损失函数的作用
损失函数是用来度量模型的预测值与真实值之间差异的函数,它是一个非负实值函数,且应该处处可导。
在模型的训练阶段,通过前向传播得到模型的预测值,此时使用损失函数得到预测值和真实值之间的差异,然后利用反向传播得到所有权重参数对偏差的梯度,采用优化函数更新梯度,使得预测值进一步靠近真实值,从而达到学习的目的。
从熵的角度分析交叉熵
由于人为标注数据的真实分布与模型的预测分布的概率模型可能不一致,因此需要一个统一的体系来定量评估每个模型,具体采用的就是熵。熵是信息论中的概念,想要理解熵如何评估两个概率模型(系统)之间的差异,需要先了解以下一些概念。
信息量
信息量的基本思想是事件从不确定到确定的难易程度,事件发生的概率越小,携带的信息量越大。
假设X是一个离散型的随机变量,其取值集合为 ,则定义事件
,则定义事件 的信息量为:
的信息量为:
其中, 是变量
是变量 取值为
取值为 的概率,取值范围为[0, 1],由于事件发生概率越小,信息量越大,所以常数因子为-1,这样当概率
的概率,取值范围为[0, 1],由于事件发生概率越小,信息量越大,所以常数因子为-1,这样当概率 趋向于0时,信息量趋近于无穷,概率
趋向于0时,信息量趋近于无穷,概率 趋向于1时,信息量趋近于0。
趋向于1时,信息量趋近于0。
信息熵
信息熵也叫熵,用来表示系统中所有信息量的期望。在一个系统中,熵越大,代表这个系统的不确定性越高,混乱程度越大。熵的表达式如下:
为了进一步加深对熵的理解,我们以球队夺冠为例,以下分别展示了两个概率系统,第一个每只球队夺冠的概率是相同的,第二个每只球队夺冠的概率并不相等。从下图可以看出,熵的值为系统中所有事件发生的概率乘以对应的信息量的总和。
KL散度
如果同一随机变量 有两个独立的概率分布
有两个独立的概率分布 和
和 ,则可以使用KL散度来衡量两个分布的差异。
,则可以使用KL散度来衡量两个分布的差异。
在机器学习中,常常使用 来表示样本的真实分布,
来表示样本的真实分布, 来表示模型的预测分布。KL散度越小,表示
来表示模型的预测分布。KL散度越小,表示 和
和 越接近,可以通过训练,更新参数来使得
越接近,可以通过训练,更新参数来使得 无限逼近
无限逼近 。KL散度的计算公式如下:
。KL散度的计算公式如下:
KL散度具有如下两个性质:
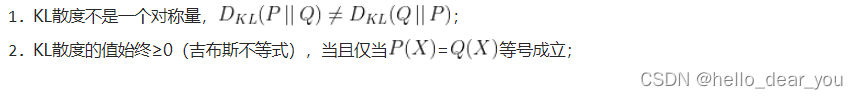
交叉熵
将上述的KL散度公式进一步简化:
前者H(p(xi))是真实分布的信息熵,后者为交叉熵。所以KL散度=交叉熵-信息熵,即交叉熵等于:
在模型的训练阶段,输入数据和标签常常已经确定,那么真实概率分布P(X)是确定,所以信息熵在这里是一个常量。
由于KL散度的值表示真实概率分布P(x)与预测概率分布Q(x)之间的差异,值越小表示两个分布之间的差异性越小,所以目标变成最小化KL散度。但是由于交叉熵等于KL散度加上一个常量,且公式相比KL散度更加容易,因此最小化KL散度与最小化交叉熵的效果是一致的,且优化交叉熵的计算量小于优化KL散度。
交叉熵损失函数
交叉熵是信息论中的一个概念,与事件的概率分布密切相关。因此在使用交叉熵损失函数之前需要先使用softmax或者sigmoid将模型的输出转换为概率值。但是何时使用softmax,何时使用sigmoid需要分如下两种情况讨论:
单标签分类任务
单标签分类任务,指的是每个输入样本中,只包含一个类别的目标,比如ImageNet、Cifar、MNIST等数据集的分类任务。
如下图所示,以MNIST手写数据识别数据集的分类任务为例,讲解损失的具体计算流程:
假设样本的数字为“1”,那么真实分布应该为:
[1, 0,0,0,0,0,0,0,0,0]
,如果网络的输出分布为:
[7, 1, 4, 3, 4, 2, 1, 4, 5, 2]
,然后将其送入到softmax中,得到输出的概率分布为:
[0.7567, 0.0019, 0.0377, 0.0139, 0.0377, 0.0051, 0.0019, 0.0377,
0.1024, 0.0051]
softmax输出的概率表示样本中包含每个类别的概率,每个类别出现的不是相互独立的,因此所有类别出现的概率值总和为1。
对于单标签的单个样本,假设真实分布为 ,网络输出分布为
,网络输出分布为 ,总的类别数为
,总的类别数为 ,则交叉熵损失函数的计算公式如下:
,则交叉熵损失函数的计算公式如下:
因此,在这个例子中,计算损失函数为:

因此,对于一个batch,单标签n分类任务的交叉熵损失函数为:
多标签分类任务
多标签分类任务,即一个样本中包含多个标签,即多种不同类别的目标。比如VOC、COCO等数据集中样本中都包含多个不同类别的目标。与单标签分类任务使用softmax不同,在多标签分类任务中使用sigmoid函数将网络的输出转换为概率,表示图像中包含该类物体的概率。但是,对于多标签分类任务,每一类是相互独立的,所以网络最后输出的概率值总和不一定等于1.
在多标签分类任务中,如果将每一类都单独分析的话,真实分布 是一个0-1分布,而模型预测分布
是一个0-1分布,而模型预测分布 可以理解为标签为1的概率。因此,对于多标签单个样本,假设真实分布为
可以理解为标签为1的概率。因此,对于多标签单个样本,假设真实分布为 ,网络输出分布为
,网络输出分布为 ,总的类别数为
,总的类别数为 ,则交叉熵损失函数的计算公式如下:
,则交叉熵损失函数的计算公式如下:
因此,对于一个batch,多标签n分类任务的交叉熵损失函数为:
从似然函数的角度分析多标签分类任务的损失函数
从上面的介绍,我们知道每个神经元的输出值,经过sigmoid函数转换为概率,表示该图像中包含该类物体的概率,每个类别的预测是相互独立的。
在多标签单个样本中,如果对每个类别进行独立分析,则每个类别都是一个二分类任务,真实分布 是一个0-1分布(伯努利分布)。因此,我们可以得出如下公式:
是一个0-1分布(伯努利分布)。因此,我们可以得出如下公式:
将上述两种情况合并,得到:
同时,由于每个类别的预测是独立同分布的,因此,得到似然函数如下:
对似然函数取对数,然后加负号,即变成最小化对数似然,也即单个样本的交叉熵损失函数形式如下: