前言
最近公司需要摩点的用户购买数据,比如总金额最多的有礼包

但是发现网站并没有提供下载渠道(运营和我说的,如果有不是我的锅┓(;´_`)┏)
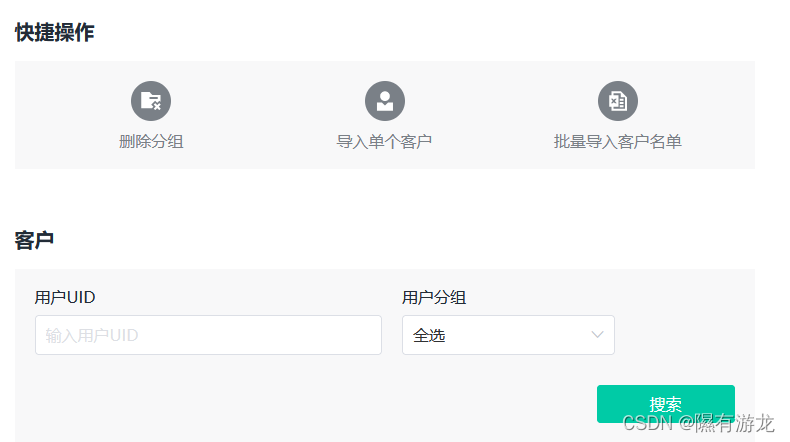
发现一个页面只有十个数据,也没有跳转,那光爬网页肯定是不行了
然后我根据写了个爬虫获取表单一直不行,发现可能是网站反爬虫程度比较高。。。
网上搜了搜发现了selenium库,以前没有用过,还挺有意思就决定用这个了
准备
基础知识还是要有,可围观大佬博客
然后我们安装一下浏览器驱动,这里用edge,这个应该都有
先看看版本
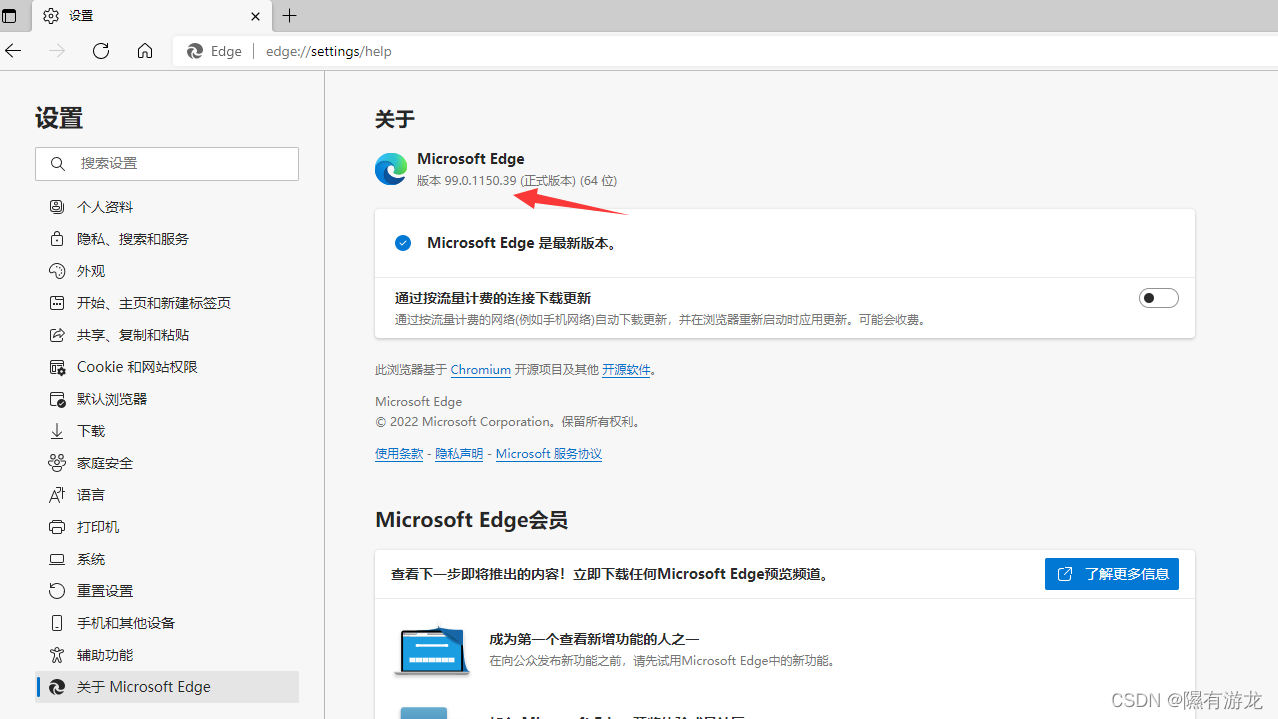
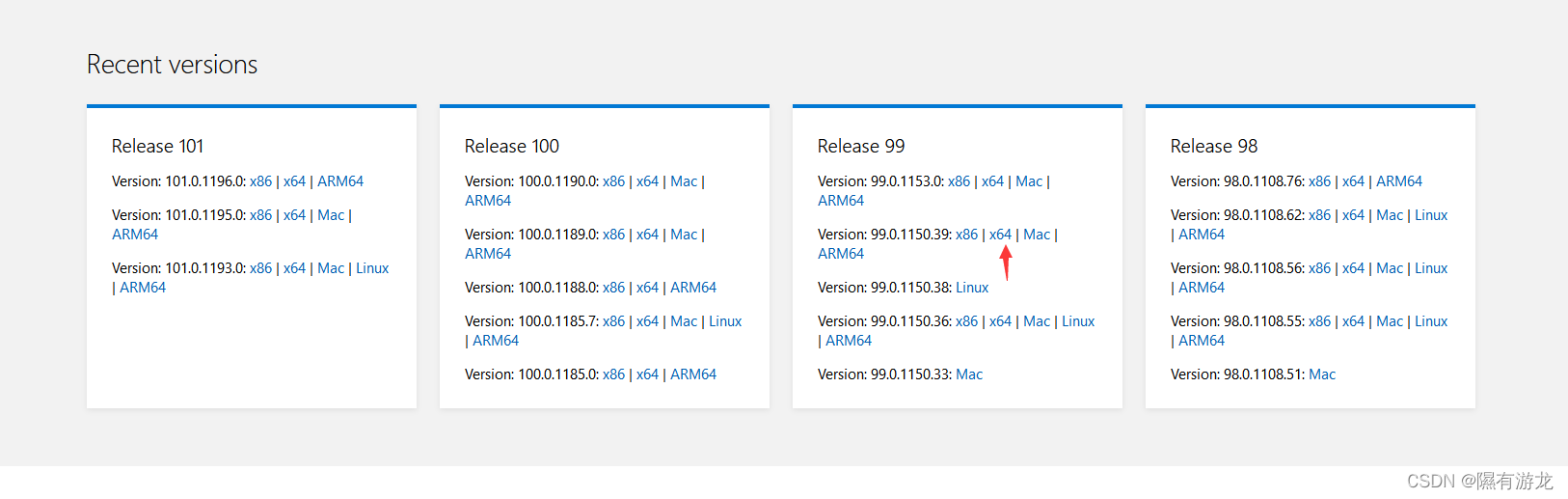
找到对应的驱动下载
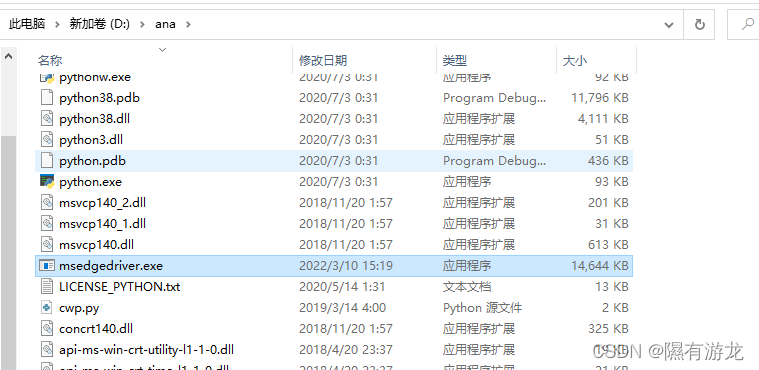
解压,放到python目录下面
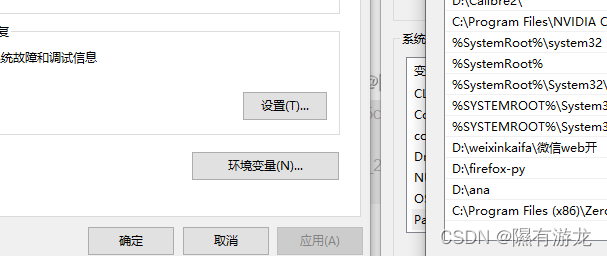
把当前路径保存到环境变量中(我的电脑>>右键属性>>高级系统设置>>高级>>环境变量>>系统变量>>Path)
但是我们跑程序会发现bug

其实只要把驱动名字改成这个报错里的就行

没有selenium库安装一下
这样准备工作就好了
1.打开网页
selenium是模拟操作,所以从打开浏览器开始
首先我们把库导入,设置一下位置
from selenium import webdriver
import time
import pandas as pd
import numpy as np
pd.set_option('display.max_rows', 50)
pd.set_option('display.max_columns', 10)
然后呢就是打开浏览器,这里就用edge了,应该都有,我们直接进入网站
driver = webdriver.Edge()
driver.get('https://me.modian.com/u/user_index')
time.sleep(1)
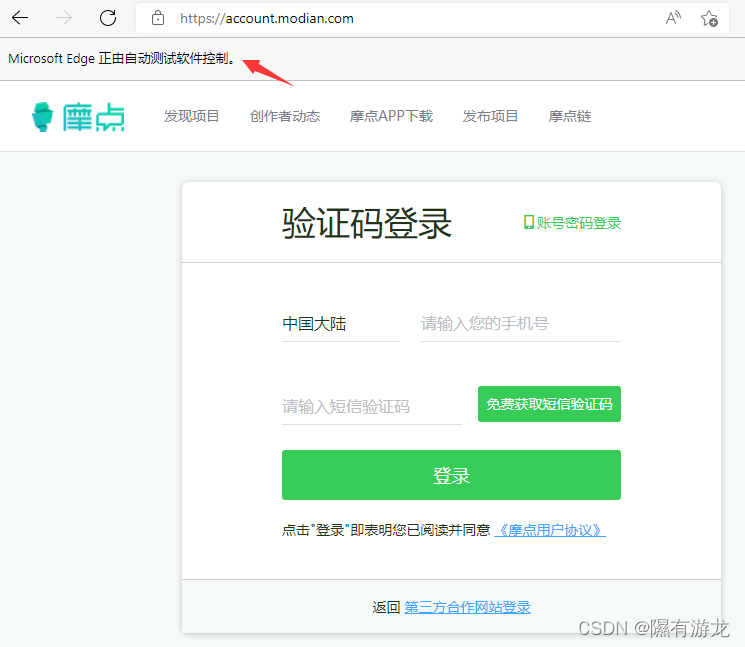
注意看显示是和平常打开浏览器不一样的
2.登录账号
由于全自动我们就需要使用账号密码,看一下这个按键位置
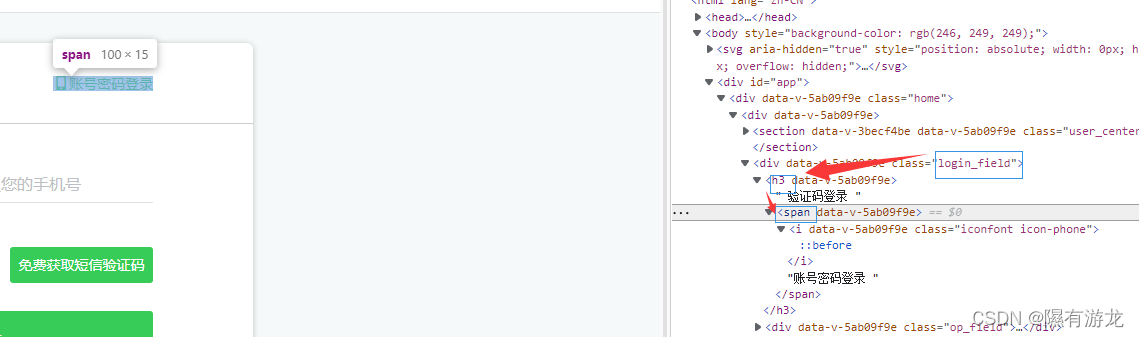
ok我们发现可以用class来定位上级标签,然后h3,最后span+点击操作
这一部分内容前面提到的博客都有说明,可以先大致看下
接下来就是定位然后点击
这里有时间间隔因为要等浏览器反应,后面同理
button1=driver.find_element_by_xpath("//*[@class='login_field']/h3/span")
time.sleep(1)
button1.click()
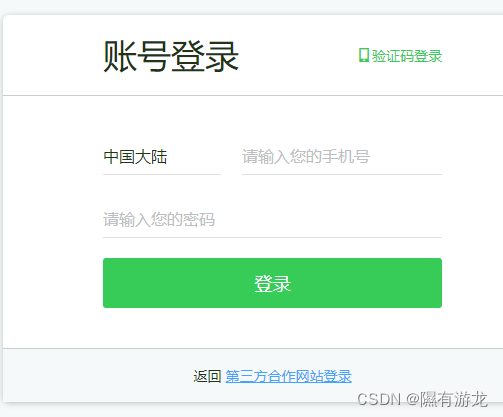
接下来就是找到两个输入框,然后登录,也就是找三个组件
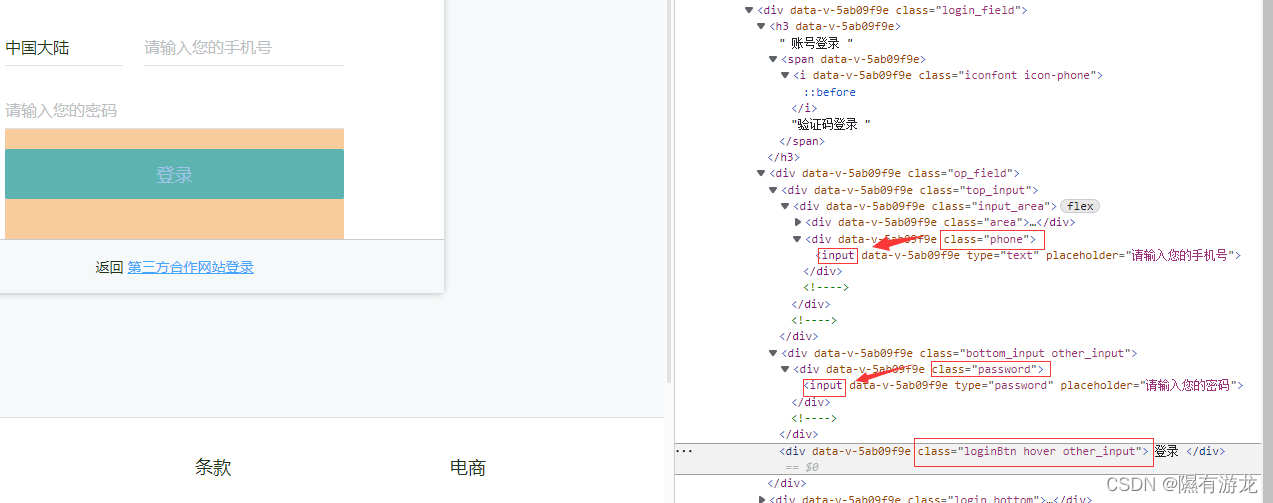
依旧通过class定位到下级,然后我们模拟两次输入一次点击(不换账号密码直接运行的给我叉出去Ψ( ̄∀ ̄)Ψ)
time.sleep(1)
driver.find_element_by_xpath("//*[@class='phone']/input").send_keys('你的账号')
driver.find_element_by_xpath("//*[@class='password']/input").send_keys('你的密码')
button2=driver.find_element_by_xpath("//*[@class='loginBtn hover other_input']")
button2.click()
现在我们进到了账号主页,但客户信息还不在这里,在这呢
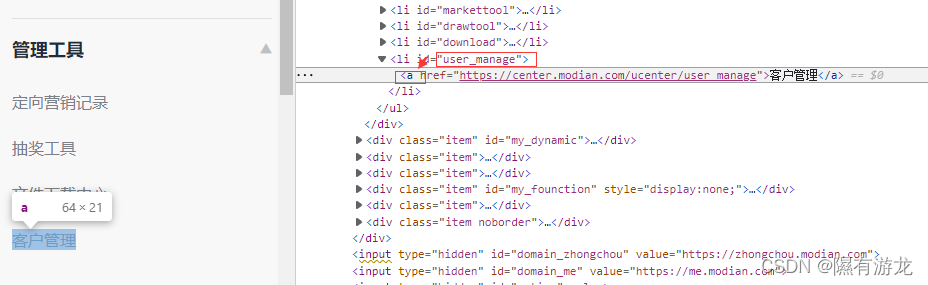
所以还需要点击一下
time.sleep(1)
driver.find_element_by_xpath("//*[@id='user_manage']/a").click()
time.sleep(1)
好的终于进入了数据页面,完美!(* ^ - ^ *)ゞ
数据读取与保存
先建一个dataframe保存数据
df = pd.DataFrame(columns = ['id','name','金额'])
num=0
然后看看数据在哪里
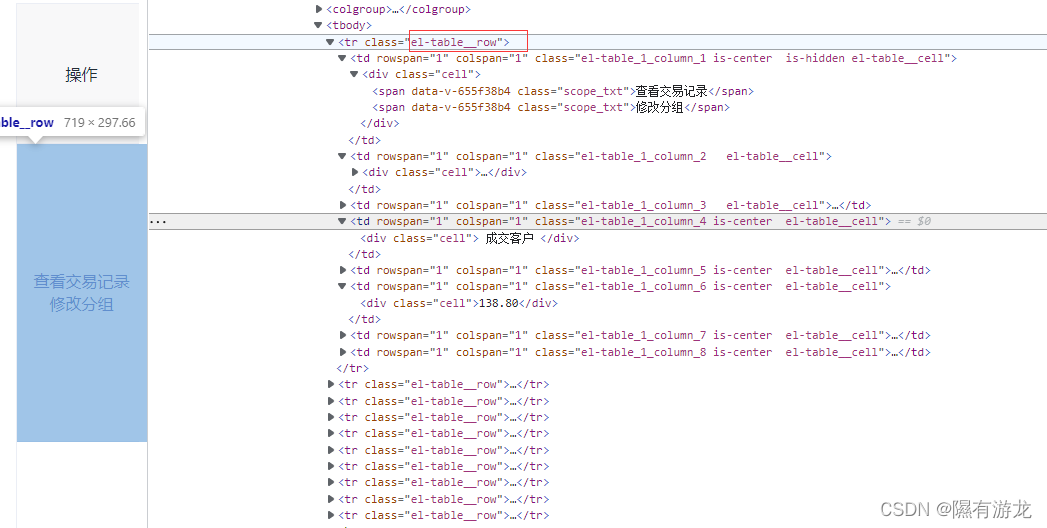
那么我们就可以根据class读取所有信息行,然后分割每一行信息
userslist = driver.find_elements_by_xpath("//tr[@class='el-table__row']")
for user in userslist:
data=user.text.split('\n')
print(data)
毕竟是公司信息,厚码了,但是还能看出是一个客户有7个信息

下一步就是挑选我们要的信息保存,把print(data)改为如下代码
注意我们不要最后的交易记录修改分组那几行,所以判定一下
if len(data) == 7 :
if data[2] == "成交客户":
df.loc[num,'id'] = data[3]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[4]
num = num+1
但是运行中可能报错,这是另有原因
在刚刚的例子中,分组都是有数据的,如果这一项空白呢?

哦豁,只有六个数据了,那按照原来的格式当然不对了,所以再加个判断
if len(data) == 6:
if data[1] == "成交客户":
df.loc[num,'id'] = data[2]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[3]
num = num+1
这样我们就可以获取一页的数据了,后面的当然要翻页了,老办法找按钮
 点他!
点他!
driver.find_element_by_xpath("//*[@class='el-icon el-icon-arrow-right']").click()
#print(df[-10:-1])
time.sleep(2)
这样就可以一页一页读了,上面这个时间如果你的网够快可以减短,不然会出现重复读取
接下来就是重复的工作了,for起来,
for i in range(1): #你的页数!!!!!!!!!!!!!!!!!!别问我怎么只有一页数据
userslist = driver.find_elements_by_xpath("//tr[@class='el-table__row']")
for user in userslist:
data=user.text.split('\n')
if len(data) == 7 :
if data[2] == "成交客户":
df.loc[num,'id'] = data[3]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[4]
num = num+1
if len(data) == 6:
if data[1] == "成交客户":
df.loc[num,'id'] = data[2]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[3]
num = num+1
driver.find_element_by_xpath("//*[@class='el-icon el-icon-arrow-right']").click()
#print(df[-10:-1])
time.sleep(2)
最后加个保存
df.to_excel(r'D:\allmoney.xlsx',index = False)
完工* \ (^ o ^) / *
完整代码
# -*- coding: utf-8 -*-
"""
Created on Wed Feb 23 19:08:35 2022
@author: xyyl
"""
# -*- coding: utf-8 -*-
"""
Spyder Editor
This is a temporary script file.
"""
from selenium import webdriver
import time
import pandas as pd
import numpy as np
pd.set_option('display.max_rows', 50)
pd.set_option('display.max_columns', 10)
#打开
driver = webdriver.Edge()
driver.get('https://me.modian.com/u/user_index')
time.sleep(1)
#定位账号密码登录
button1=driver.find_element_by_xpath("//*[@class='login_field']/h3/span")
time.sleep(1)
button1.click()
#输入账号密码
time.sleep(1)
driver.find_element_by_xpath("//*[@class='phone']/input").send_keys('你的账号')
driver.find_element_by_xpath("//*[@class='password']/input").send_keys('你的密码')
button2=driver.find_element_by_xpath("//*[@class='loginBtn hover other_input']")
button2.click()
#跳转信息
time.sleep(1)
driver.find_element_by_xpath("//*[@id='user_manage']/a").click()
time.sleep(1)
#创建dataframe
df = pd.DataFrame(columns = ['id','name','金额'])
num=0
#定位客户列表
for i in range(1): #你的页数!!!!!!!!!!!!!!!!!!别问我怎么只有一页数据
userslist = driver.find_elements_by_xpath("//tr[@class='el-table__row']")
for user in userslist:
data=user.text.split('\n')
if len(data) == 7 :
if data[2] == "成交客户":
df.loc[num,'id'] = data[3]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[4]
num = num+1
if len(data) == 6:
if data[1] == "成交客户":
df.loc[num,'id'] = data[2]
df.loc[num,'name'] = data[0]
df.loc[num,'金额'] = data[3]
num = num+1
driver.find_element_by_xpath("//*[@class='el-icon el-icon-arrow-right']").click()
#print(df[-10:-1])
time.sleep(2)
df.to_excel(r'D:\allmoney.xlsx',index = False)
效果不错,除了数据多跑的时间长,可类推类似网站
毕设要完蛋还不干正事的屑博主( ̄ω ̄;)