1 VGGNet介绍
VGGNet是牛津大学视觉几何组(Visual Geometry Group)提出的模型,故简称VGGNet, 该模型在2014年的ILSVRC中取得了分类任务第二、定位任务第一的优异成绩。该模型证明了增加网络的深度能够在一定程度上影响网络最终的性能。
论文地址:原文链接
根据卷积核大小与卷积层数目不同,VGG可以分为6种子模型,分别是A、A-LRN、B、C、D、E,分别对应的模型为VGG11、VGG11-LRN(第一层采用LRN)、VGG13、VGG16-1、VGG16-3和VGG19。不同的后缀代表不不同的网络层数。VGG16-1表示后三组卷积块中最后一层卷积采用卷积核尺寸为1*1,VGG16-3为3*3。VGG19位后三组每组多一层卷积,VGG19为3*3的卷积。我们常看到的基本是D、E这两种模型,官方给出的6种结构图如下:
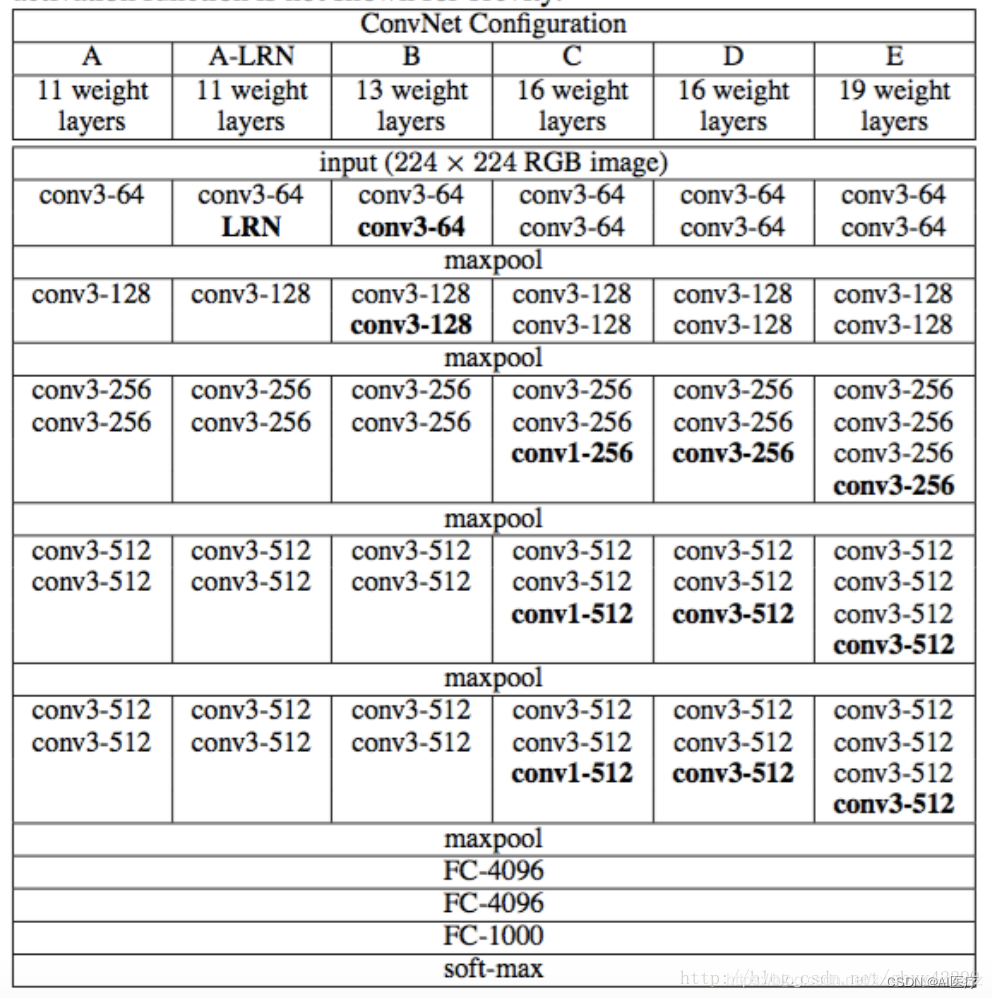
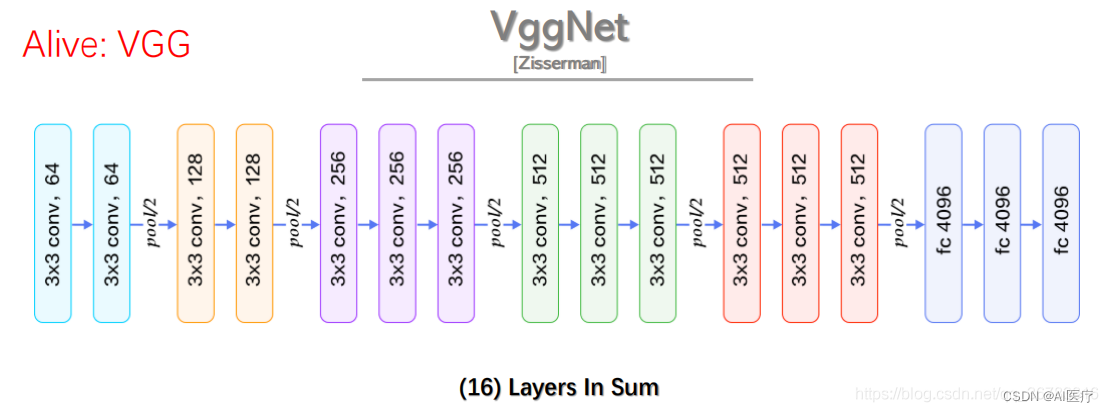
2 VGG16网络结构
VGG16的网络结果如上图所示:在卷积层1(conv3-64),卷积层2(conv3-128),卷积层3(conv3-256),卷积层4(conv3-512)分别有64个,128个,256个,512个3X3卷积核,在每两层之间有池化层为移动步长为2的2X2池化矩阵(maxpool)。在卷积层5(conv3-512)后有全连接层,再之后是soft-max预测层。
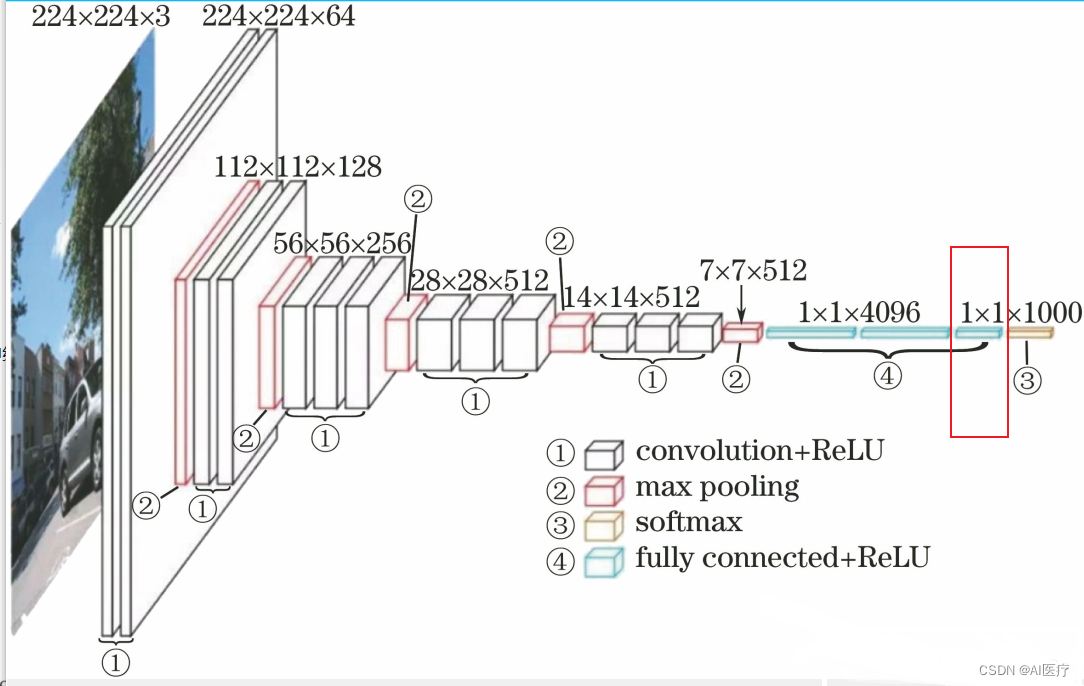
处理过程的直观表示:
3 VGG16在pytorch下,基于cifar-10数据集的实现
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import datetime
from torchvision import datasets
from torch.utils.data import DataLoader
VGG_types = {
"VGG11": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG13": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG16": [64, 64, "M", 128, 128, "M", 256, 256, 256, "M", 512, 512, 512,
"M", 512, 512, 512, "M"],
"VGG19": [64, 64, "M", 128, 128, "M", 256, 256, 256, 256, "M", 512, 512, 512, 512,
"M", 512, 512, 512, 512, "M"]
}
VGGType = "VGG16"
class VGGnet(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(VGGnet, self).__init__()
self.in_channels = in_channels
self.conv_layers = self._create_layers(VGG_types[VGGType])
self.fcs = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.conv_layers(x)
x = x.reshape(x.shape[0], -1)
x = self.fcs(x)
return x
def _create_layers(self, architecture):
layers = []
in_channels = self.in_channels
for x in architecture:
if type(x) == int:
out_channels = x
layers += [
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
),
nn.BatchNorm2d(x),
nn.ReLU(),
]
in_channels = x
elif x == "M":
layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))]
return nn.Sequential(*layers)
transform_train = transforms.Compose(
[
transforms.Pad(4),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.RandomHorizontalFlip(),
transforms.RandomGrayscale(),
transforms.RandomCrop(32, padding=4),
transforms.Resize((224, 224))
])
transform_test = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
transforms.Resize((224, 224))
]
)
train_data = datasets.CIFAR10(
root="data",
train=True,
download=True,
transform=transform_train,
)
test_data = datasets.CIFAR10(
root="data",
train=False,
download=True,
transform=transform_test,
)
def get_format_time():
return datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
if __name__ == "__main__":
train_loader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=64, shuffle=False)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = VGGnet(in_channels=3, num_classes=10).to(device)
print(model)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=5e-3)
loss_func = nn.CrossEntropyLoss()
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.4, last_epoch=-1)
epochs = 40
total = 0
accuracy_rate = []
for epoch in range(epochs):
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
print(f"{get_format_time()},train epoch: {epoch}/{epochs}")
for step, (images, labels) in enumerate(train_loader, 0):
images, labels = images.to(device), labels.to(device)
outputs = model(images).to(device)
loss = loss_func(outputs, labels).to(device)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = outputs.max(1)
correct = torch.sum(predicted == labels)
train_correct += correct
train_total += images.shape[0]
train_loss += loss.item()
if step % 1 == 0 and step > 0:
print(f"{get_format_time()},train epoch = {epoch}, step = {step}, "
f"train_loss={train_loss}")
train_loss = 0.0
break
# 在测试集上进行验证
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for images, labels in test_loader:
images = images.to(device)
outputs = model(images).to(device)
_, predicted = torch.max(outputs, 1)
test_total += labels.size(0)
test_correct += torch.sum(predicted == labels)
break
accuracy = 100 * test_correct / test_total
accuracy_rate.append(accuracy)
print(f"{get_format_time()},test epoch = {epoch}, accuracy={accuracy}")
scheduler.step()
accuracy_rate = np.array(accuracy_rate)
times = np.linspace(1, epochs, epochs)
plt.xlabel('times')
plt.ylabel('accuracy rate')
plt.plot(times, accuracy_rate)
plt.show()
print(f"{get_format_time()},accuracy_rate={accuracy_rate}")模型形状打印输出:
VGGnet(
(conv_layers): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU()
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU()
(13): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU()
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU()
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU()
(23): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU()
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU()
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU()
(33): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU()
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU()
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU()
(43): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0, dilation=1, ceil_mode=False)
)
(fcs): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU()
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)