训练YOLO-V3
第一步、数据集准备
确定数据集
当做练手的数据集,要有标准性,而且不能太大。
搜索了一番后,我决定用VOC2007数据集,压缩包的大小只有450M。
为什么不用VOC2005与VOC2006?
因为VOC2005与VOC2006数据标注规则与之后的VOC不同,且图片是png格式的,比jpg图片占用磁盘空间更大。
VOC2007 ~ VOC2012的数据集标注规则是一样的,且图片是jpg格式的,占用磁盘小。在VOC2007 ~ VOC2012中,数据集的大小是随年份递减的。所以我选择了标注规范, 尺寸又小的VOC2007作为练手的数据集。
VOC2007数据介绍
VOC2007数据集有20类图片:
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
有bounding box标注,有像素级类别标注,像素级实例标注。适合训练目标检测,语义分割,实例分割的网络。
数据集包含五个文件夹:Annotations,ImageSets,JPEGImages,SegmentationClass,SegmentationObject:

Annotations/ 里面是图片的xml标注文件,其文件名前缀为6为数字,与JPEGImages/ 下的图片名称相对应。
打开一个xml文件,可以看见以下内容,对与目标检测来说,我们只要关系物体的类别和bonding box,对应图中红色框的内容。

ImageSets/ 下有三个文件夹(对于VOC2007只有三个,年份更高的哟有四个文件夹):

这三个文件夹都包含用于检索训练集和测试集的txt文件。Main/ 包含所有分类数据集,Segmentation/ 专门用于语义分割或实例分割,Layout/ 的作用我尚未搞清楚。
Main/ 下有很多txt文件。如果做多类别分类的话,用train.txt和val.txt即可,它们分别包含训练集的图片和验证集的图片名称。如果做单类别二分类的话,用类似aeroplane_train.txt,aeroplane_trainval.txt这种带类别名称的文件,它以1代表正样本,-1代表负样本。
第二步、准备工作
1. 因为darknet不支持VOC的xml标注格式,所以首先需要把VOC的xml标注文件转化为darknet支持的txt格式
把下载好的VOCdevkit目录复制到darknet目录下。
修改darknet/scipts/voc_label.py(这个脚本用来把VOC的xml格式转化为darknet支持的txt格式):
修改两处即可:
# 把
sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
# 修改为
sets=[('2007', 'train'), ('2007', 'val')]# 注释掉最后两行代码
#os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
在darknet的根目录下打开终端,运行:
python scripts/voc_label.py运行完后,会在 darknet/VOCdevkit/VOC2007/ 目录下生成 label 文件夹,里面有darknet支持的txt格式的标注文件。并在darknet根目录下生成2007_train.txt和2007_val.txt文件,用来索引图片。
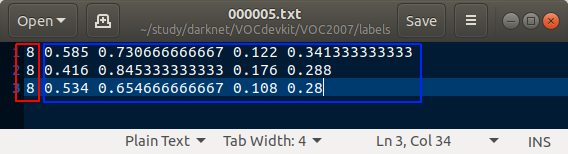
这是转换后的txt标注文件,第一列是标签,8对应的是chair(对应关系看voc_label.py);后四列是归一化后的bonding box坐标。

这是2007_train.txt,包含所有训练集图片的绝对路径。
2. 修改 cfg/voc.data 文件

2. 修改data/names 文件

注意这里的顺序要跟scipts/voc_label.py里面的clasees的顺序一致:

3. 修改cfg/yolov3-voc.cfg

修改如图所示的3~7行即可。
实际训练中,每批训练的个数=batch/subvisions,根据自己GPU显存进行修改。
我的GPU显存为4GB,能跑上图所示的配置。
第三步:训练
从头开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg 利用预训练权重训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg yolov3.weights -clear其中,yolov3.weights -clear是官方提供的权重文件,可由此下载:
wget https://pjreddie.com/media/files/yolov3.weights-clear使程序中net->seen为0,net->seen代表训练次数。
第四步:测试
./darknet detect cfg/yolov3-voc.cfg backup/yolov3-voc_900.weights data/dog.jpg训练过程中,会保存一些权重文件,在backup/ 文件夹下可以找到。
yolov3-voc_900.weights代表训练了900个批次的模型权重。
由于训练时间过短,而且没有预训练(yolo用了ImageNet数据集预训练了一周),自己从头训练的模型几乎没有效果。
所以,实际项目中用yolo做目标检测的话,最好用官方提供的预训练模型。
第五步:同步至Github(可选)
git add cfg/voc.data
git add cfg/yolov3-voc.cfg
git add cfg/yolov3.cfg
git add scripts/voc_label.py
git add 2007_train.txt 2007_val.txt
git commit -m "voc2007 train"
git push -u origin master