Kafka工作原理
常用概念
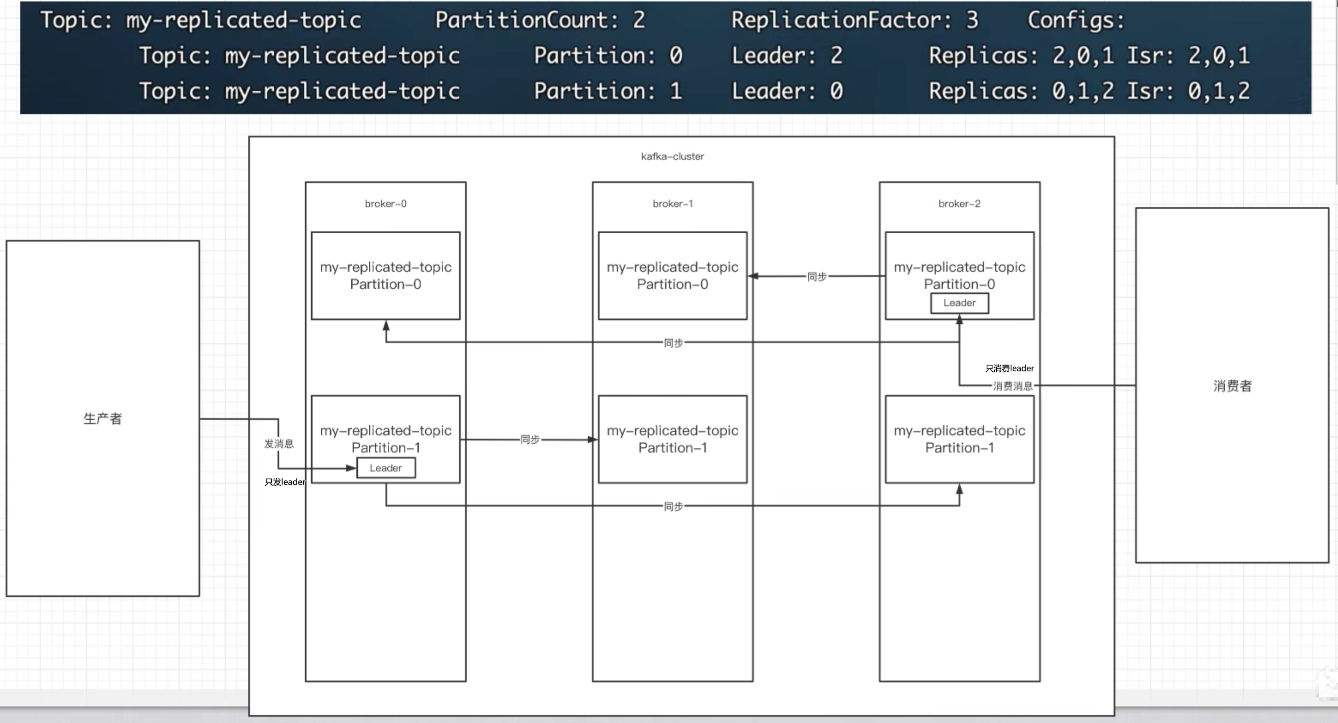
- Broker:可以理解为一个节点,一台kafka服务。
- Topic(主题):可以理解为表,一个topic可以有多个Partition分区。
- Partition(分区):可以解决一个topic消息过大的问题,例如现在有1T的消息,有了分区后,可以把1T的消息拆分成多份,例如拆分成两个512G的消息,存放到两个分区中。
- Replicas(副本):为主题中的某个分区创建多个备份,多个备份放到Kafka集群的多个broker中,会有一个副本作为leader,其他是follower。
- leader:负责kafka的读和写,负责把数据同步给follower。当leader挂了,经过主从选举,从isr的多个follwer中选举一个新的leader。
- isr:可以同步的节点以及已经同步的节点会被存入ISR集合中,注意:如果isr中的节点性能较差,会被踢出isr集合。
消费原理
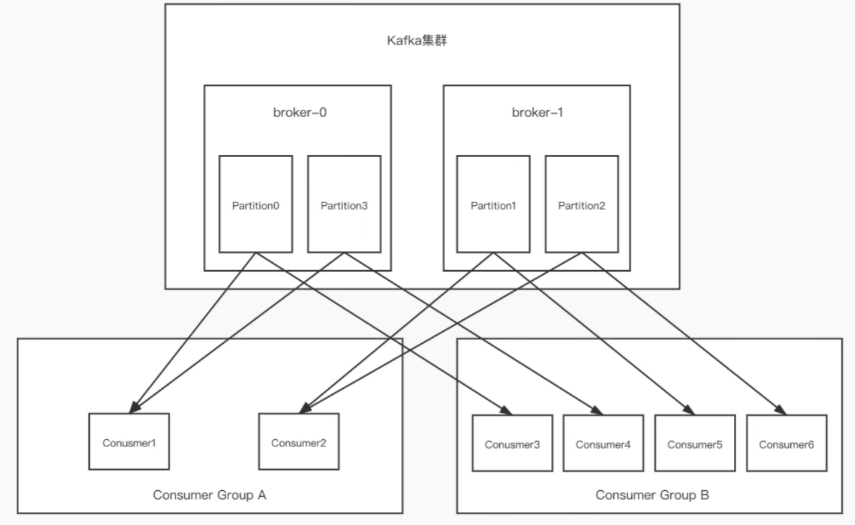
- 一个partition只能被一个消费组中的一个消费者消费,目的是为了保证消费的顺序性。但是多个partition的多个消费者消费的总顺序性是得不到保证的,那如何做到消费的总顺序性呢?
- partition的数量决定了消费组中消费者的数量,建议同一个消费组中消费者的数量,不要超过partition的数量,否则多的消费者消费不到消息。
- 如果消费者挂了,那么会触发rebalance机制,会让其他消费者来消费该分区。
生产者的ack参数配置
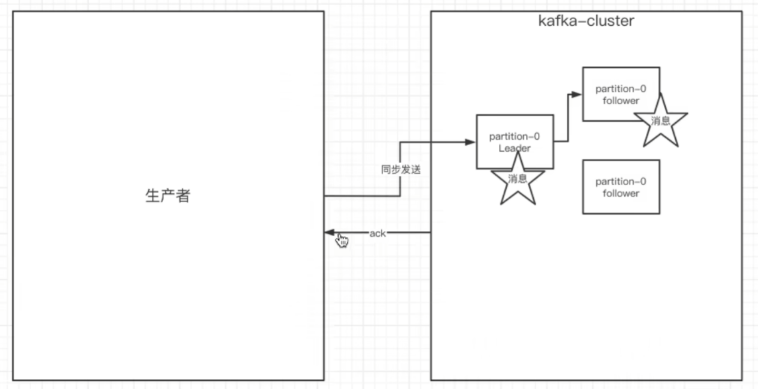
在同步发消息的场景下:生产者发送到broker上后,ack会有 3 种不同的选择:
- 1.acks=0: 表示producer不需要等待任何broker确认直接返回ack,就可以继续发送下一条消息。性能最高,但是最容易丢消息。
- 2.acks=1: 要等待leader已经成功将数据写入本地
data/log,但是不需要等待所有follower是否成功写入。就可以继续发送下一条消息。这种情况下,如果follower没有成功备份数据,而此时leader又挂掉,则消息会丢失。性能和安全性比较均衡,推荐使用。 - 3.acks=-1或all: 需要等待 min.insync.replicas(默认为 1 ,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。
发送失败retry_config会默认会重试 3 次,每次retry_backoff_ms_config会默认间隔100ms再次重试。
生产者的缓冲区机制
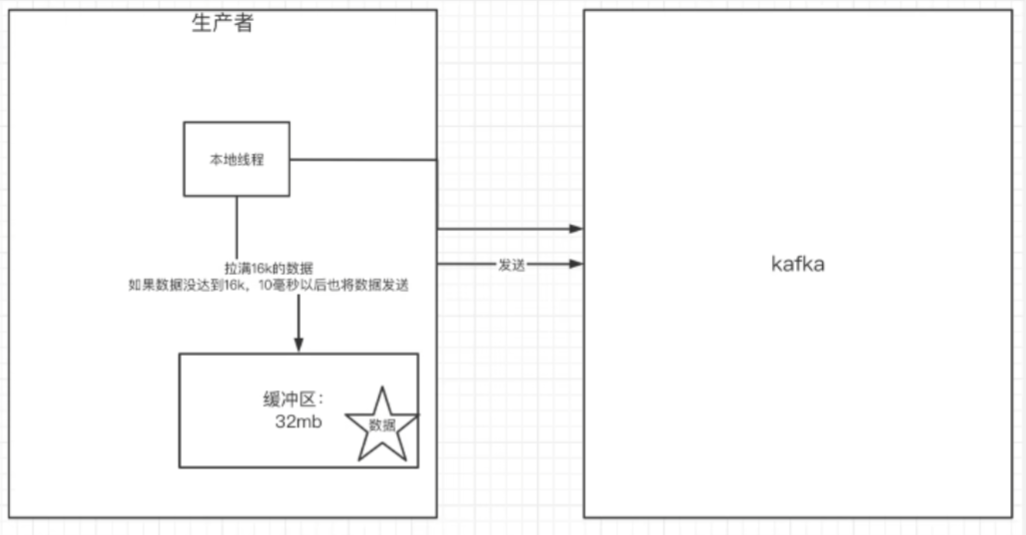
发送的消息会先进入到本地缓冲区buffer_memory_config(默认32mb),kakfa会跑一个线程,该线程去缓冲区中取满batch_size_config(默认16k,16384)的数据,发送到kafka,如果到 linger_ms_config(默认10)毫秒数据没取满16k,也会发送一次。
消费者的手动提交和自动提交
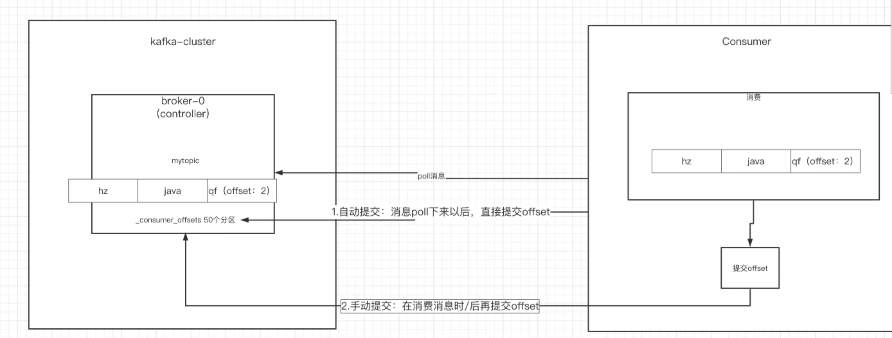
- 提交的内容
消费者无论是自动提交还是手动提交,都需要把所属的消费组+消费的某个主题+消费的某个分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题界面。 - 自动提交
# 设置自动提交参数 - 默认
// 是否自动提交offset,默认就是true
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 自动提交offset的间隔时间
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");消费者poll到消息后默认情况下,会自动向broker的_consumer_offsets主题提交当前主题-分区消费的偏移量。
自动提交会丢消息: 因为如果消费者还没消费完poll下来的消息就自动提交了偏移量,那么此 时消费者挂了,于是下一个消费者会从已提交的offset的下一个位置开始消费消息。之前未被消费的消息就丢失掉了。
3) 手动提交
# 设置手动提交参数
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");