ABSTRACT
图相似度就是返回两个图的相似性得分,比如两个化学分子结构,相似程度怎么样?图相似度/距离计算,如图编辑距离(GED)和最大公共子图(MCS),是图相似度搜索和许多其他应用程序的核心操作,但在实际应用中计算成本非常高。
为了在保持良好性能的同时减轻计算负担。作者提出了基于神经网络的SimGNN,它结合了两种策略。首先,我们设计了一个可学习的嵌入函数,它将每个图映射到一个嵌入向量中,得到整个图的全局向量表达。提出了一种新的注意机制来强调特定相似度度量的重要节点。其次,我们设计了一种成对的节点比较方法,用细粒度的节点层信息来补充图级嵌入。模型实现了更好的泛化,在最坏的情况下,对于两个图中的节点数在二次时间内运行。
简单的说,SimGNN不仅获得好的图的信息表达,还要获得好的结点信息表达,以更好的进行图相似度比较
1 INTRODUCTION
传统的图相似度搜索方法计算时间复杂度都很高。由于神经网络计算的性质,SimGNN具有效率的关键优势。然而,为了提高有效性,我们需要仔细设计神经网络架构,以满足以下三个特性:
(1)Representation-invariant。通过排列节点的顺序,可以用不同的邻接矩阵表示。计算出的相似度得分应该对这些变化是不变的。
(2)Inductive。相似度计算应推广到不可见的图,即计算训练图对之外的图的相似度得分。
(3)Learnable。该模型应该自适应任何相似度度量,通过训练调整其参数。
为了实现这些目标,我们提出了以下两种策略。首先,我们设计了一个可学习的嵌入函数,它将每个图映射到一个嵌入向量中,它通过聚合节点级嵌入提供了一个图的全局特征表达。我们提出了一种新的注意机制,从整个图中选择特定相似度度量的重要节点。这种图级嵌入已经可以在很大程度上保持图之间的相似性。例如,如图1所示,根据地面真实相似度,图A与图Q非常相似,这可以通过嵌入反映,因为嵌入空间接近Q。此外,这种基于嵌入的相似度计算也非常快。其次,我们设计了一种成对的节点比较方法,用细粒度的节点级信息来补充图级嵌入。由于每个图中一个固定长度的嵌入可能过于粗糙,我们进一步计算两个图中节点之间的两两相似度得分,从中提取直方图特征并与图级信息相结合,以提高模型的性能。这导致了在图的大小方面的二次运算量,然而,这仍然是计算图相似度的最有效的方法之一。策略1展示了卓越的性能,当运行时间是一个主要问题时,我们可以放弃更耗时的权衡策略2

我们的贡献可以总结如下:
我们将图相似性计算作为一个学习问题,解决了一个具有挑战性的经典问题,并提出了一种基于神经网络的方法SimGNN作为解决方案。
提出了两种新的策略。首先,我们提出了一种有效的注意机制来选择图中最相关的部分来生成图级嵌入,以保持图之间的相似性。其次,我们提出了一种成对的节点比较方法来补充图级嵌入,以更有效地建模两个图之间的相似性。
我们在一个非常流行的基于三个真实网络数据集的图相似度/距离度量GED上进行了广泛的实验,以证明该方法的有效性和有效性。
2 PRELIMINARIES
2.1 Graph Edit Distance (GED)
G1和G2之间的编辑距离,用GED(G1,G2)表示,是将G1转换为G2的最优对齐中的编辑操作的数量,其中图G上的编辑操作是顶点/边的插入或删除或顶点2的重新标记。直观地说,如果两个图是相同的(同构的),它们的GED为0。图2显示了两个简单图之间的GED示例。

2.2 Graph Convolutional Networks (GCN)
正如前面的博客所说,GCN首先聚合结点,获得当前结点的特征表达,然后输入神经网络进行特征提取。


3 THE PROPOSED APPROACH: SIMGNN
SimGNN的概述如图3所示。首先,我们的模型将每个图的节点转换为一个向量,编码每个节点周围的特征和结构属性。然后,提出了两种策略来建模两个图之间的相似性,一种是基于两个图级嵌入之间的交互作用,另一种是基于比较两组节点级嵌入的策略。最后,将两种策略结合在一起,进入一个完全连接的神经网络,得到最终的相似度得分。
3.1 Strategy One: Graph-Level Embedding Interaction
该策略基于良好的图级嵌入可以编码图的结构信息和特征信息的假设,通过对两个图级嵌入的交互,可以预测两个图之间的相似性。它包括以下阶段: (1)节点嵌入阶段,将图的每个节点转换为一个向量,对其特征和结构属性进行编码;(2)图嵌入阶段,通过对前一阶段生成的节点嵌入进行基于注意力的聚合,为每个图生成一个嵌入;(3)图-图交互阶段,接收两个图级嵌入,返回表示图-图相似度的交互分数;(4)最终的图相似度分数计算阶段,进一步将交互分数降低为一个最终的相似度分数。它将与地面真实相似度评分进行比较,以更新涉及到4个阶段的参数。
3.1.1 Stage I: Node Embedding.
结点特征的提取就是通过GCN
3.1.2 Stage II: Graph Embedding: Global Context-Aware Aention.
首先就是c,c=![]() ,表示的是对所有结点进行加权而获得的全局特征。
,表示的是对所有结点进行加权而获得的全局特征。
怎么得到注意力机制呢?我们全局特征c和所有的结点的向量做内积,求和后进行sigmoid归一化。这样我们就能够反映出哪些结点的信息和全局特征最相似。

3.1.3 Stage III: Graph-Graph Interaction: Neural Tensor Network.
对于NTN,我个人的理解是这样,类似于SVD矩阵分解,svd矩阵分解中,有一个特征值组成的矩阵,通过特征值保留最重要的特征。
NTN我的理解也是一样,通过K个可学习权重矩阵,筛选出两个图的特征中最重要最能反应两个图的关系的特征,k代表我们从k个维度考虑。加入到经过特征映射的原特征中进行特征融合。

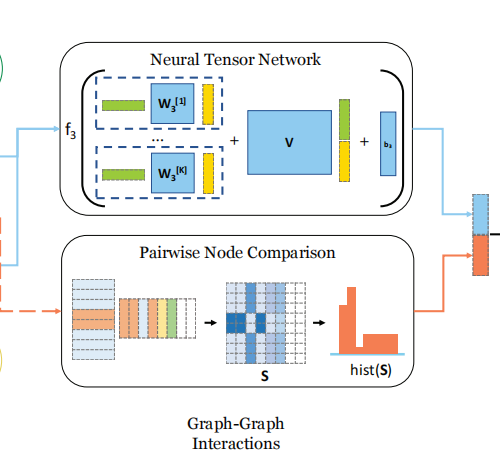
3.1.5 Limitations of Strategy One
有些图的差异在于小的结点和结构,这种全局特征可能会忽视掉
3.2 Strategy Two: Pairwise Node Comparison
我们将两个图所有的结点的向量表示都拿出来, 取N = max(N1,N2),不满N维的用0填充成N为。为了方便后面构成N*N的矩阵。分别计算两个图的两两结点之间的相似度。得到了N*N的结点相似度矩阵。对于矩阵,用直方图进行统计,反应其相似度分布。可以用直方图的频数分布组成一个向量。
最后,将全局特征和点与点之间的局部特征拼接,连接全连接层进行输出。

3.3 Time Complexity Analysis
时间复杂度包括两部分: (1)节点级和全局级嵌入计算阶段,每个图需要计算一次;(2)相似度评分计算阶段,每对图都需要进行计算。
与生成节点级和图级嵌入相关的时间复杂度为O (E) [26],其中E是图的边数。请注意,图级嵌入可以预先计算和存储,在图相似度搜索的设置中,看不见的查询图只需要处理一次就可以获得图级嵌入。
The similarity score computation stage.
策略1的时间复杂度为O(D^2K),其中D为图级嵌入的维数,K为NTN的特征映射维数。我们的策略2的时间复杂度为O(DN^2),其中N是较大的图中的节点数。通过节点采样构造相似矩阵s可以降低这一问题。
综上所述,在我们提出的两种策略中有:策略1是主要的策略,它是有效的,但仅基于粗糙的图级嵌入;策略2是辅助的,它包含细粒度的节点级信息,但更耗时。在最坏的情况下,该模型的节点数在二次时间内运行,这是最先进的近似图距离计算的算法之一。
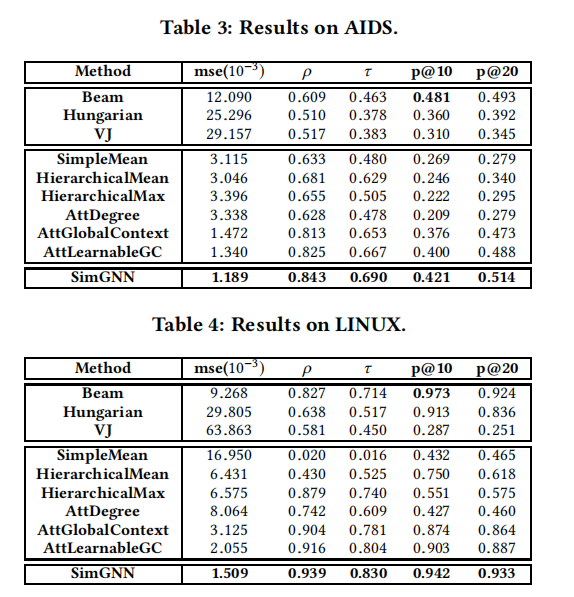
4 EXPERIMENTS
4.1 Datasets

4.6 Results