
siggraph 19 上nvidia公布了mesh shader的扩展,在19年10.28日的Directx12的dev preview放出了mesh shader的扩展。
一句话用微软的话来说就是:the next generation of GPU geometry processing capability。
当然便于理解,我们一句话概括,就是将compute shader来代替之前的geometry阶段的各个组合,然后直接输出给rasterizer。
看了之后也颇感兴奋,如果系统兼容性要求低的话,很快就可以依此来重建geometry pipeline,上线耍起来了。
并且这个是一个探索潜力非常大的方式了,虽然改变不大,但是意义不小。
历史与限制
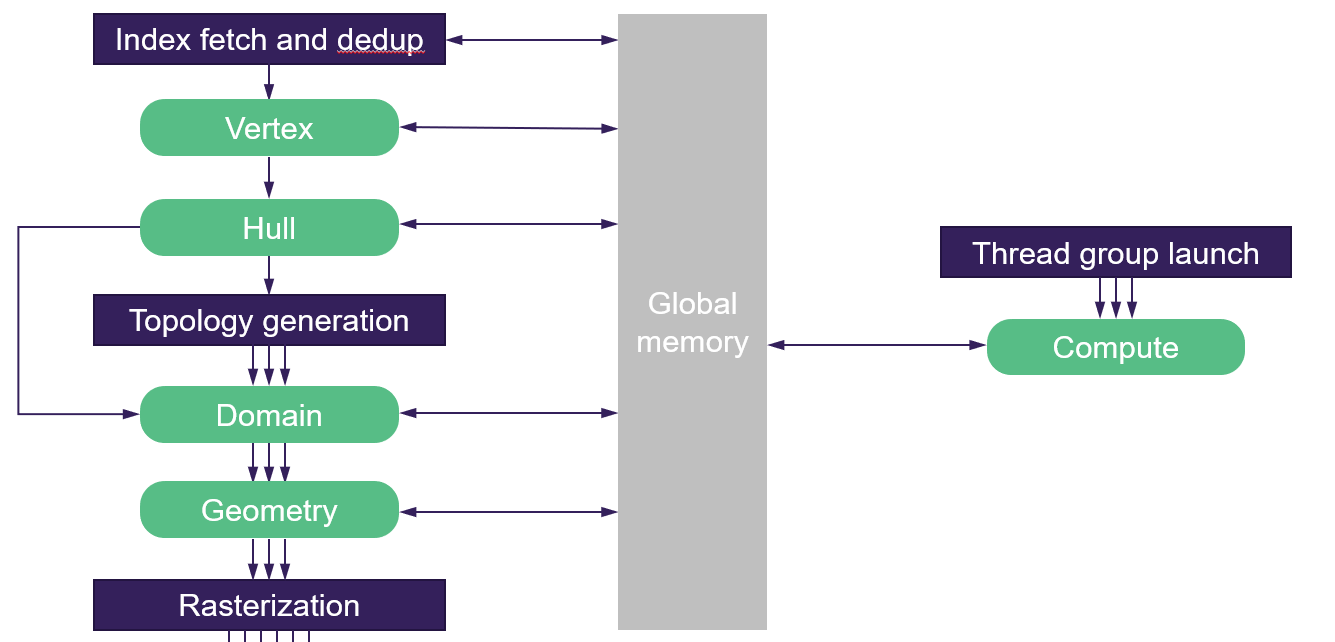
这里我们直接从dx11时代的vertex processing pipeline说起,到了这个阶段,我们可以看到,vertex,hull, domain, geometry n个shader,里面普通计算到tesselation,都异常的繁琐。
还是依照老的方式来构建vertex processing pipeline,如同一些过度封装的引擎,假设开发者都只会用封装好的api。
实际情况中,一方面开发者开始各种gpu driven等的探索,多少都开始在突破预设的限制,一方面compute shader的灵活性计算能力都非常好,成熟AAA游戏中compute shader的使用占比已经非常高了。
这种情况下,老的这种框架很死的vertex processing pipeline就成了限制生产力的结构了。
这里一个最大限制点就是,compute shader和graphics pipeline只能通过memory来进行数据交互,非常低效麻烦。
变化
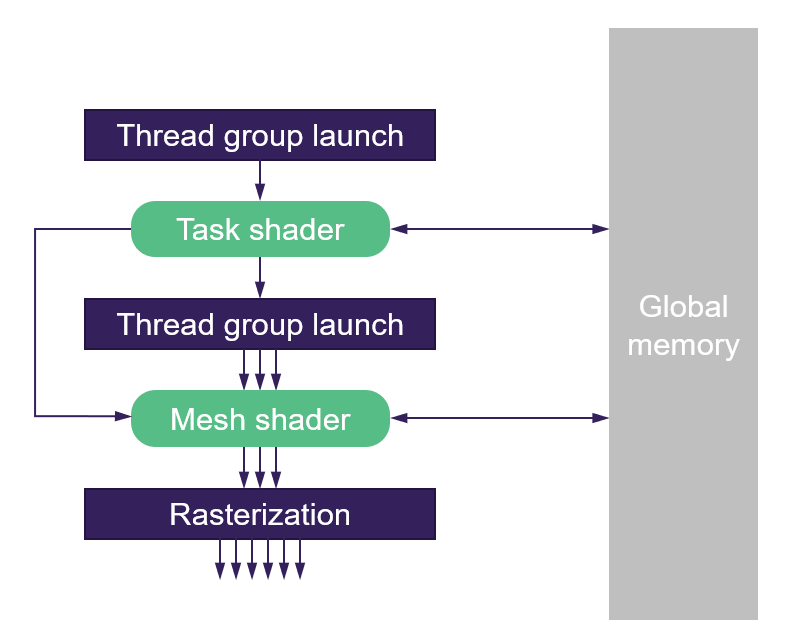
(nvidia的geometry pipeline)
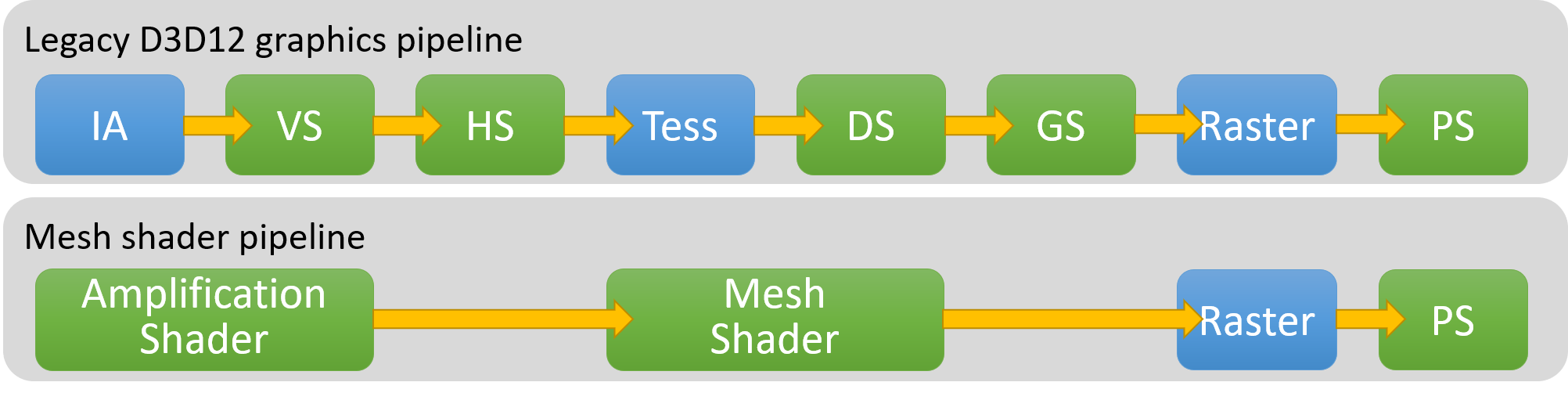
(microsoft的geometry pipeline)
实质上需要突破点很简单,就是要compute shader直接能输出给graphics pipeline即可。
实际叫法上是
- nvidia:task shader+mesh shader
- ms:amplification shader + mesh shader
然后我们用写compute shader的思路来理解mesh shader pipeline就可以了,注意输出格式就好。
优势
这个变化有点像从固定图形管线到可编程shader,重在去掉限制,所以所谓优势,demo能起一个头给个效率对比,最终还是看实际游戏中大家的探索。
这里就举一个nv给栗子:
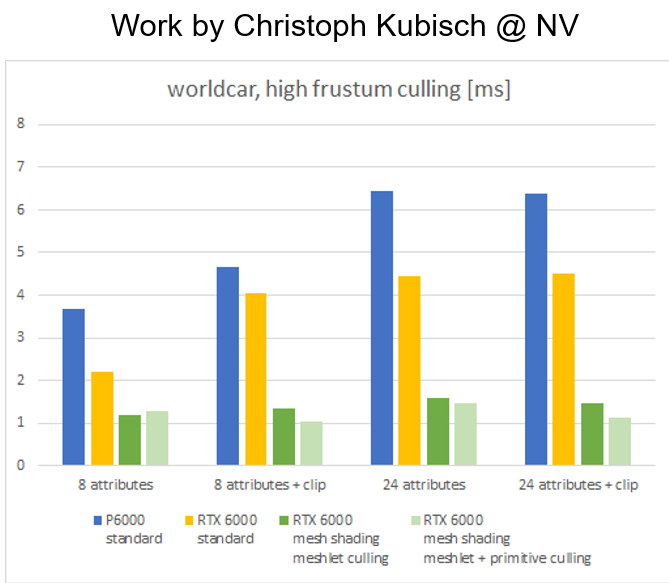
这里是把一些原来比较绕的gpu driven的工作,直接走mesh shader pipeline:
- task shader中做一些cullling工作
