前言
使用PPOCR命令行训练验证码单字位置检测+识别模型的情况下,这两个checkpoint训练模型测试图片均没出现问题,但转为inference推理模型的时候,问题来了。
问题1:文字检测的训练模型转为推理模型结果全为空
官方文档中确实有提到该问题,一开始不清楚如何解决,后来进入PaddleOCR的项目代码中查看对应的代码文件后发现问题。

根据文档的描述是:训练模型的预处理和inference模型的预处理函数是否一致。在训练时可能将图像resize到某个大小,而inference模型预测是用一套默认的参数,也就是你需要到inference模型的预处理函数中将默认参数改为与你实际项目训练时的参数一致。预处理函数在PaddleOCR项目下的./ppocr/data/imaug/operators.py。
解决的过程
-
首先,根据文档提示检查两个预处理参数。检查配置文件的DetResizeForTest发现默认是注释掉的。
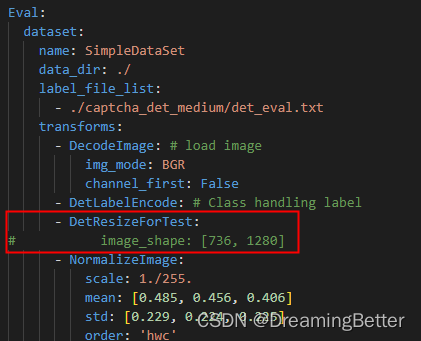
-
检查./ppocr/data/imaug/operators.py的DetResizeForTest,那么既然是没有参数,那么
resize_type默认=0,limit_side_len=736,limit_type='min',走的是resize_image_type0()方法。
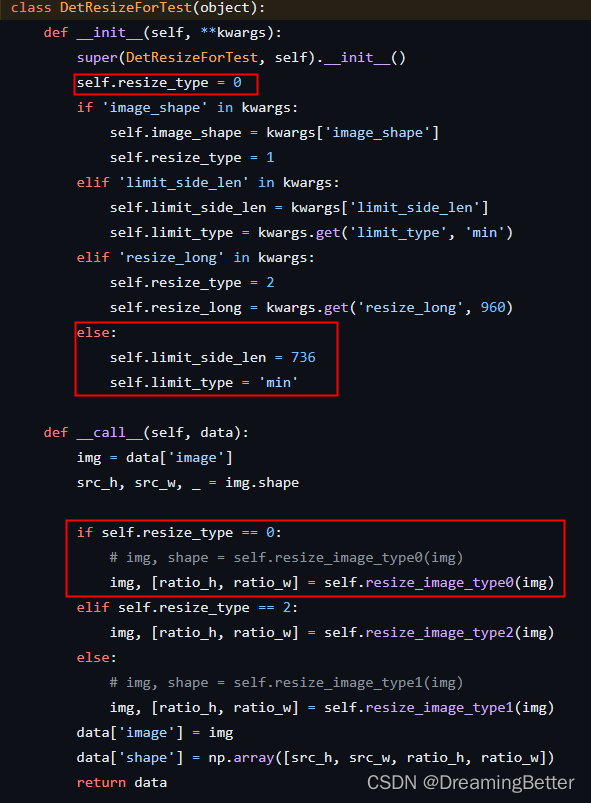
-
检查./tools/infer/predict_det.py的TextDetector,发现他是默认配置了
limit_side_len=960和limit_type='max'的,虽然也是走的resize_image_type0(),但参数跟我们训练时的参数不一致。
所以直接将这两个参数注释掉,保持与配置文件的没有参数一致。那么预处理就走的同样的方法,且参数一致了。
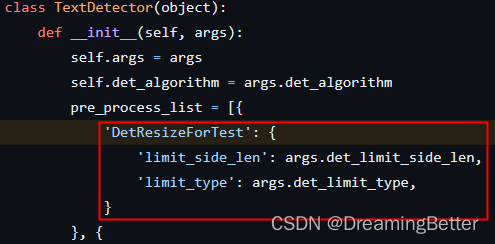
-
做到这边再进行推理就有结果了。解决了第一个问题。
问题2:串联检测+识别推理模型,识别效果极差
检测的问题解决了,单独使用检测推理时,结果基本跟模型测试时一致。单独使用识别模型推理时,结果也很好,基本在可接受范围内。但是串联两个模型推理时,识别效果极差,甚至连检测效果都变差了。
解决的过程
- 检查./tools/infer/predict_system.py,经过卡卡一顿看代码,夸夸一顿分析,最后发现在对单个字符进行crop时,当crop后的图片高大于宽时,会自动旋转90度。所以才导致出现2识别成N的类似情况。
最后根据项目的实际情况,这一步是没必要的,所以我直接将他注释掉。crop出来的单个字符图片就正常了,再进行推理也没问题了。
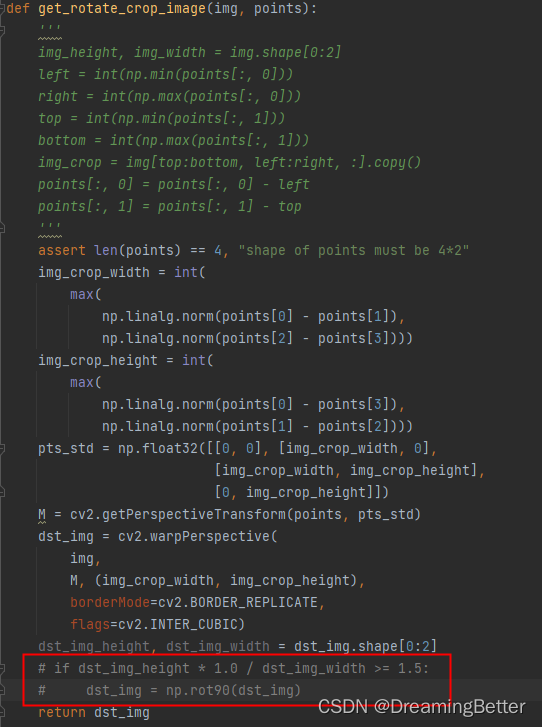
最后进行验证:结果终于能正确显示出来了。

*以上就是刚入门模型训练遇到的所有问题和解决过程,这两个问题差点劝退我,所以做个记录和分享,万一正好有人入门也遇到这个问题呢?