Cuboid特征提取算法
Cuboid特征检测算法是一种用于检测和表示视频中行为的通用算法。什么意思呢?就是说,对于视频里面的任意行为,不管是人的行为,动物的行为,还是机器人的行为,都可以用Cuboid特征来进行表示。所以说,这个算法的应用范围还是很广泛滴。
Cuboid特征是一种时空特征( Spatio-temporal Feature),它将图片的空间检测算子扩展到了视频的时空检测算子。我们把视频看成是由一张张图像组成的序列,那么对于视频中的任意一点,我们都可以用(x,y,t)来表示,从而我们就可以把视频视为一种三维数据。时空特征点就是从这样的三维数据中提取出的兴趣点。

图 1 将视频看成一种三维数据示意图
优点:对周期性运动的物体,或是有着显著运动特征的物体,检测效果好,且检测出来的特征点数目非常多。
缺点:如果物体做平移运动,或者运动特征不明显,则检测的特征点数目很少。
Cuboid特征提取过程
Cuboid特征提取可分为特征检测,生成Cuboid,生成Cuboid原型,生成最终行为描述子,这4个过程。
特征检测(Feature Detection)
和许多兴趣点检测算法一样,Cuboid的响应函数是通过应用可分离的线性滤波器(Separable Linear Filters)来进行计算的。
前提假设:
假设摄像头是静止的,或者摄像头运动但是其运动过程是可描述的。
响应函数:
R=(I∗g∗hev)2+(I∗g∗hod)2
其中
g(x,y;σ)=12πσ2e−(x2+y2)2σ2
hev(t;τ,ω)=−cos(2πtω)e−t2τ2
hod(t;τ,ω)=−sin(2πtω)e−t2τ2
ω=4τ g(x,y;σ) 是应用在空间域上的二维高斯平滑函数,hev 和hod 是应用于时间维上的互相正交的一维Gabor滤波器,用来探测具有周期运动的成分。
我们取响应函数的局部最大值(极值)的点作为兴趣点,即采用了非最大抑制法来寻找兴趣点。
此处或许大家会跟我一样有一个疑惑,只要是响应函数的极值点就把它作为兴趣点吗?答案是:Yes。没错,要是有500个极值点,我就取500个兴趣点;要是有1000个极值点,我就取1000个兴趣点,就是那么任性。因此,可能就会产生这样的结果,我对三个不同的视频应用响应函数来提取特征点,三个视频提取出的特征点个数都是不一样的。很神奇吧,居然还有这样的操作。生成Cuboid
好啦,经过上一步,我们已经拿到了很多个特征点,比如说是666个吧。接下来呢,我们就要把这666个特征点变成666个cuboid,即
特征点→Cuboid
首先呢,每一个特征点取一个cuboid块儿,以特征点为中心,长宽高分别为(x,y,t)=(2[3σ]+1,2[3σ]+1,2[3τ]+1) 。那么cuboid长什么样子呢?多说废话不如上图。
图 2 基于cuboid的行为识别可视化算法示意图
图1里上面那一大块儿就是一段仓鼠吃东西的视频。经过特征检测,我们从这段视频里面检测出来18个特征点。我们把每一个特征点变成一个cuboid,也就是图1下半部分的那些小块儿,我们用这些小块儿来进行行为分析。
为了能够比较cuboid之间的相似度,在进行下一步之前,我们还需要对这些小块儿进行一些处理,将cuboid转化为向量。
首先,对cuboid做变换。 Cuboid的提出者采用了三种变换方式:归一化像素值,亮度梯度,引入窗口光流。
然后,将变换后的cuboid转化为向量。同样的,提出者也采用了三种方式:直接将Cuboid拉直为一个向量,全局直方图和局部直方图。
(经过测试比较,发现直接用cuboid求亮度梯度得到特征向量的分类误差最小。)
最后,用PCA进行降维。到目前为止,我们得到的特征向量维度非常的大,为了减少最终描述子(也就是特征向量)的维数,我们需要使用PCA来进行降维。
我们在提取的cuboids里,随机选取一定数目的 cuboids 特征向量,然后进行 PCA 降维,取特征值最大的前 K 个主成分(实际上就是提取了 k 个basis)。然后将每个 cuboids 投影到这些基上,构成了 K × 1 的 cuboid 特征描述子。这种描述子可看成了 PCA-SIFT 描述子的推广。
好,那现在每一个cuboid都变成了K × 1的特征向量(特征描述子)。生成Cuboid原型(Cuboid Prototypes)
在上一步我们得到了一堆Cuboid特征描述子,虽然这些描述子可能互相不相同,但冥冥之中,它们可能是同一种描述子。什么意思呢?举个栗子,假如我们都是一个Cuboid特征描述子,你跟我,我跟他长得都不一样吧,我们是不一样的描述子,但是呢,从本质上来说,我们是一样的,我们都属于人种对吧,也就是说我们这些描述子都属于同一个Cuboid原型。
当不同人做同一种动作时,尽管其表观和运动有所不同,但是检测到的兴趣点应该是相似的。所以尽管可能的cuboid的数目很多,但cuboid的类型的很少。所以在动作识别领域,cuboid的精确构成不是很重要,重要的是要检测出cuboid的类型,即cuboid prototypes。
因此,在得到大量的Cuboid特征描述子后,我们将其进行k-means聚类,聚类中心即为Cuboid原型,从而形成Cuboid 原型字典库。- 生成行为描述子(Behavior Descriptor)
有了 Cuboid 原型库,接下来我们要提取行为描述子作为一个视频序列的特征向量。
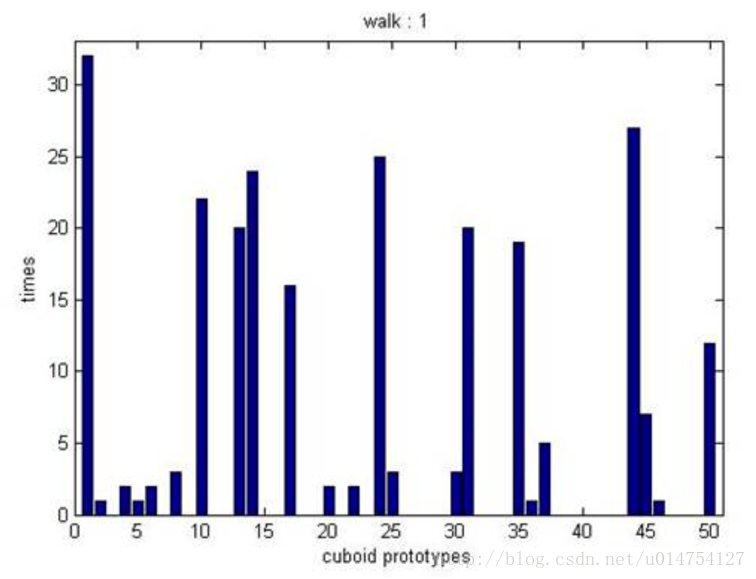
这个采用的方法是用Cuboid原型的直方图表示,如图3所示。一个视频的兴趣点对应的Cuboids属于某个Cuboid prototype的个数构成的向量。横轴是Cuboid原型,图3上是50个Cuboid原型,纵轴就是属于这个原型的Cuboid的个数。这个直方图呢,我们用一个向量来表示,图3的直方图,我们就用一个50*1的向量,向量里的第1个元素的值就是属于原型1的Cuboid的个数,以此类推。
图 3 Cuboid原型直方图
经过特征检测,生成Cuboid,生成Cuboid原型,生成最终行为描述子这4个过程,每一个视频我们最终都得到了一个行为描述子。接下来,我们就只要把这些行为描述子扔到分类器里面去做分类就可以啦,比如简单的KNN,稍微复杂点的SVM等等。

ps: 后面写的比较糙,有时间再详细把每一块儿扩充一下。
本文参考了tornadomeet的文章,链接为
http://www.cnblogs.com/tornadomeet/archive/2012/05/10/2495212.html