版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lemonZhaoTao/article/details/84504862
Kafka系列文章:
Kafka系列 —— 入门及应用场景 & 部署 & 简单测试
topic & partition & replication
bin/kafka-topics.sh --create \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--replication-factor 3 --partitions 3 --topic ruozedata
针对上述创建topic的命令,进行解读:
- topic
主题,可以理解为文件夹,每个文件夹专门存放某一类数据
不同的主题针对于不同的业务线 - partition
分区, 根据创建topic的命令可以看见有3个分区
会将topic里的数据给拆分到不同的分区里面
每台机器的 /opt/software/kafka/logs 目录下,都会有对应的3个分区:

注意: 下标是从0开始的
以ruozedata-0这个分区为例,里面的内容如下(每个分区中的结构其实是一样的):

log存放数据(log大小为0是因为还没有往里写数据),index存放索引
因此我们也可以发现Kafka的数据是落在磁盘上的(是物理上的分区),默认是保留7天 - replication
副本,根据创建topic的命令可以看见有3个副本
指的是一个分区被复制3份
二维图,感官性的认识:

leader & replicas & Isr & broker

第一行列举出了topic的名称、分区数、副本数
Partition:0 & Partition:1 & Partition:2 分别对应 ruozedata-0 & ruozedata-1 & ruozedata-2
- leader
Leader:1指的是broker.id=1,即第一台机器作为partition 0的leader
后面的解释以此类推
负责读和写,读和写都是leader来干的(和传统的不同,比如MySQL主节点负责写,从节点负责读) - Replicas
指的是对应partition的副本分布在哪几台机器上
复制该分区数据的节点列表,第一位数字代表的是leader ----- 静态表述 - Isr
in-sync Replicas 正在复制的副本节点列表 ------------------------ 动态表述
当leader挂了,会从这个列表选举出新的leader
通过实验加深印象,去hadoop003机器上干掉Kafka进程,再查看:

Replicas代表的是partition的副本理应分在哪几台机器上
Isr代表的是正在将这些partition的副本给同步(或复制)到对应的机器上,但是在这个in-sync的过程中Kafka进程可能会挂,因此我们可以发现当我们kill hadoop003的kafka进程时,Isr上都少了3,而对于Partition:2,由于原来作为leader的机器上的kafka进程挂了,因此会在剩余的机器中选举出新的作为leader - broker
代表的是每台机器上面运行的Kafka的实例,说白了就是kafka的进程
从上述关于Kafka部署的章节中我们可以发现,Kafka只有一个进程,该进程就是broker,用于存储,至于生产者和消费者是其它组件做的事情
(重要)关于partition的思考
问题: 1个topic为什么要分割成多个partition?
思考: 1个topic向1个文件去读,和向10个文件去读,谁的效率高呢?
个人经验总结:
–replication-factor 3
–partitions 数量会取决于你的broker数量,也就是说取决于装了几台Kafka
生产上的参数:
–replication-factor 3 --partitions 8
设置成8个partition的原因:
- Kafka机器8个,设置成8个,满满的,一个都不浪费
- 结合Spark官网:
在direct模式下,Kafka的partition和Spark的partition是1:1的关系
因此当我们将Kafka的partition设置成8个的时候,Spark Streaming去消费的时候
读进来之后,Spark partition也为8个,因此并行度也就高了
调优的手段
适当的partition:
虽然我们增加了分区数,提高了Kafka写和读的吞吐量,但是如果过多的分区数未必好
1个集群有多个topic,必然是有多个分区,那么对于1台机器上也是会有多个topic的分区,如:ruozedata-0 、test-0、jepson-0等等(不同的topic的partition)
当我们的计算程序来进行读取的时候,linux打开文件的句柄也就需要的更多了,就需要更多的文件数、进程数,那就需要去调优了
建议:一个集群上不要有过多的topic
producer & consumer & consumer group & offset
- producer
生产者,常见的有:flume/maxwell - consumer
消费者,常见的有:Spark Streaming/flink
正常的架构:producer —> broker —> consumer(broker即我们部署的kafka)
- consumer group
正常在企业中用的不是很多
1个消费组可以包含1个或多个消费者,分区只能被1个消费组的其中1个消费者去消费
3个partition落在3台机器上,消费情况如下(图助于理解概念):
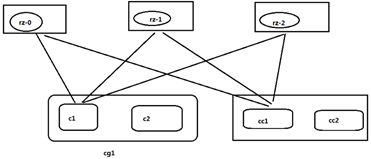
正常在企业开发使用多分区方式去提高计算的能力 - offset
偏移量:消费时读取一个分区的文件的数据,数据所在下标
后续在讲语义分析的时候会重度剖析
(重要)关于分区是否有序的思考
- 对于单个分区来说,读的数据是否有序? ==> 有序
- 对于多个分区来说,读的数据是否有序? ==> 无序
无序该怎么解决?生产上没有解决 困扰!!