点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心 | 编辑:蛋酱、小舟
近日,计算机图形学及互交技术顶会 SIGGRAPH 2023 公布了今年的技术论文奖项。

自 50 年前举办第一次会议以来, Technical Papers program 一直是 SIGGRAPH 的核心。众多研究传播和讨论了动画、模拟、成像、几何、建模、渲染、人机交互、触觉、制造、机器人、可视化、音频、光学、编程语言、沉浸式体验和视觉计算机器学习等方面创新学术工作。
今年,共有 5 项研究获得了最佳论文奖,8 项研究获得了荣誉提名。这些论文因其研究的突出性和对计算机图形和交互技术研究的未来的新贡献而入选。
此外,ACM SIGGRAPH 今年首次设立时间检验奖,这些论文至少在十年内对计算机图形和交互技术产生了重要而持久的影响。时间检验奖委员会评审了 2011 年至 2013 年在 SIGGRAPH 会议上发表的论文,选出了 4 篇获奖论文。
最佳论文
论文 1:Split-Lohmann Multifocal Displays
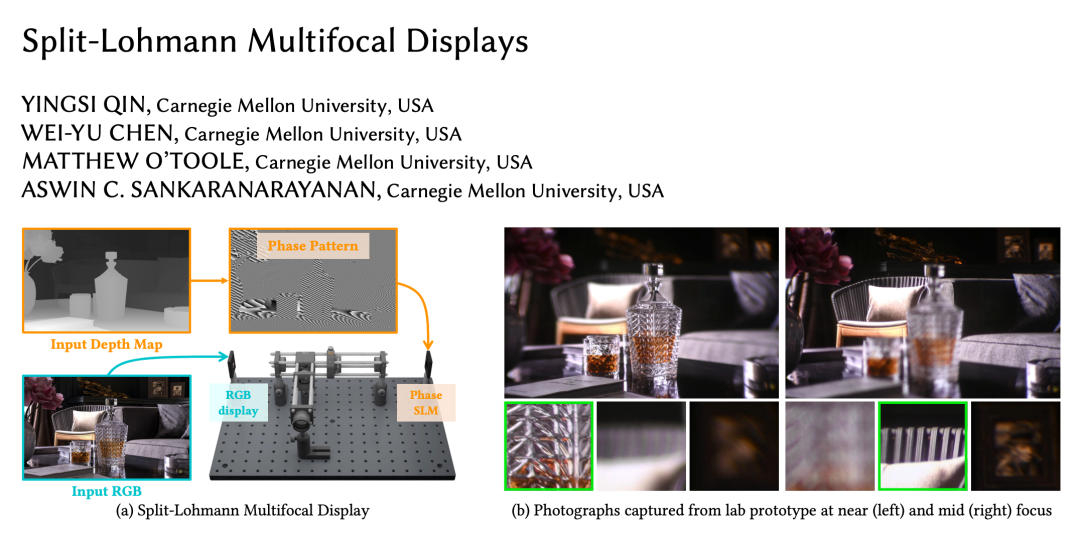
论文链接:https://yingsiqin.github.io/assets/pdfs/SplitLohmann_SIGGRAPH23-lowres.pdf
机构:CMU
研究贡献:这项工作描述了一种近眼 3D 显示器,它可以瞬间创建一个虚拟世界,完全支持人眼关注不同距离内容的固有能力。这种能力使观看者能够以以前无法达到的沉浸水平体验 3D 视频和互动游戏。
论文 2:Differentiable Stripe Patterns for Inverse Design of Structured Surfaces
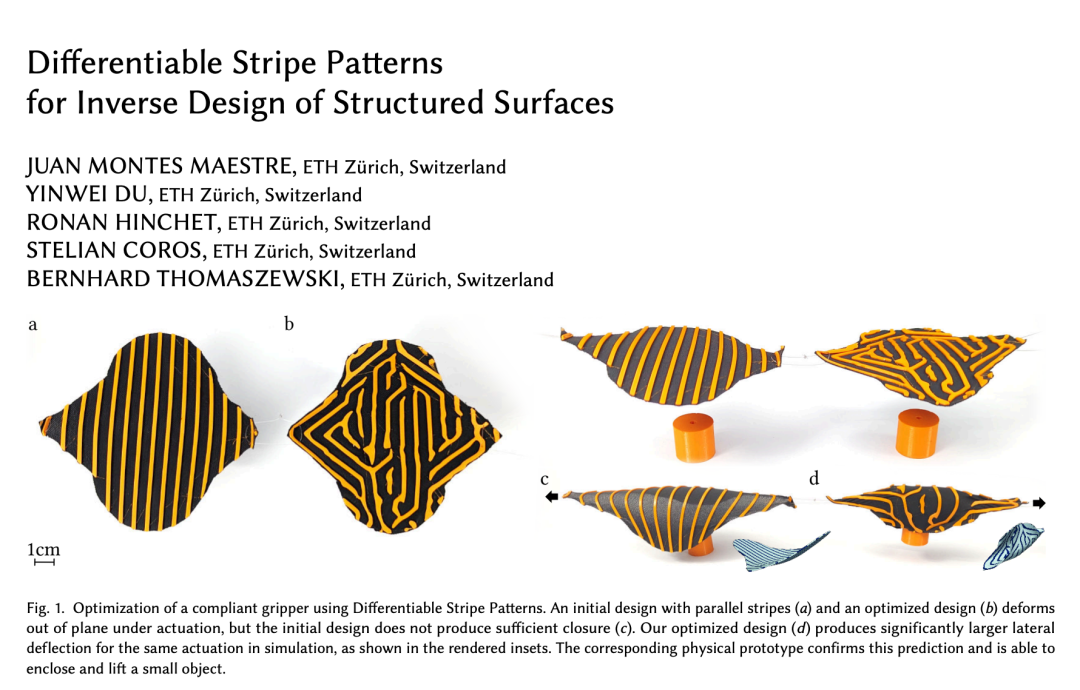
论文链接:https://arxiv.org/pdf/2305.13841.pdf
机构:苏黎世联邦理工学院
研究贡献:这项工作介绍了可微分条纹图案(Differentiable Stripe Patterns),一种用于自动设计具有条纹状、双材料分布的物理表面的计算方法,并提出了一个基于梯度的优化工具来自动计算最接近宏观力学性能目标的条纹图案。
论文 3:Globally Consistent Normal Orientation for Point Clouds by Regularizing the Winding-number Field

论文链接:https://arxiv.org/pdf/2304.11605.pdf
机构:山东大学、香港大学等
研究贡献:这项研究提出了一个平滑的目标函数来描述可接受的绕组数场的要求,它允许人们从一组完全随机的法向开始找到全局一致的法向。
论文 4:3D Gaussian Splatting for Real-time Radiance Field Rendering

论文链接:https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/3d_gaussian_splatting_low.pdf
机构:蔚蓝海岸大学、马克斯・普朗克计算机科学研究所
研究贡献:这项研究提出的方法允许实时渲染(>=30fps)具有高视觉质量的辐射场。该方法用 3D 高斯精确地表示了场景,允许有效的优化。其可见性感知渲染加速了训练,在同等质量的情况下,达到了与之前最快的方法一样的速度。额外一小时的训练就能提供 SOTA 质量。
论文 5:DOC: Differentiable Optimal Control for Retargeting Motions Onto Legged Robots
机构:迪士尼幻想工程研究中心,苏黎世联邦理工学院
研究贡献:这项研究提出了一个可微分最佳控制(DOC)框架,有助于计算关于用户定义参数的最佳控制和状态轨迹的分析导数。研究者通过将 mocap 和动画数据重新定位到一系列不同比例和质量分布的足式机器人上,证明了 DOC 的效用。
荣誉提名
论文 1:GestureDiffuCLIP: Gesture Diffusion Model With CLIP Latents、

论文链接:https://arxiv.org/pdf/2303.14613.pdf
机构:北京大学
研究贡献:这项研究介绍了 GestureDiffuCLIP,这是一个由 CLIP 指导的、与语音相关的手势合成系统,它利用任意的风格提示,创造出与语音语义和节奏相协调的风格化手势。该高度适应性系统支持短文、运动序列或视频片段形式的风格提示,并提供针对身体部位的风格控制。
论文 2:Word-as-image for Semantic Typography

论文链接:https://arxiv.org/pdf/2303.01818.pdf
机构:特拉维夫大学,伦敦大学,莱克曼大学
研究贡献:在「Word-as-image」技术中,词中图呈现了词的含义的可视化,同时也保留了其可读性。这项研究提出了一种自动创建「Word-as-image」插图的方法。在预训练的 Stable Diffusion 模型的指导下,该方法对每个字母的轮廓进行优化,以传达所需的概念。
论文 3:Sag-Free Initialization for Strand-Based Hybrid Hair Simulation

论文链接:https://graphics.cs.utah.edu/research/projects/sag-free-hair/sig23_sagfree-hair.pdf
机构:犹他大学,腾讯北美光子工作室(LightSpeed Studios)
研究贡献:本文提出了一个新颖的四阶段无下垂初始化框架,以解决混合型、基于股的头发动态系统的稳定准静态配置问题。结果表明,本文方法成功地防止了各种发型的下垂,并且最小化了模拟过程对头发运动的影响。
论文 4:Deployable Strip Structures

论文链接:https://www.geometrie.tuwien.ac.at/geom/ig/publications/deployable/deployable.pdf
机构:KAUST,ISTI-CNR 等
研究贡献:C-meshes 捕捉到了可从折叠状态部署的动能结构。它们享有丰富的几何结构和令人惊讶的微分几何关系,特别是具有线性 Weingarten 属性的表面,本文提供了设计和探索 C-meshes 形状空间的工具,并介绍了 architectural paneling 的应用。
论文 5:Towards Attention-Aware Rendering
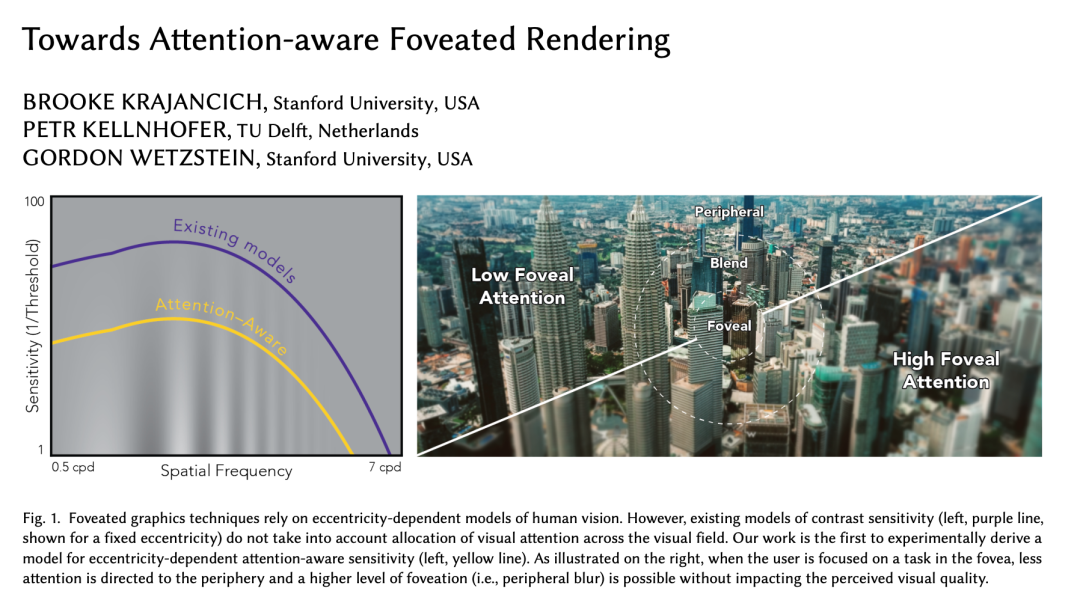
论文链接:https://arxiv.org/pdf/2302.01368.pdf
机构:斯坦福大学,代尔夫特理工大学
研究贡献:现有的用于中心凹形(foveated graphics)的感知模型忽略了视觉注意力的影响,本文介绍了第一个对比敏感度的注意力感知模型,并激励了未来凹陷模型的发展,证明了当用户集中在凹陷处的任务时,对凹陷的容忍度会明显提高。
论文 6:Random-access Neural Compression of Material Textures
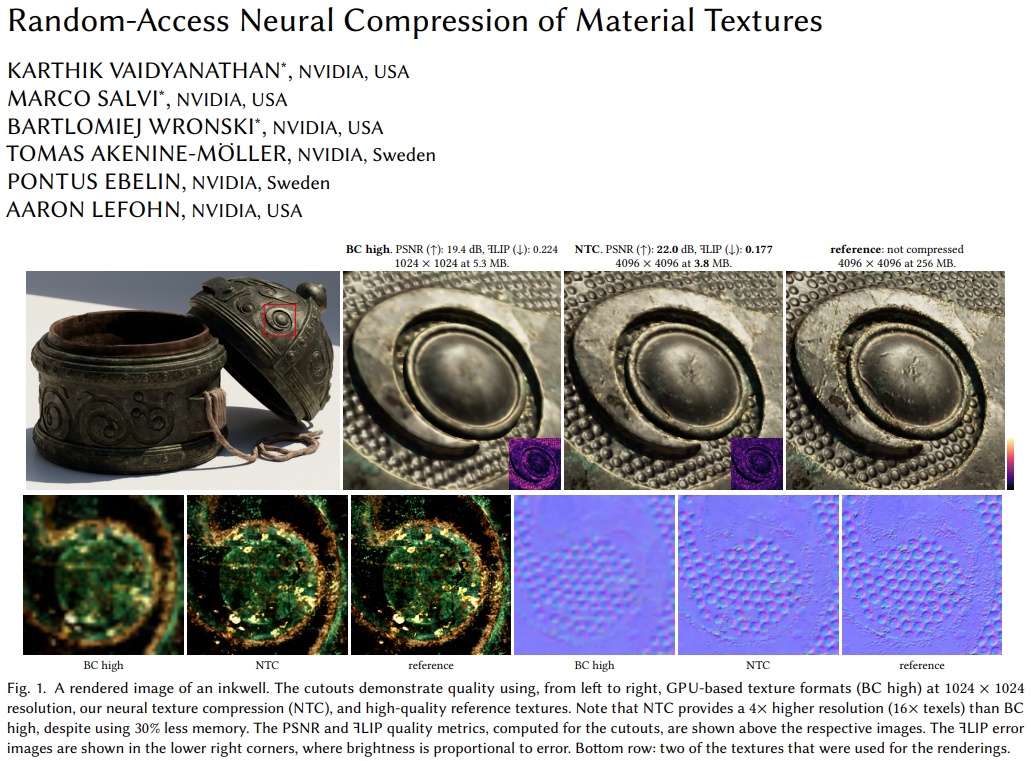
论文链接:https://arxiv.org/pdf/2305.17105.pdf
机构:英伟达
研究贡献:该论文提出了一种针对纹理贴图的神经压缩技术,在质量相当的情况下提供了明显优于 BCx 的压缩,甚至在低比特率下超过了熵编码的 AVIF 和 JPEG XL。该研究提出的方法使用小型的、优化的神经网络,以实现高效压缩、实时解压和在 GPU 上随机访问。
论文 7:Learning Physically Simulated Tennis Skills From Broadcast Videos

论文链接:https://research.nvidia.com/labs/toronto-ai/vid2player3d/data/tennis_skills_main.pdf
机构:斯坦福大学、英伟达等
研究贡献:该论文提出了一个系统,利用从网球视频中收集的大规模但质量较低的动作来学习多样化、复杂的网球技能,让模拟角色以高精确度将球打到目标位置,并成功进行了一系列包括击球和旋转的竞争型比赛。
论文 8:Min-Deviation-Flow in Bi-directed Graphs for T-Mesh Quantization
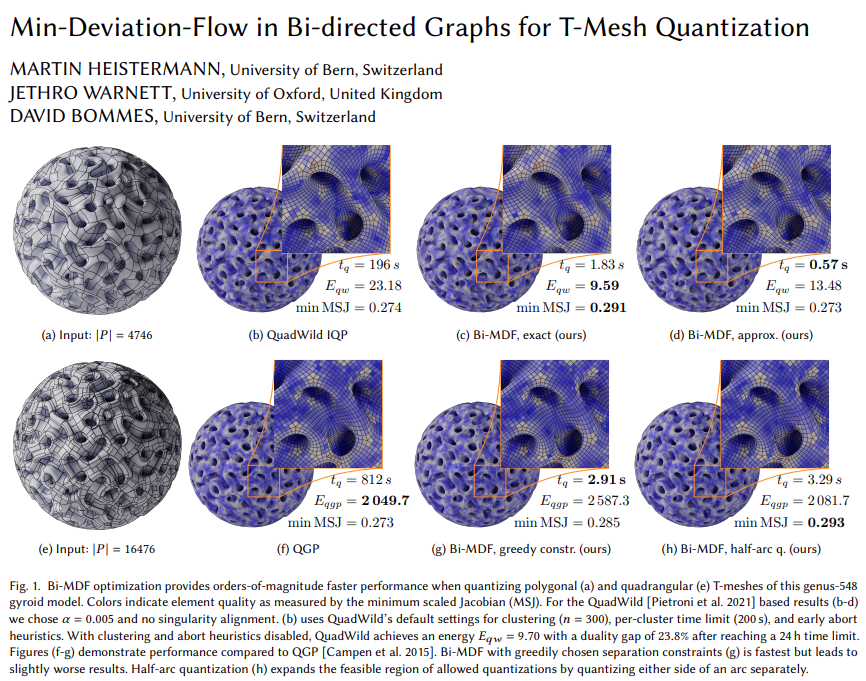
论文链接:https://www.algohex.eu/publications/bimdf-quantization/bimdf-quantization.pdf
机构:伯尔尼大学、牛津大学
研究贡献:T-Mesh 量化的整数优化是 SOTA 四边形网格(quad-meshing)方法的核心问题。该论文针对了双向网络中的最小偏差流问题(Minimum-DeviationFlow Problem in bi-directed networks,Bi-MDF)提出了一种快速近似求解器。
时间检验奖
论文 1:Functional Maps: A Flexible Representation of Maps Between Shapes (2012)
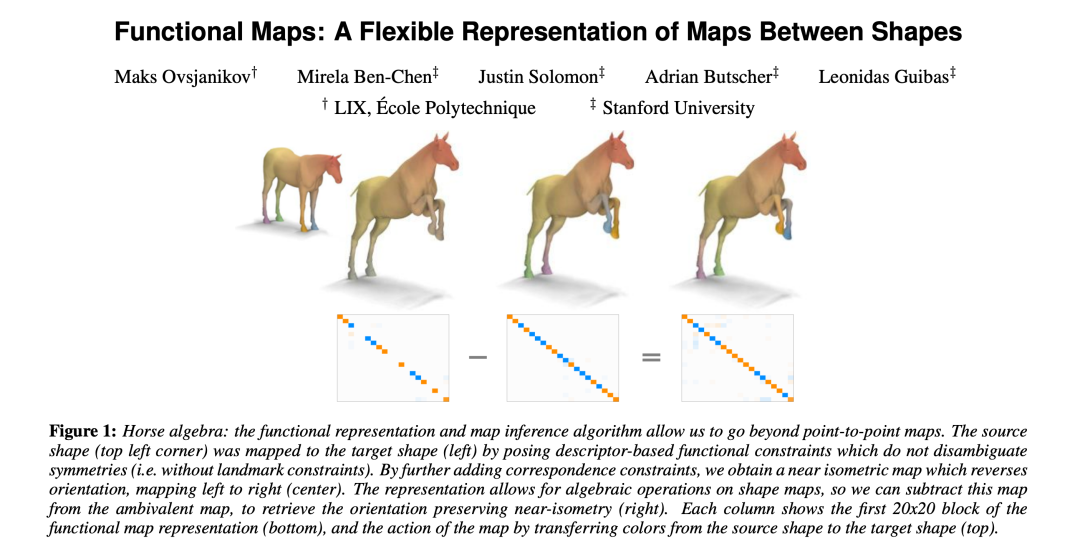
论文链接:https://damassets.autodesk.net/content/dam/autodesk/www/autodesk-reasearch/Publications/pdf/functional-maps-a-flexible.pdf
机构:巴黎综合理工学院、斯坦福大学
研究贡献:建立形状对之间的对应关系是形状推断和操作的基本步骤。该论文提出了一种称为 functional map 的表征形式,引发了大量关于形状匹配的后续研究。
论文 2:Eulerian Video Magnification for Revealing Subtle Changes in the World (2012)

论文链接:https://people.csail.mit.edu/mrub/papers/vidmag.pdf
机构:MIT CSAIL、Quanta Research Cambridge
研究贡献:这篇论文表明,相机可以捕捉微妙但重要的运动,这些运动对于人眼来说太微妙了。后续研究发现了许多应用领域,包括视频监控(video surveillance)、视觉振动测量(visual vibrometry)和视觉麦克风(visual microphone)。
论文 3:HDR-VDP-2: A Calibrated Visual Metric for Visibility and Quality Predictions in All Luminance Conditions (2011)

论文链接:https://www.cl.cam.ac.uk/~rkm38/pdfs/mantiuk11hdrvdp2.pdf
机构:班戈大学、首尔大学、不列颠哥伦比亚大学
研究贡献:该论文提出了在不同亮度条件下人类视觉校准模型的评估指标,该指标已成为预测各种强度图像的可见性和质量的默认标准指标。
论文 4:Optimizing Locomotion Controllers Using Biologically-based Actuators and Objectives (2012)

论文链接:https://nmbl.stanford.edu/publications/pdf/biolocomotion.pdf
机构:斯坦福大学
研究贡献:该论文提出一种在肌肉骨骼水平上模拟人体运动的创新方法,激发了看待人体运动及其模拟程度的新研究方向。
参考链接:https://blog.siggraph.org/2023/07/siggraph-2023-technical-papers-awards-best-papers-honorable-mentions-and-test-of-time.html/
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()