sigmoid函数求导:
https://blog.csdn.net/u012421852/article/details/79614417
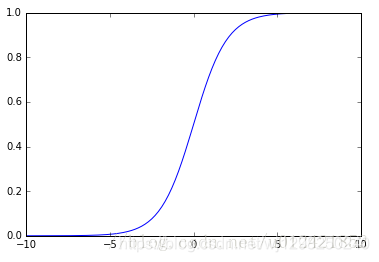
通过logistic曲线就可以知道
1)sigmoid函数是一个阀值函数,不管x取什么值,对应的sigmoid函数值总是0<sigmoid(x)<1。
2)sigmoid函数严格单调递增,而且其反函数也单调递增
3)sigmoid函数连续
4)sigmoid函数光滑
5)sigmoid函数关于点(0, 0.5)对称
6)sigmoid函数的导数是以它本身为因变量的函数,即f(x)’ = F(f(x))
所以sigmoid函数其实起源于生物学的现象中,其曲线也称为**S型生长曲线。
**在信息科学中,由于sigmoid函数和其反函数都是严格单调递增的,所以sigmoid函数常被用作神经网络的阈值函数,将变量映射到(0,1)内。
推导过程:

损失函数:
常见损失函数
https://blog.csdn.net/bitcarmanlee/article/details/51165444
在逻辑回归的推导中,我们假设样本是服从伯努利分布(0-1分布)的,然后求得满足该分布的似然函数,最终求该似然函数的极大值。整体的思想就是**求极大似然函数的思想*,这时误差函数最小*。
而取对数,只是为了方便我们的在求MLE(Maximum Likelihood Estimation)过程中采取的一种数学手段而已。

逻辑回归中,采用的则是对数损失函数。如果损失函数越小,表示模型越好
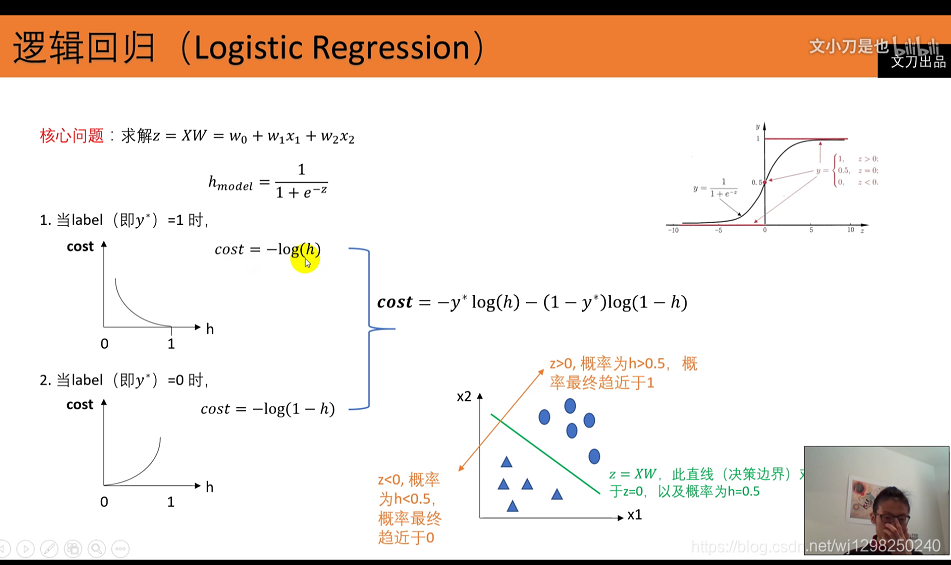

使用梯度下降求解
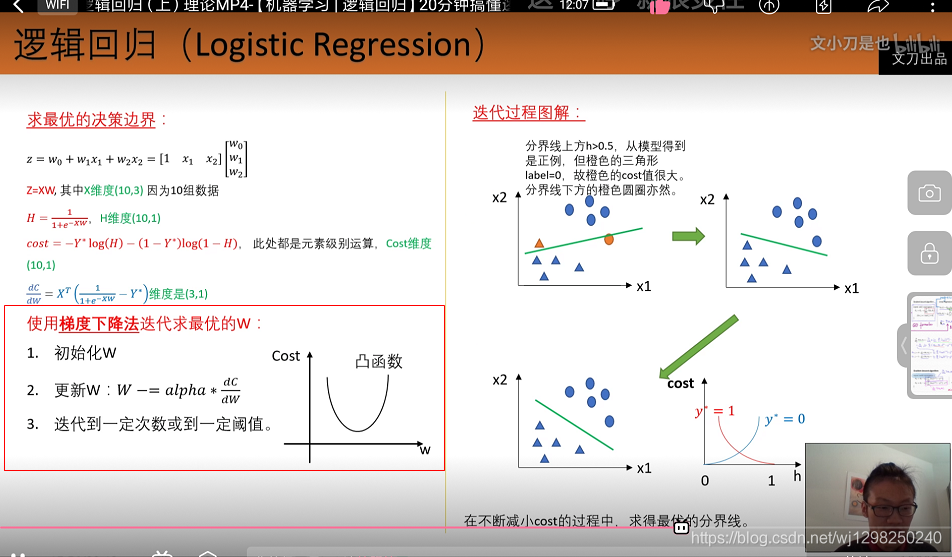
**

为什么用交叉熵做损失函数
毕竟越好的模型预测的应该越准确嘛。
但这里却没用最小二乘作为损失函数,为什么呢?
因为线性回归是回归问题,而逻辑回归虽然叫逻辑回归,实则确实分类问题。类别变量不同于连续变量,连续变量可以用差距衡量模型的好坏,分类问题却只是用数值代表类别,数值本身确实无意义的,比如用{0,1}表示的类别,用{1,2}也同样能够表示。
经过学习我们知道,类别问题更应该用概率分布的角度衡量预测出的类别与真实类别的差距。
https://blog.csdn.net/huwenxing0801/article/details/82791879
