转自:https://blog.csdn.net/zhangdong2012/article/details/80316882
Kafka原理
在Kafka中向topic发送消息者称为Producer,从topic获取数据者称为Consumer,Consumer被定义到一个Consumer Group中,整个Kafka集群通过Zookeeper进行协调
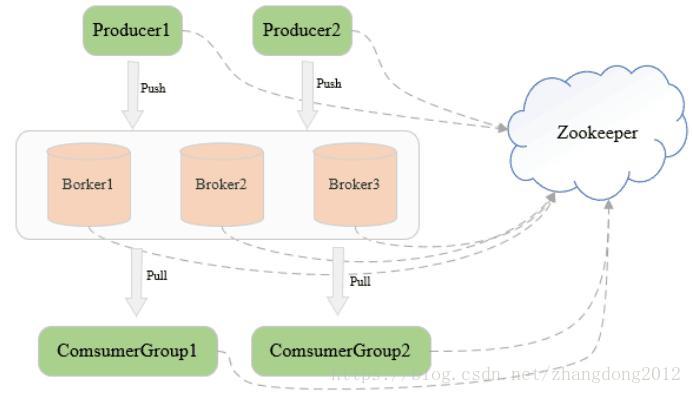
Kafka集群由多个broker实例组成,消息按照topic进行分类存储,每个topic被分为多个分区,每个分区又存在多个副本,保证数据对可用性 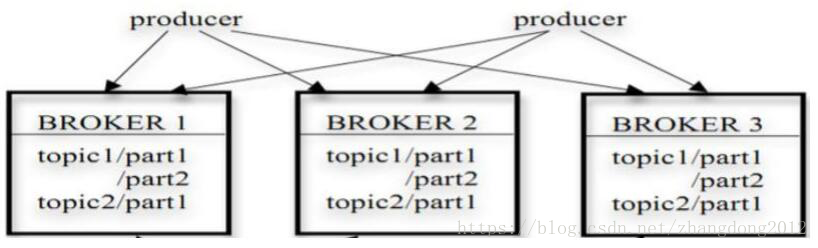
Partition内顺序存储,写入对消息采用追加的方式,消费者采用FIFO的方式进行拉去,一个topic由多个分区组成,分区内的数据有序,但kafka并不保证topic中的数据整体有序。 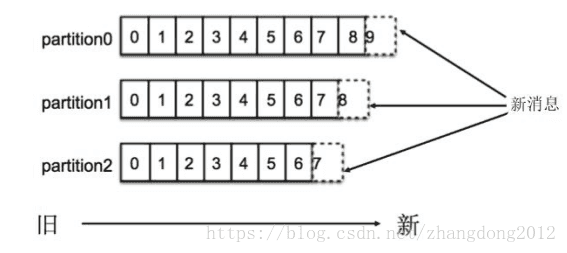
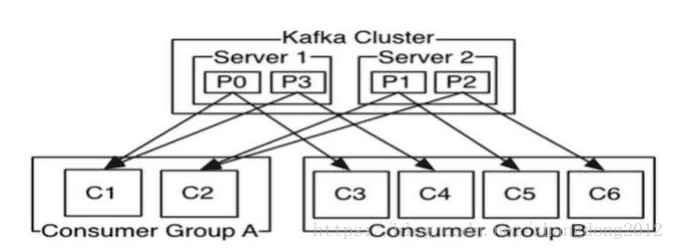
为了加快读取,多个Consumer被划分为一个Consumer Group并行的消费topic中的数据,一个topic可以由多个Consumer Group订阅,多个Conser Group之间互补影响,可以同时消费同一条数据,但组内但Consumer ,同一条消息只能被一个Consumer处理,
Kafka存储原理
Topic的每个Partition副本对应一个物理上的目录,存储当前Partition数据,Partition中的数据以Segment为单位存储,每个segment存储一段数据。
Kafka为了提高读取效率,为每个segment创建一个两个索引文件,一个以消息偏移量为依据,以.index结尾,以偏移量为名称,另一个是以消息被写入的时间戳为依据,以.timeindex结尾,以时间偏移量为名称。偏移量索引文件中稀疏存储来偏移量既索引位置,而时间索引文件中存储来时间戳偏移量和索引位置,这样可以以logn的时间复杂度快速定位到segment中的数据。
偏移量索引文件
1)以偏移量作为名称,index作为后缀
2)索引内容格式:offset,position
3)采用稀疏的存储方式
4)通过log.index.interval.bytes设置索引跨度
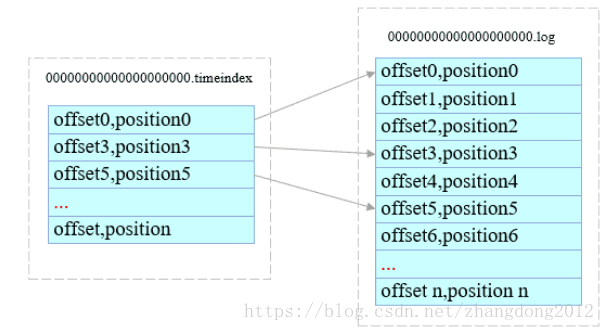
时间错索引文件
1)以时间戳作为名称,以timeindex为后缀
2)索引内容格式:timestame,offset
3)采用稀疏存储方式
4)通过log.index.interval.bytes设置索引跨度

Kafka高可用
数据高可用
1)一个topic可以又多个分区,每个分区多个副本
2)0.8版本以前分区没有副本(replication),一旦某个broker宕机,其上的partition数据便丢失
3)一个分区的多个副本选举一个leader,由leader负责读写,其他副本作为follower从leader同步数据
4)同一个partition的不同副本分布到不同的broker上
集群高可用
1)从集群中的broker选举一个broker作为Controller控制节点
2)Controller负责整个集群的管理,如broker管理,topic管理,Partition Leader选举
3)选举过程通过想Zookeeper创建临时的znode节点实现,为选中的broker监听Controller的znode,等待下次选举
Partition Leader高可用
1)Controller负责分区Leader的选举
2)Follower批量从Leader拉取数据
3)Leader跟踪与其保持同步的flower列表ISR,ISR作为下次选主的时候列表
4)Follower心跳超时时或者消息落后太多,将被移除ISR列表
5)Leader失败后,由Controller从ISR列表中选择一个Follower作为新的Leader