1、为什么要设置headers?
在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
2、 headers在哪里找?
谷歌或者火狐浏览器,在网页面上点击右键,–>检查–>剩余按照图中显示操作,需要按Fn+F5刷新出网页来
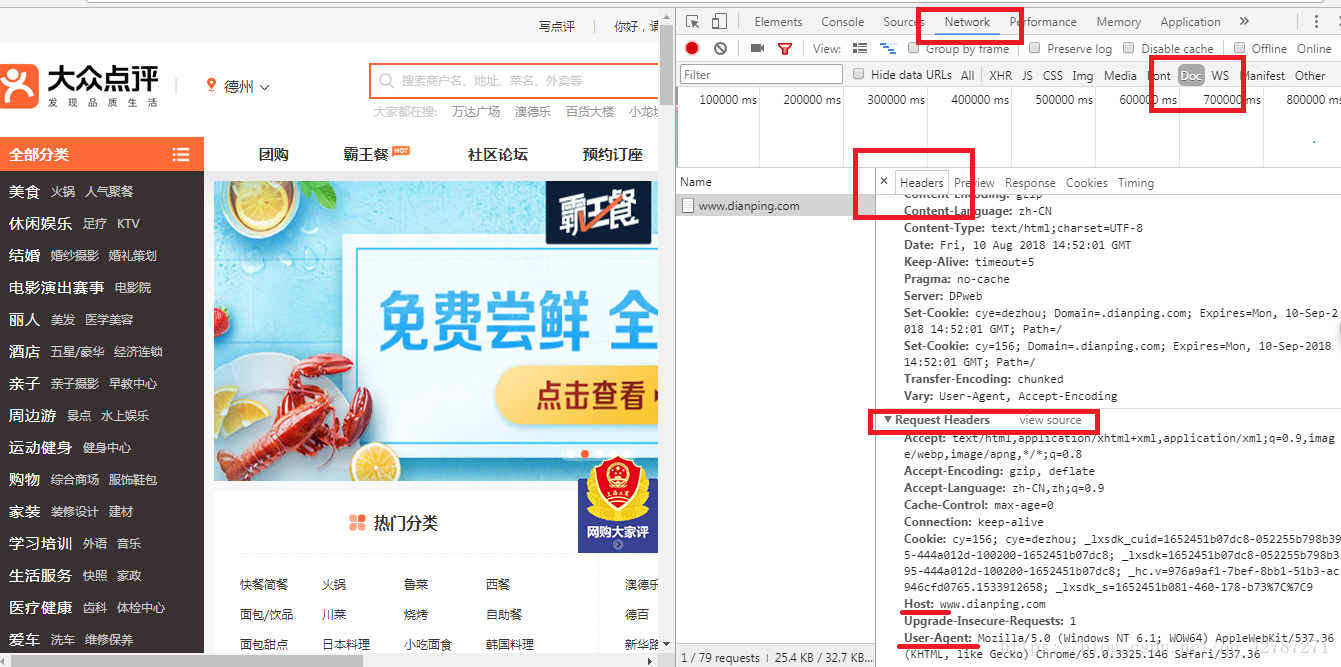
3、headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
import requests
res=requests.get("http://www.dianping.com/",headers=headers)
print(res.text)
#输出会出现:抱歉!页面无法访问....这就是限制爬虫了
#解决方法:加入headers,在requests.get(headers=headers)里面,添加headers
#构建headers
import requests
headers={
"Host": "www.dianping.com"
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
res=requests.get("http://www.dianping.com/",headers=headers)
print(res.text)