本文系统ubuntu16.04,耐心看完!!
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
1、conda虚拟环境创建
conda create -n py39 python=3.92、安装torch、torchvision
http://download.pytorch.org/whl/cu116
在这个链接中下载torch和torchvision的whl文件
pip install torch-1.12.0+cu113-cp39-cp39-linux_x86_64.whl
pip install torchvision-0.13.0+cu113-cp39-cp39-linux_x86_64.whl 3. 安装依赖包
pip install git+https://github.com/facebookresearch/fvcore
pip install simplejson
conda install av -c conda-forge
pip install av
pip list fvcore
pip install -U iopath
pip install psutil
pip install opencv-python
pip install tensorboard
pip install moviepy
pip install pytorchvideo
git clone https://github.com/facebookresearch/detectron2 detectron2_repo
pip install -e detectron2_repo
pip install git+https://github.com/facebookresearch/fairscale
4. SlowFast
git clone https://github.com/facebookresearch/SlowFast.git
cd SlowFast
python setup.py build develop
5.修改配置文件,运行代码
5.1 ava.json
{"bend/bow (at the waist)": 0, "crawl": 1, "crouch/kneel": 2, "dance": 3, "fall down": 4, "get up": 5, "jump/leap": 6, "lie/sleep": 7, "martial art": 8, "run/jog": 9, "sit": 10, "stand": 11, "swim": 12, "walk": 13, "answer phone": 14, "brush teeth": 15, "carry/hold (an object)": 16, "catch (an object)": 17, "chop": 18, "climb (e.g., a mountain)": 19, "clink glass": 20, "close (e.g., a door, a box)": 21, "cook": 22, "cut": 23, "dig": 24, "dress/put on clothing": 25, "drink": 26, "drive (e.g., a car, a truck)": 27, "eat": 28, "enter": 29, "exit": 30, "extract": 31, "fishing": 32, "hit (an object)": 33, "kick (an object)": 34, "lift/pick up": 35, "listen (e.g., to music)": 36, "open (e.g., a window, a car door)": 37, "paint": 38, "play board game": 39, "play musical instrument": 40, "play with pets": 41, "point to (an object)": 42, "press": 43, "pull (an object)": 44, "push (an object)": 45, "put down": 46, "read": 47, "ride (e.g., a bike, a car, a horse)": 48, "row boat": 49, "sail boat": 50, "shoot": 51, "shovel": 52, "smoke": 53, "stir": 54, "take a photo": 55, "text on/look at a cellphone": 56, "throw": 57, "touch (an object)": 58, "turn (e.g., a screwdriver)": 59, "watch (e.g., TV)": 60, "work on a computer": 61, "write": 62, "fight/hit (a person)": 63, "give/serve (an object) to (a person)": 64, "grab (a person)": 65, "hand clap": 66, "hand shake": 67, "hand wave": 68, "hug (a person)": 69, "kick (a person)": 70, "kiss (a person)": 71, "lift (a person)": 72, "listen to (a person)": 73, "play with kids": 74, "push (another person)": 75, "sing to (e.g., self, a person, a group)": 76, "take (an object) from (a person)": 77, "talk to (e.g., self, a person, a group)": 78, "watch (a person)": 79}
将上面的内容,保存在ava.json里面,然后保存在./slowfast/demo/AVA目录下。
5.2 SLOWFAST_32x2_R101_50_50.yaml
/slowfast/demo/AVA中打开SLOWFAST_32x2_R101_50_50.yaml
内容改为如下
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/slowfast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl' #path to pretrain model
CHECKPOINT_TYPE: pytorch
DATA:
NUM_FRAMES: 32
SAMPLING_RATE: 2
TRAIN_JITTER_SCALES: [256, 320]
TRAIN_CROP_SIZE: 224
TEST_CROP_SIZE: 256
INPUT_CHANNEL_NUM: [3, 3]
DETECTION:
ENABLE: True
ALIGNED: False
AVA:
BGR: False
DETECTION_SCORE_THRESH: 0.8
TEST_PREDICT_BOX_LISTS: ["person_box_67091280_iou90/ava_detection_val_boxes_and_labels.csv"]
SLOWFAST:
ALPHA: 4
BETA_INV: 8
FUSION_CONV_CHANNEL_RATIO: 2
FUSION_KERNEL_SZ: 5
RESNET:
ZERO_INIT_FINAL_BN: True
WIDTH_PER_GROUP: 64
NUM_GROUPS: 1
DEPTH: 101
TRANS_FUNC: bottleneck_transform
STRIDE_1X1: False
NUM_BLOCK_TEMP_KERNEL: [[3, 3], [4, 4], [6, 6], [3, 3]]
SPATIAL_DILATIONS: [[1, 1], [1, 1], [1, 1], [2, 2]]
SPATIAL_STRIDES: [[1, 1], [2, 2], [2, 2], [1, 1]]
NONLOCAL:
LOCATION: [[[], []], [[], []], [[6, 13, 20], []], [[], []]]
GROUP: [[1, 1], [1, 1], [1, 1], [1, 1]]
INSTANTIATION: dot_product
POOL: [[[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]], [[2, 2, 2], [2, 2, 2]]]
BN:
USE_PRECISE_STATS: False
NUM_BATCHES_PRECISE: 200
SOLVER:
MOMENTUM: 0.9
WEIGHT_DECAY: 1e-7
OPTIMIZING_METHOD: sgd
MODEL:
NUM_CLASSES: 80
ARCH: slowfast
MODEL_NAME: SlowFast
LOSS_FUNC: bce
DROPOUT_RATE: 0.5
HEAD_ACT: sigmoid
TEST:
ENABLE: False
DATASET: ava
BATCH_SIZE: 8
DATA_LOADER:
NUM_WORKERS: 2
PIN_MEMORY: True
NUM_GPUS: 1
NUM_SHARDS: 1
RNG_SEED: 0
OUTPUT_DIR: .
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "/home/slowfast/demo/AVA/ava.json"
INPUT_VIDEO: "/home/slowfast/Vinput/2.mp4"
OUTPUT_FILE: "/home/slowfast/Voutput/1.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl下面这一行代码存放的是输入视频的位置,当然Vinput这个文件夹是我自己建的
OUTPUT_FILE: "/home/slowfast/Voutput/1.mp4"下面这一行代码存放的是检测后视频的位置,当然Voutput这个文件夹是我自己建的
OUTPUT_FILE: "/home/slowfast/Voutput/1.mp4"5.3 SLOWFAST_32x2_R101_50_50 .pkl
模型下载链接
https://github.com/facebookresearch/SlowFast/blob/main/MODEL_ZOO.md
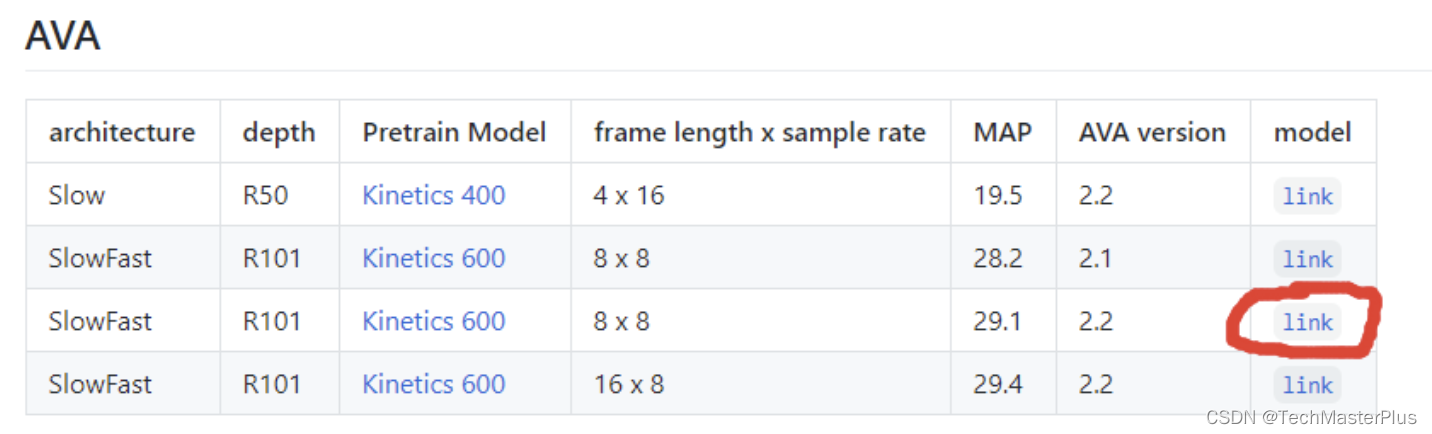
然后在目录:/home/slowfast/demo/AVA下文件SLOWFAST_32x2_R101_50_50.yaml里修改如下:
TRAIN:
ENABLE: False
DATASET: ava
BATCH_SIZE: 16
EVAL_PERIOD: 1
CHECKPOINT_PERIOD: 1
AUTO_RESUME: True
CHECKPOINT_FILE_PATH: '/home/slowfast/configs/AVA/c2/SLOWFAST_32x2_R101_50_50.pkl' #path to pretrain model
CHECKPOINT_TYPE: pytorch
5.4 代码运行
在终端跳转到以下目录
cd /home/slowfast/
输入运行命令
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml6、常见错误
目录
错误一:
not find PIL
解决办法:将setup.py 中的 PIL 更改为 Pillow
错误二:
from pytorchvideo.layers.distributed import ( # noqa
ImportError: cannot import name 'cat_all_gather' from 'pytorchvideo.layers.distributed' (/home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/pytorchvideo/layers/distributed.py)
解决方式:
方式一:将pytorchvideo/pytorchvideo at main · facebookresearch/pytorchvideo · GitHub文件下内容复制到虚拟环境所对应的文件下,这里是:/home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/pytorchvideo/
方式二:
layers/distributed.py添加如下内容
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
"""Distributed helpers."""
import torch
import torch.distributed as dist
from torch._C._distributed_c10d import ProcessGroup
from torch.autograd.function import Function
_LOCAL_PROCESS_GROUP = None
def get_world_size() -> int:
"""
Simple wrapper for correctly getting worldsize in both distributed
/ non-distributed settings
"""
return (
torch.distributed.get_world_size()
if torch.distributed.is_available() and torch.distributed.is_initialized()
else 1
)
def cat_all_gather(tensors, local=False):
"""Performs the concatenated all_reduce operation on the provided tensors."""
if local:
gather_sz = get_local_size()
else:
gather_sz = torch.distributed.get_world_size()
tensors_gather = [torch.ones_like(tensors) for _ in range(gather_sz)]
torch.distributed.all_gather(
tensors_gather,
tensors,
async_op=False,
group=_LOCAL_PROCESS_GROUP if local else None,
)
output = torch.cat(tensors_gather, dim=0)
return output
def init_distributed_training(cfg):
"""
Initialize variables needed for distributed training.
"""
if cfg.NUM_GPUS <= 1:
return
num_gpus_per_machine = cfg.NUM_GPUS
num_machines = dist.get_world_size() // num_gpus_per_machine
for i in range(num_machines):
ranks_on_i = list(
range(i * num_gpus_per_machine, (i + 1) * num_gpus_per_machine)
)
pg = dist.new_group(ranks_on_i)
if i == cfg.SHARD_ID:
global _LOCAL_PROCESS_GROUP
_LOCAL_PROCESS_GROUP = pg
def get_local_size() -> int:
"""
Returns:
The size of the per-machine process group,
i.e. the number of processes per machine.
"""
if not dist.is_available():
return 1
if not dist.is_initialized():
return 1
return dist.get_world_size(group=_LOCAL_PROCESS_GROUP)
def get_local_rank() -> int:
"""
Returns:
The rank of the current process within the local (per-machine) process group.
"""
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
assert _LOCAL_PROCESS_GROUP is not None
return dist.get_rank(group=_LOCAL_PROCESS_GROUP)
def get_local_process_group() -> ProcessGroup:
assert _LOCAL_PROCESS_GROUP is not None
return _LOCAL_PROCESS_GROUP
class GroupGather(Function):
"""
GroupGather performs all gather on each of the local process/ GPU groups.
"""
@staticmethod
def forward(ctx, input, num_sync_devices, num_groups):
"""
Perform forwarding, gathering the stats across different process/ GPU
group.
"""
ctx.num_sync_devices = num_sync_devices
ctx.num_groups = num_groups
input_list = [torch.zeros_like(input) for k in range(get_local_size())]
dist.all_gather(
input_list, input, async_op=False, group=get_local_process_group()
)
inputs = torch.stack(input_list, dim=0)
if num_groups > 1:
rank = get_local_rank()
group_idx = rank // num_sync_devices
inputs = inputs[
group_idx * num_sync_devices : (group_idx + 1) * num_sync_devices
]
inputs = torch.sum(inputs, dim=0)
return inputs
@staticmethod
def backward(ctx, grad_output):
"""
Perform backwarding, gathering the gradients across different process/ GPU
group.
"""
grad_output_list = [
torch.zeros_like(grad_output) for k in range(get_local_size())
]
dist.all_gather(
grad_output_list,
grad_output,
async_op=False,
group=get_local_process_group(),
)
grads = torch.stack(grad_output_list, dim=0)
if ctx.num_groups > 1:
rank = get_local_rank()
group_idx = rank // ctx.num_sync_devices
grads = grads[
group_idx
* ctx.num_sync_devices : (group_idx + 1)
* ctx.num_sync_devices
]
grads = torch.sum(grads, dim=0)
return grads, None, None错误三:
from scipy.ndimage import gaussian_filter
ModuleNotFoundError: No module named 'scipy'解决方法:
pip install scipy
错误四:
from av._core import time_base, library_versions
ImportError: /home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/av/../../.././libgnutls.so.30: symbol mpn_copyi version HOGWEED_6 not defined in file libhogweed.so.6 with link time reference
解决方法:
先移处av包
使用 pip安装
pip install av
错误五:
File "/media/cxgk/Linux/work/SlowFast/slowfast/models/losses.py", line 11, in
from pytorchvideo.losses.soft_target_cross_entropy import (
ModuleNotFoundError: No module named 'pytorchvideo.losses'
解决办法:
打开"/home/cxgk/anaconda3/envs/sf/lib/python3.9/site-packages/pytorchvideo/losses",在文件夹下新建 soft_target_cross_entropy.py, 并打开添加如下代码:
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorchvideo.layers.utils import set_attributes
from pytorchvideo.transforms.functional import convert_to_one_hot
class SoftTargetCrossEntropyLoss(nn.Module):
"""
Adapted from Classy Vision: ./classy_vision/losses/soft_target_cross_entropy_loss.py.
This allows the targets for the cross entropy loss to be multi-label.
"""
def __init__(
self,
ignore_index: int = -100,
reduction: str = "mean",
normalize_targets: bool = True,
) -> None:
"""
Args:
ignore_index (int): sample should be ignored for loss if the class is this value.
reduction (str): specifies reduction to apply to the output.
normalize_targets (bool): whether the targets should be normalized to a sum of 1
based on the total count of positive targets for a given sample.
"""
super().__init__()
set_attributes(self, locals())
assert isinstance(self.normalize_targets, bool)
if self.reduction not in ["mean", "none"]:
raise NotImplementedError(
'reduction type "{}" not implemented'.format(self.reduction)
)
self.eps = torch.finfo(torch.float32).eps
def forward(self, input: torch.Tensor, target: torch.Tensor) -> torch.Tensor:
"""
Args:
input (torch.Tensor): the shape of the tensor is N x C, where N is the number of
samples and C is the number of classes. The tensor is raw input without
softmax/sigmoid.
target (torch.Tensor): the shape of the tensor is N x C or N. If the shape is N, we
will convert the target to one hot vectors.
"""
# Check if targets are inputted as class integers
if target.ndim == 1:
assert (
input.shape[0] == target.shape[0]
), "SoftTargetCrossEntropyLoss requires input and target to have same batch size!"
target = convert_to_one_hot(target.view(-1, 1), input.shape[1])
assert input.shape == target.shape, (
"SoftTargetCrossEntropyLoss requires input and target to be same "
f"shape: {input.shape} != {target.shape}"
)
# Samples where the targets are ignore_index do not contribute to the loss
N, C = target.shape
valid_mask = torch.ones((N, 1), dtype=torch.float).to(input.device)
if 0 <= self.ignore_index <= C - 1:
drop_idx = target[:, self.ignore_idx] > 0
valid_mask[drop_idx] = 0
valid_targets = target.float() * valid_mask
if self.normalize_targets:
valid_targets /= self.eps + valid_targets.sum(dim=1, keepdim=True)
per_sample_per_target_loss = -valid_targets * F.log_softmax(input, -1)
per_sample_loss = torch.sum(per_sample_per_target_loss, -1)
# Perform reduction
if self.reduction == "mean":
# Normalize based on the number of samples with > 0 non-ignored targets
loss = per_sample_loss.sum() / torch.sum(
(torch.sum(valid_mask, -1) > 0)
).clamp(min=1)
elif self.reduction == "none":
loss = per_sample_loss
return 错误六:
from sklearn.metrics import confusion_matrix
ModuleNotFoundError: No module named 'sklearn'解决办法:
pip install scikit-learn
错误七:
raise KeyError("Non-existent config key: {}".format(full_key))
KeyError: 'Non-existent config key: TENSORBOARD.MODEL_VIS.TOPK'
解决方法:
注释掉如下三行:
TENSORBOARD
MODEL_VIS
TOPK
错误八:
RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 3.94 GiB total capacity; 2.83 GiB already allocated; 25.44 MiB free; 2.84 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解决方法:
将yaml里的帧数改小:
DATA:
NUM_FRAMES: 16