一、论文信息
论文名称:DeepFake-Adapter: Dual-Level Adapter for DeepFake Detection
作者团队:
项目主页:https://github.com/rshaojimmy/DeepFake-Adapter(代码暂未开源)
二、动机与创新
动机:目前的deepfake检测模型泛化能力差,将其归因于过拟合于低级的伪造模式,现有的 deepfake 检测方法仅关注低级别的伪造特征,例如局部纹理、混合边界或频率信息,这些特征可能无法有效对抗看不见或低质量的伪造,而伪造检测也应该关注高级语义,例如人脸风格和形状,某些人脸操作方法会改变这些语义,例如FaceForensics++数据集中的DeepFake和FaceSwap。这些高级语义可以用来进行深度伪造检测,因为它们可以抵御低级特征的变化,使用高级语义可以提高deepfake检测方法的泛化能力,使它们在对抗看不见或低质量的伪造方面更有效。
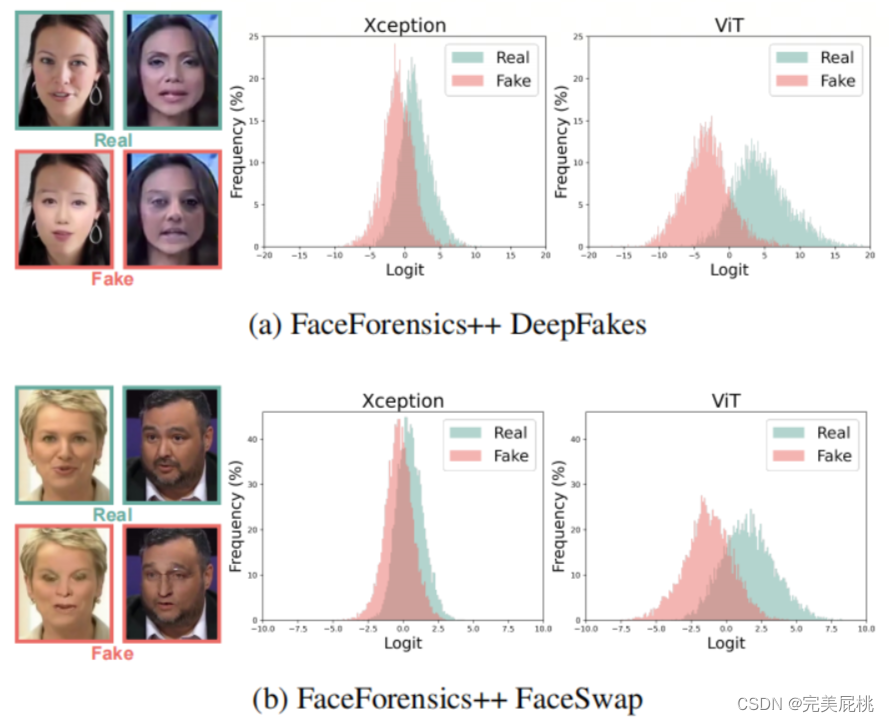
创新:提出了一个针对深度伪造模型的高效的参数微调方法,考虑ViT模型能够提取到高级的语义信息,本研究利用参数微调方法微调ViT模型用于深度伪造检测。
三、方法
提出的模型有N个阶段,每一层都包括一个预训练的ViT,其参数在训练期间被冻结;以及一个Deepfake-adapter,其具有用于快速适应的可训练的参数。每个阶段都包含预训练ViT的MHSA和MLP层。ViT的patch embedding层也被冻结。该方法是一个双层Adapter,包括两种类型的Adapter:全局感知瓶颈适配器 (GBA) 和局部感知空间适配器 (LSA)。
 1、Globally-aware Bottleneck Adapter (GBA)
1、Globally-aware Bottleneck Adapter (GBA)
1)ViT模型的MHSA层倾向于提取图像的全局信息,例如面部融合边界,GBA被设计为瓶颈结构保存以用于快速适应的参数,想通过在每个MHSA模块之后插入瓶颈结构快速训练模型,GBA与ViT的MLP层平行。
2)瓶颈结构由向下投影线性层 (DOWN) 和向上投影线性层 (UP) 组成,中间有一个 ReLU 层,用于非线性变换(类似LoRA)。 瓶颈结构的目的是保存参数以便快速适应,并权衡全局低级特征在适应过程中的重要性。
3)在两个投影层之后添加了一个可学习的比例函数(SC),以自适应地权衡全局低级特征在适应过程中的重要性。 GBA 的整个适应过程旨在使用更多全局低级伪造特征(例如混合边界)调整预训练的 ViT,以帮助进行深度伪造检测。



2、Locally-aware Spatial Adapter(LSA)
1) 与卷积神经网络(CNN)相比,ViT 不太能根据局部低级特征区分真脸和假脸,所以引入了局部感知的空间适配器(LSA)来适应更多的低级伪造特征,如纹理,LSA由LSA-H(head)和LSA-I(interaction)组成。
2)LSA-H,将CNN的卷积运算整合到ViT中。它与 ViT 的patch embedding层平行,尝试从一开始就捕获更多的输入图像的局部低级伪造特征。其使用标准 CNN 作为基础网络来提取基础特征图,由三个 Convolution-batchnorm-Relu 区块和一个最大池化层组成。然后,使用三个类似的卷积块来提取多个中间特征图。中间特征图由各种金字塔分辨率、1/r1、1/r2 和 1/r3 分辨率组成,对应于原始输入图像的大小。将特征投射到相同的维度 D 中,然后连接成一个表示为 fspa 的特征向量。 在此基础上,LSA-H 聚合了具有不同空间分辨率的特征,捕获细粒度和局部低级别的伪造特征,例如纹理,这些特征对于检测深度伪造很重要。

3)LSA-I,LSA 的交互部分捕获局部低级伪造,这些伪造通过一系列交叉注意力与预先训练的 ViT 中的特征进行交互。在第 i 阶段,第一次交互是通过 feature fispa 和 ViT fivit 一开始的特征之间的多头交叉注意力 (MHCA) 进行的。在此 MHCA 中,归一化的 fivit 作为Q,标准化 fispa 被视为K和V。这种互动的目的是通过聚合具有不同空间分辨率的特征来捕捉细粒度和丰富的局部伪造,通过使整个适应过程能够意识到局部低级伪造品,该方法旨在提高深度伪造方法的泛化能力。一旦在第 i 阶段通过 ViT 的整个向前过程获得特征 fi+1vit,则在 ViT 结束时通过在 fispa 和 fi+1vit 之间进行多头交叉注意力 (MHCA) 来进行第二次互动。在这个 MHCA 中,通过将标准化 fispa 作为查询并将标准化 fi+1vit 作为键和值来切换 K、Q、V。 第二次交互有助于进一步完善功能,并将deepfake数据的全球和本地伪造线索整合到检测过程中。

四、实验结果
作者提出的方法能够区分真实和虚假的图像或视频,也可以泛化到没见过的样本或降级的样本中检测深度伪造。GBA 和 LSA 模块需要训练的参数要少得多(不到原始大型预训练的 ViT 的 20%)。这使得所提出的方法可以轻松扩展到各种deepfake数据集,并且可以部署在经济实惠的GPU机器上进行训练
 训练集: FF++ 数据集的DF和FS,作者认为这两种操作类型改变了高级语义,风格和形状等。
训练集: FF++ 数据集的DF和FS,作者认为这两种操作类型改变了高级语义,风格和形状等。
本文提出的方法不仅在检测高质量伪造品方面表现良好,而且在检测模糊、压缩和噪声的低质量伪造品方面具有区别性和鲁棒性。




