Scene Flow Using Deep Learning
Contents
- Optical Flow
- Scene Flow for Tracking Objects
- Components of Scene Flow
- SceneFlowNet: Estimate SceneFlow
- Results
光流可以用于目标运动估计,下面将讲解对于目标几何运动估计,光流的局限性和场景流的优势。
- Optical Flow
定义:对于时间t,t+1时刻,同一相机获得两幅图像,分别为Ix,y,t、Ix+dx,y+dy,t+dt
对于一个二维的图像,可以用Ix,y,t表示图像上坐标为x,y的点在t时刻的亮度值。在t 时刻,空间中移动的物体上有一点x,y,经过一段时间δt,该点在图像平面上位移到了x+dx,y+dy,根据亮度不变特性可以得到:
Ix,y,t= Ix+dx,y+dy,t+dt
有泰勒展开式:
fxu+fyv+ft=0 (1)
其中
fx=∂f∂x,fy=∂f∂y
u=dxdt,v=dydt
fx, fy是图像梯度,可以计算出来,ft是时间梯度,也可以计算出来,(u,v)是未知光流,(1)式有两个未知变量,不可解。
有几个方法计算光流:
_ Lucas-Kanade Method
_ Horn-Schunck Method
_ Farneback
所有这些方法都有一些基础假设。
_ Illumination(光照):
照明的变化可以极大地影响流向量,并且将导致在没有运动的位置处创建流向量。 由于该方法假定图像序列上的亮度恒定,因此当图像中存在照明变化时,不能跟踪对象。
_ Large Movements(大位移):
可能无法正确检测到大的运动,因为它们产生很大的位移而不是平滑的运动。 要检测大的移动,必须增加帧速率,或者必须减小图像大小。
_ Occlusion(遮挡)
由于光流仅跟踪帧之间像素的明显移动,因此如果对象被遮挡在另一个对象后面,则不跟踪该对象。 它仅取决于像素的运动,因此不会检测和跟踪被遮挡的对象。
_ Movement of Camera and Object(相机和目标的移动)
当相机或物体处于运动状态时,此方法效果很好,但在相机和物体中都存在相对运动时,此方法无效。 对于实时车辆跟踪系统,由于整个帧中像素的运动将很大,因此该方法不能用于有效地跟踪来自移动车辆的其他物体。
2、Scene Flow for Tracking Objects
为了克服使用传统技术的光流计算的缺点,我们建议使用使用深度学习的场景流。场景流是世界坐标系点的三维运动场,就像光流是图像中点的二维运动场一样。 任何光流都只是将场景流投影到相机的图像平面上。 因此,场景运动的一种表示是为场景中的每个表面上的每个点定义的密集三维矢量场。因此,对于每个图像像素,我们具有深度和运动(等效地为2.5D运动) - 与在光流在图像平面中的情况下2D运动相对应。
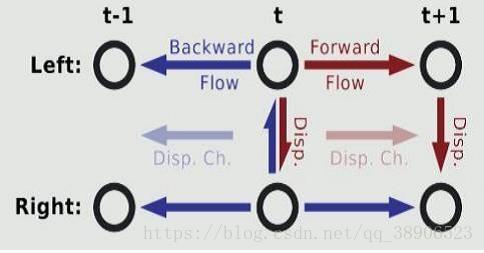
3、Components of Scene Flow
场景流可以分为:
_ Optical Flow
_ Disparities
_ Disparity changes
SceneFlowNet包含two base architectures:
_ FlowNet
_ DispNet
FlowNet:
(1)数据集:Middlebury dataset, KITTI dataset, MPI Sintel dataset
Middlebury dataset :仅包含8个用于训练的图像对,使用四种不同的技术生成ground truth。 位移非常小。
KITTI dataset :KITTI数据集[14]较大(194个训练图像对)并且包括大位移,但仅包含非常特殊的运动类型。 通过使用相机和3D激光扫描仪同时记录场景,从现实世界场景获得基本事实。 这假定场景是刚性的,并且运动源于移动的观察者。 而且,不能捕获诸如天空之类的远处物体的运动,从而导致稀疏的光流基础事实。 这些数据集太小,无法训练大型CNN。
(2)训练:
Adam: β1 = 0.9、β2 = 0.999.(比随机梯度下降更易收敛)
Batch_size:8 (mini-batches of 8 image pairs.)
Learning_rate = 1e-4 (divide it by 2 every 100k iterations after the first 300k.)
Training loss : endpoint error (EPE)( EPE是光流估计的标准误差测量。它是预测的光流和groundtruth之间的欧几里德距离,在所有像素上取平均值。)
(3)结果:
环境:Intel Xeon E5 with 2.40GHz and an NvidiaGTX 1080.
误差:6.07 EPE on Sintel, 8.26 EPE on KITTI and 3.87 on Middlebury
速度:per frame runtime of our model was 1.05 secs.
DispNet:
(1)训练:
Adam: β1 = 0.9、β2 = 0.999.(比随机梯度下降更易收敛)
Batch_size:8 (mini-batches of 8 image pairs.)
Learning_rate = 1e-4 (divide it by 2 every 100k iterations after the first 300k.)
Training loss : endpoint error (EPE)( EPE是光流估计的标准误差测量。它是预测的光流和groundtruth之间的欧几里德距离,在所有像素上取平均值。)
(2)结果:
环境:Intel Xeon E5 with 2.40GHz and an NvidiaGTX 1080.
误差:2.19 EPE on KITTI and 2.02 on FlyingThings3D and 6.38 on Sintel Dataset.
速度:The per frame runtime of our model was 2.13 secs.
4、SceneFlowNet: Estimate SceneFlow
为了估计3D中的完整场景流表示,我们想要组合深度和2D运动信息。 DispNet在时间t -1仅使用左右相机的第一图像对并且在时间t使用左右相机的第二图像对来估计深度。 通过使用FlowNet仅使用来自左相机的连续图像随时间获得的估计光流来估计运动信息,并且类似地针对右相机。两者在场景流动方面相互补充。
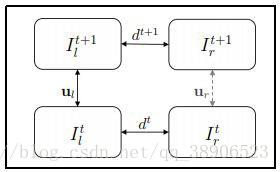
Relation of two stereo image pairs
架构设计(Combining Optical Flow and Disparity)
使用上述架构训练的DispNet和FlowNet用于构建模型以估计场景流。 该模型称为SceneFlowNet。
集成的SceneFlow模型是四层网络,其中从前一层中的FlowNet获得的光流的结果用作下一层中的视差网络的输入,并且类似地,前一层中的视差网络的输出作为下一层的光流网络的输入。 Bootstrapping Network背后的原因是视差估计有助于我们精细化光流估计,同时光流估计帮助我们微调视差预测,并且结果输出是一种有效的SceneFlow模型。 由于我们希望端到端地训练这个模型,因此子模块,即FlowNet和DispNet也必须是端到端的可训练模型。 因此,使用DispNet进行差异估计而不是传统技术。
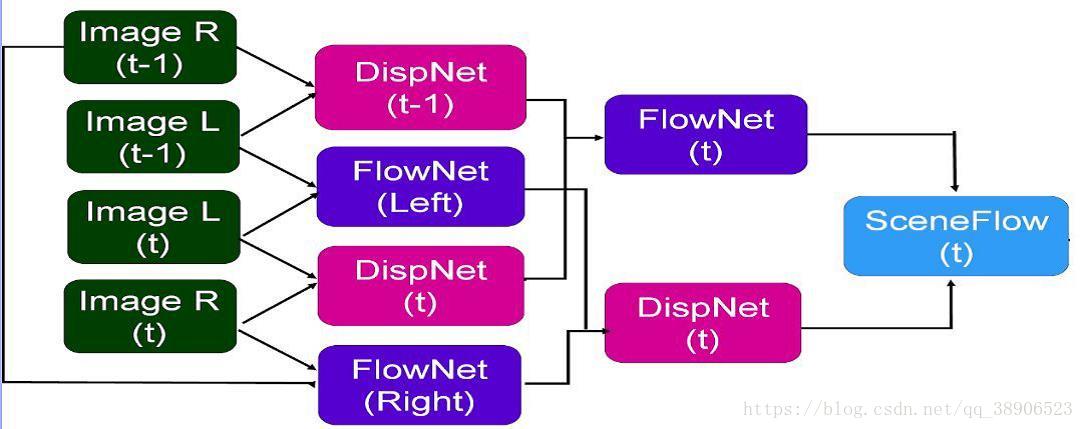
SceneFlowNet 架构
输入:t和t-1时刻的左右图像(四副图像)
DispNet:计算t和t-1时刻的左右图像的视差Dt和Dt-1
FlowNet:计算左右图像在t、t-1时刻的光流Fl和Fr
SceneFlowNet:
Sf:π→R4
其中
Sf
是SceneFlowNet的输出,π是输入图像的维度(四幅图像拥有同样的维度)
Sfx=(u,v,d0,d1)T,这是一个四维度输出,分别是光流估计值和帧t和帧t-1时的视差值。
FlowNet和DispNet的输出交织在一起对SceneFlowNet进行fine-tune。缺点:光流可能离开图像边界,视差也可能不平滑,从而导致无法重建出每一个像素点的场景流,所得到的场景流是稀疏的。
- 结果
我们提出的方法最重要的部分是它使用深度(视差)将2D运动信息扩展到三维空间。 与光流相比,场景流还另外描述了观察(光轴)方向上的运动,提供了诸如自动驾驶车辆之类的许多应用可能从中受益的完整3D运动信息。 场景流结果的评估基于3D运动矢量。 除了参考帧的视差和光流图之外,它还取决于我们在参考帧中表示的第二时间步的视差估计,即可以通过光流warp得到。 这保证了对于参考帧的每个像素,可以通过两个视差图和一个流图来计算3D场景流向量。 我们的评估发生在图像空间(视差和光流空间)中,因为训练数据集中的所有测量都是在图像空间中获得的。
scenes with occlusions(OCC Error).:
EPE of 26.23 for D1, EPE of 20.76 for D2, EPE of 30.33 for Fr , EPE of 36.97 for SF
Non Occlusions scene(NOC Error):
EPE of 13.45 for D1, EPE of 10.32 for D2, EPE of16.72 for Fr, EPE of 14.67 for SF
- 总结
(1)基于卷积网络架构设计的最新进展,我们已经表明,可以训练网络直接预测来自两个输入图像的光流。
(2)训练数据需要更加切合实际。 人造FlyingChairs数据集仅包括合成刚体的仿射运动,不足以准确预测通常具有更复杂结构的自然场景中的光流。
(3)使用DispNet进行视差估计的结果非常准确,因为它可以学习特征的低级表示并非常有效地找到相应的点。
(4)DispNet是一种可后向求导(微分)的深度模型,支持端到端训练,因此可以集成到场景流的体系结构中。
7、未来工作
对于不具有独特纹理和特征的对象的场景,模型预测的场景流不准确。 在这种情况下,它难以区分不同的物体,导致光流估计不良,从而导致不良的场景流。
我们可以通过提供更复杂的数据集来解决这个问题,这些数据集包含更广泛的对象,以便学习更广泛的对象范围的表示。 此外,由于用于我们目的的训练数据是使用具有一些仿射运动的有限刚性对象的综合生成数据集,因此提供更真实的数据集或从真实场景收集的数据可能证明是非常有用的。