分页数据的爬取-肯德基餐厅位置信息
1 分析
输入地址后显示的地址和最初的地址一样
说明按下查询按钮发起的是Ajax请求
- 当前页面刷新出来的位置信息一定是通过ajax请求请求到的数据


.基于抓包工具定位到该ajax请求的数据包,从该数据包中捕获到:
- 请求的url
- 请求方式
- 请求携带的参数
- 看到响应数据
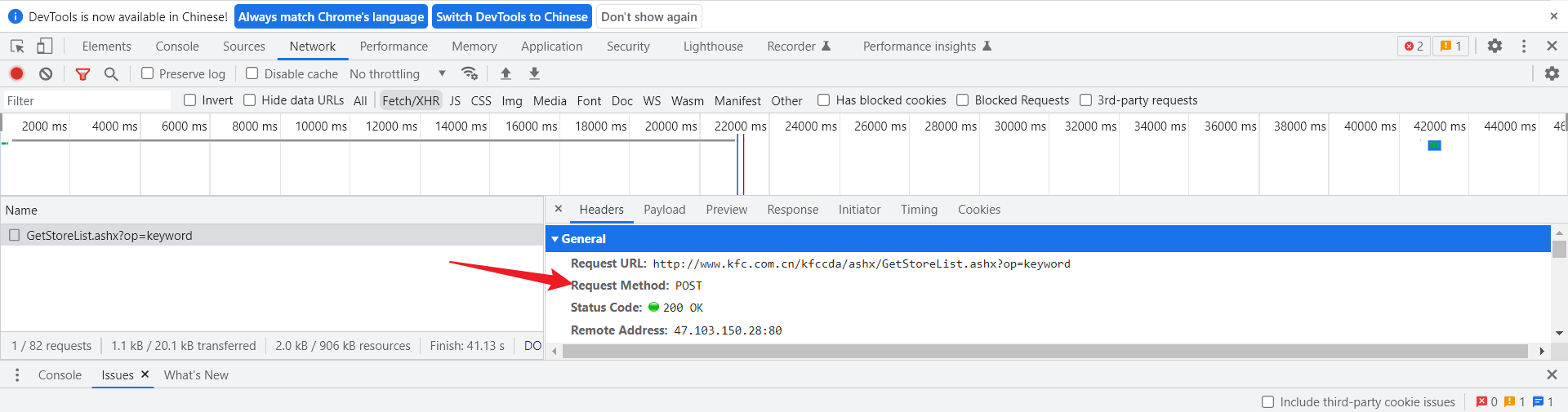
最初抓包的时候都是选择的ALL,但是分析出了这里发送的是Ajax请求,所以本次选择Fetch/XHR,这个是专门查看Ajax请求的
打开F12,选择Fetch/XHR,点击查询后查看结果
发现请求方式是post方式
返回值还是json格式
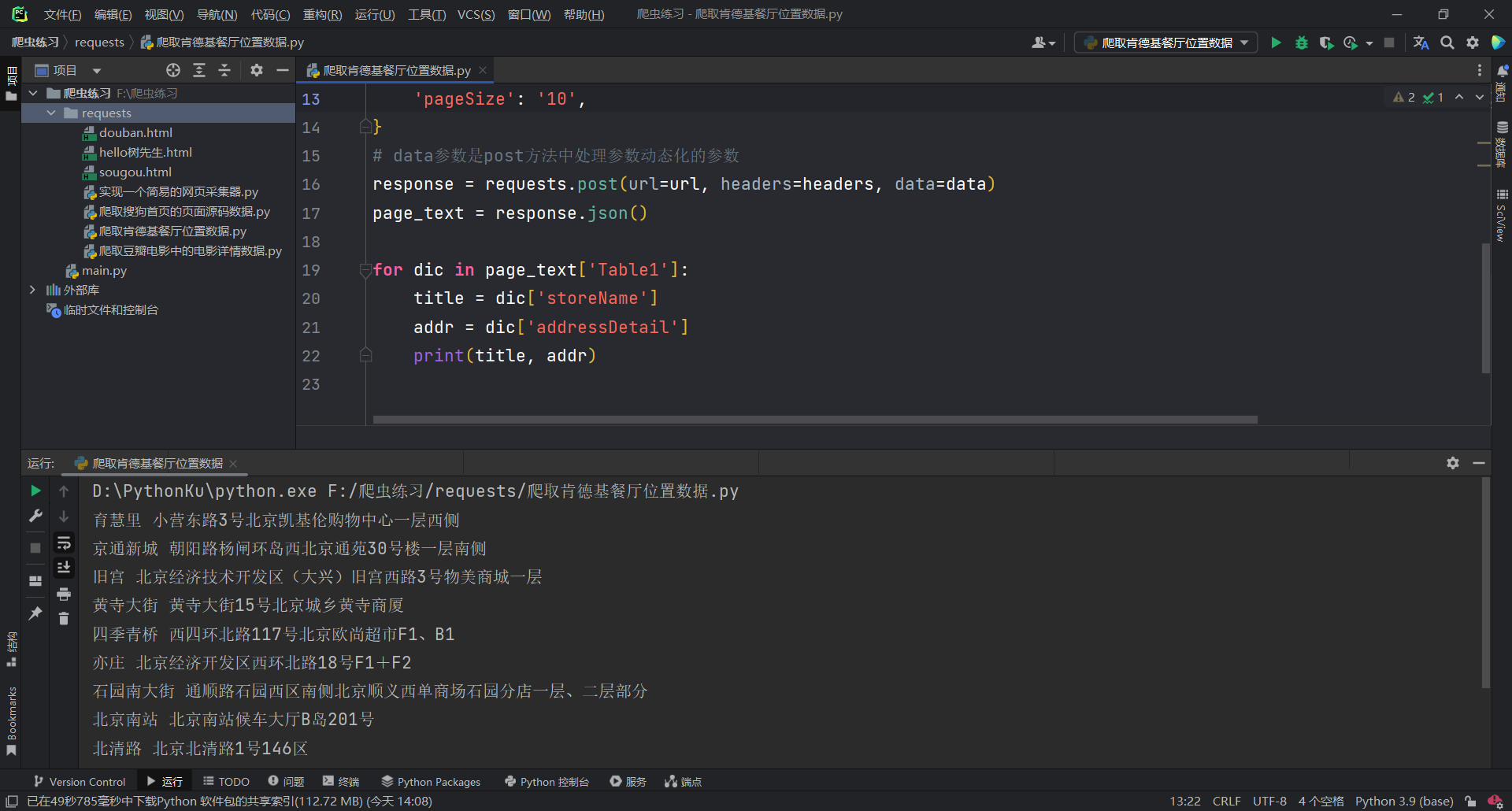
2 爬取到一页数据
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': '1',
'pageSize': '10',
}
# data参数是post方法中处理参数动态化的参数
response = requests.post(url=url, headers=headers, data=data)
page_text = response.json()
for dic in page_text['Table1']:
title = dic['storeName']
addr = dic['addressDetail']
print(title, addr)
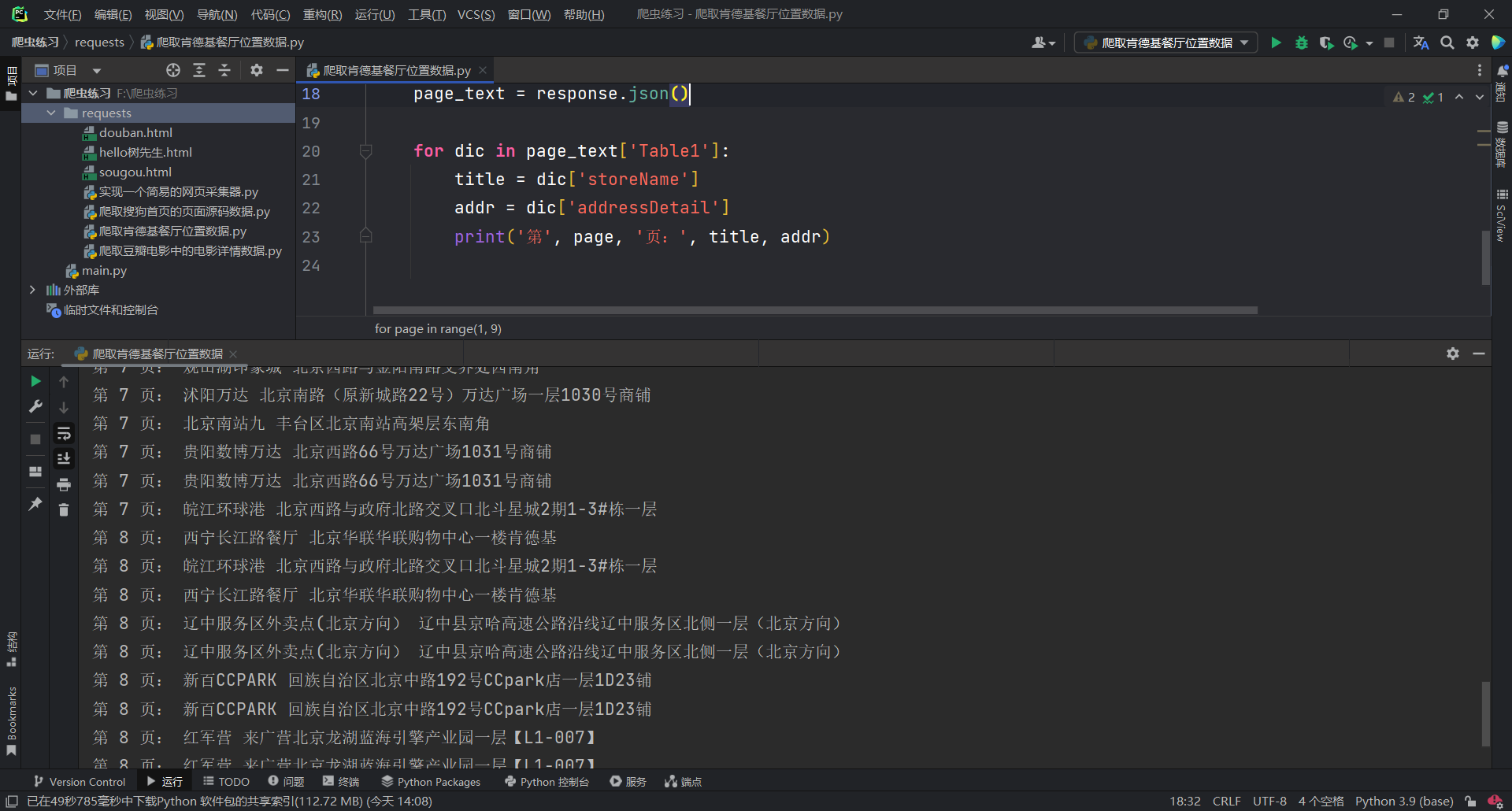
3 爬取多页数据
当点击第二页的时候,发现请求的数据的pageIndex变为了2,点击第三页的时候变为了3。
所以写一个循环就可以爬取所有页面
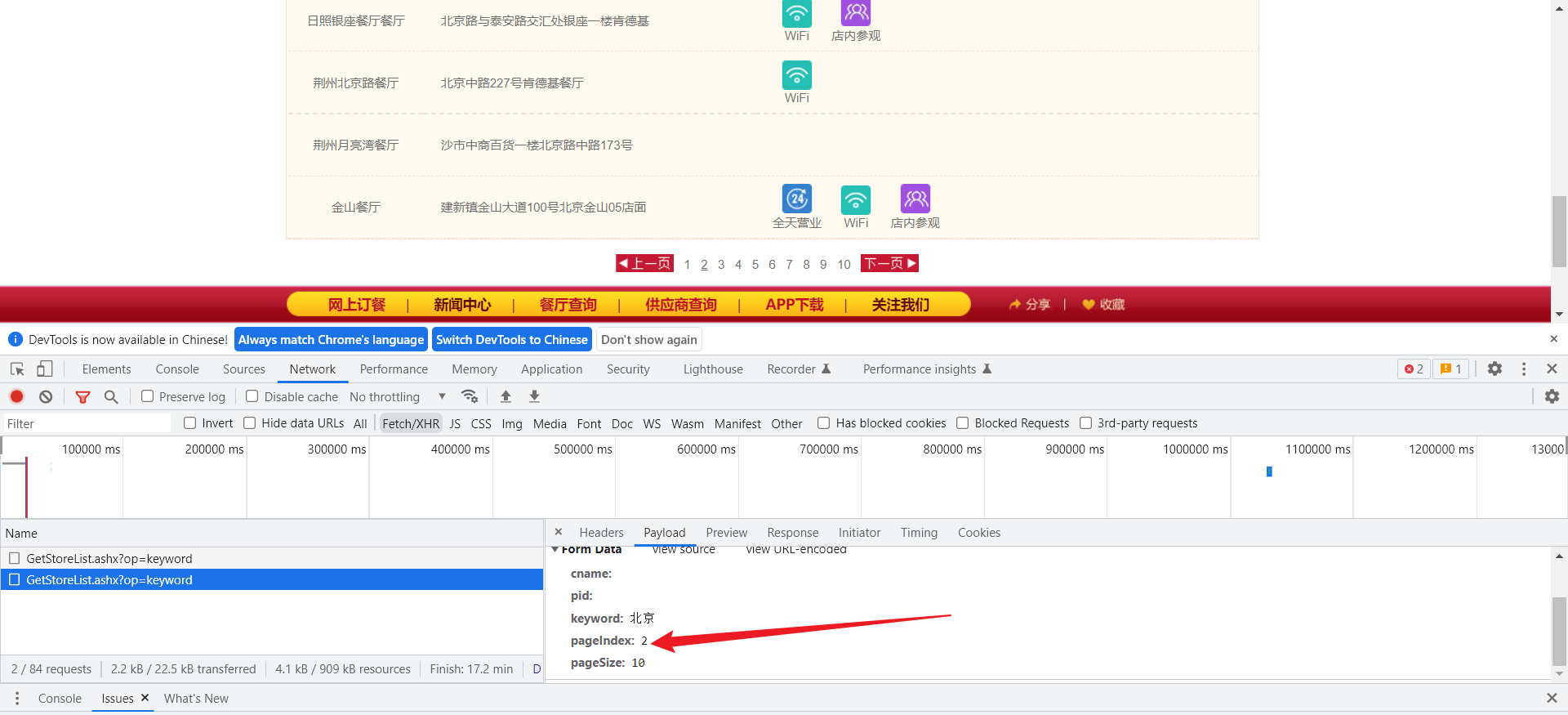
每次循环只需要改变的是pageIndex参数的值,因为数据要求是字符串类型,所以避免出错给其强制转换一下
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
for page in range(1, 9):
data = {
'cname': '',
'pid': '',
'keyword': '北京',
'pageIndex': str(page),
'pageSize': '10',
}
# data参数是post方法中处理参数动态化的参数
response = requests.post(url=url, headers=headers, data=data)
page_text = response.json()
for dic in page_text['Table1']:
title = dic['storeName']
addr = dic['addressDetail']
print('第', page, '页:', title, addr)
关注专栏查看更多详细内容