客观的评估,就可以用交叉验证的方法进行模型评估,尤其是当数据集很小时。