1、前言
Darknet网络属于是一个比较经典的网络,主要借鉴了VGG16网络以及Resnet网络的残差模块,在取其精华,去其糟粕后,构建了Darknet19以及经典的Darknet53。其中Darknet19是YOLOv2网络的主干特征提取网络,Darknet53是YOLOV3网络的主干特征提取网路,但是基本思路比较类似。
2、网络整体结构
Darknet19的基本网络结构如下图所示:
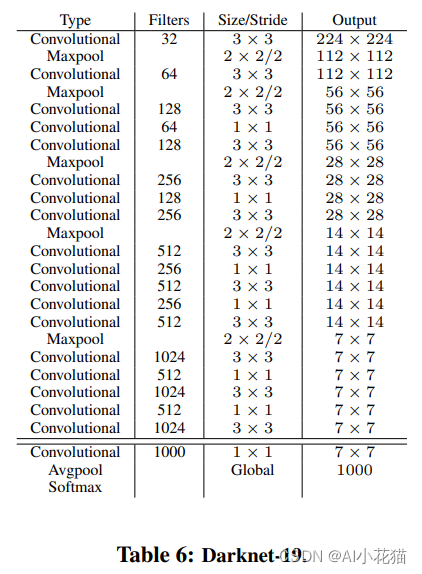
出自文章:YOLO9000: Better, Faster, Stronger
从上图可以看出,网络属于比较plain的,仅仅靠网络层级堆叠搭建的网络,网络均采用3*3或者1*1的卷积进行堆叠,卷积过程不进行下采样,只进行通道之间的转换。下采样使用Maxpool进行,从网络结构可以看出,总共下采样了5次,因此特征图相对于原始输入的图像而言变为原来的1/32。网络整体没有FC层,直接使用1*1的卷积代替,使用avgpool后使用softmax得到分类分数。
Darknet53的基本网络结构如下图所示:

出自文章:YOLOv3: An Incremental Improvement
YOLOV3的主干网络为Darknet53,取出其中的stage 3,4,5的特征图进行特征融合和增强。
Darknet53的相较于Darknet19,网络层数增加了34层,因此借鉴残差网络解决退化问题的方案,在不同的stage均使用残差结构。每个stage都对应不同个数的残差模块,不过Darknet53的残差模块不同于ResNet的残差模块,仅使用两个连续堆叠的卷积(1*1和3*3的卷积块),残差边也没有通道上的变化,只有identity block直接与主线相加即可。
3、代码实现
代码实现以Darknet53为例:
因为模型中有很多相似的结构【1*1卷积+3*3卷积+残差连接】,因此将这部分单独封装成一个Resblock块,方便进行调用,代码实现如下所示。
class ResBlock(nn.Module):
def __init__(self, inplanes, planes): # inplanes是每一个大的stage的输入,此处主要是下采样之前的输入卷积通道,planes是残差模块中两次卷积的输出通道数
super(ResBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes[0], kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes[0])
self.relu1 = nn.LeakyReLU(0.1)
self.conv2 = nn.Conv2d(planes[0], planes[1], kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes[1])
self.relu2 = nn.LeakyReLU(0.1)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu2(out)
out += residual
return out
接下来就是Darknet53的构成,输入原始图像,经过一次标准的Conv+BN+Relu后,正式进入我们所谓的5个stage,每个stage都是由【stride为2的下采样卷积+N*Resblock构成】,然后通过avgpool+FC+sofmax完成整个网络。
class DarkNet(nn.Module):
def __init__(self, layers, num_classes=1000):
super(DarkNet, self).__init__()
self.inplanes = 32
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(self.inplanes)
self.relu1 = nn.LeakyReLU(0.1)
self.layer1 = self._make_layer([32, 64], layers[0])
self.layer2 = self._make_layer([64, 128], layers[1])
self.layer3 = self._make_layer([128, 256], layers[2])
self.layer4 = self._make_layer([256, 512], layers[3])
self.layer5 = self._make_layer([512, 1024], layers[4])
self.layers_out_filters = [64, 128, 256, 512, 1024]
self.avgpool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Linear(in_features=1024, out_features=num_classes)
self.softmax = nn.Softmax(dim=1)
# 进行权值初始化
self._initialize_weights()
def _initialize_weights(self):
"""
权重初始化
"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# 卷积层使用 kaimming 初始化
nn.init.kaiming_normal_(
m.weight, mode='fan_out', nonlinearity='relu')
# 偏置初始化为0
if m.bias is not None:
nn.init.constant_(m.bias, 0)
# 批归一化层权重初始化为1
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 全连接层权重初始化
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def _make_layer(self, planes, blocks):
layers = []
# pooling,stride=2, k=3
layers.append(nn.Conv2d(self.inplanes, planes[1], kernel_size=3, stride=2, padding=1, bias=False))
layers.append(nn.BatchNorm2d(planes[1]))
layers.append(nn.LeakyReLU(0.1))
# resblock
self.inplanes = planes[1]
for i in range(blocks):
layers.append(ResBlock(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def darknet53():
model = DarkNet([1, 2, 8, 8, 4], num_classes=2)
return model
if __name__ == '__main__':
import torch
from torchsummary import summary
darknet = DarkNet(layers=[1, 2, 8, 8, 4])
inputs = torch.rand((1, 3, 224, 224))
res = darknet(inputs)
print(res.shape)
summary(darknet, (3, 224, 224), device='cpu')
4、猫狗分类实战
基于Darknet53网络完成猫狗分类训练,训练代码如下:
from backbone.Darknet import darknet53
from dataset.cat_dog_data import CatDogDataset, data_transform
import torch
import torch.optim as optim
from backbone.vgg import VGG
import torch
if __name__ == '__main__':
import torchvision
BATCH_SIZE = 8
LEARNING_RATE = 0.001
EPOCH = 50
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
train_root = r'D:\personal\data\public_data\catsdogs\train'
val_root = r'D:\personal\data\public_data\catsdogs\val'
torchvision.datasets.ImageFolder
train_cat_dog = CatDogDataset(img_root=train_root, transform=data_transform['train'], is_train=True)
val_cat_dog = CatDogDataset(img_root=val_root, transform=data_transform['val'], is_train=False)
train_dataloader = torch.utils.data.DataLoader(train_cat_dog, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_cat_dog, batch_size=1, shuffle=False, num_workers=0)
net = darknet53()
net = net.to(device)
cost = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=LEARNING_RATE, momentum=0.9, weight_decay=5e-4)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer)
for epoch in range(EPOCH):
net.train()
avg_loss = 0.0
cnt = 0
for images, labels in train_dataloader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
pred = net(images)
loss = cost(pred, labels)
avg_loss += loss.data
cnt += 1
print('[{}/{}],loss={},avg_loss={}'.format(epoch, EPOCH, loss, avg_loss / cnt))
loss.backward()
optimizer.step()
scheduler.step(avg_loss)
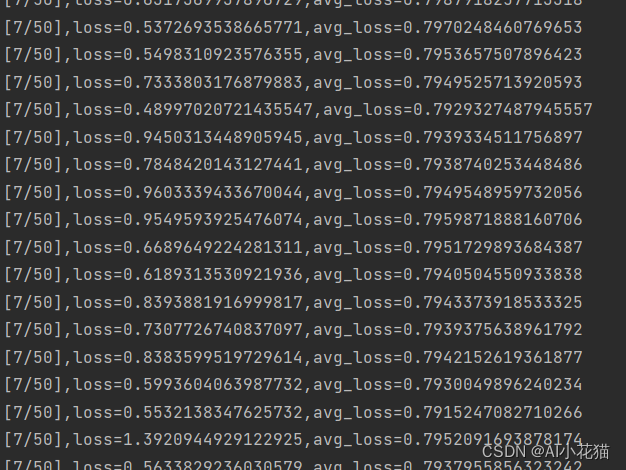
实测运行如下所示:
Darknet网络就介绍到这里了,如果错误,敬请指正!
–END–