目录:
- 简介
- FaceSwap 介绍
- FaceSwap 原理
- 如何在移动端部署换脸
1. 简介
2018 年,AI 最火的应用是什么?换脸当之无愧的霸榜!同时衍生出一个词汇:DeepFake (深度造假).

各种 deepfake 框架层出不穷,从 fakeapp, faceswap 到 deepfacelab,各种新奇好玩的视频百花齐放,从哔哩哔哩到 pornhub. 不过这些框架的使用门槛非常高,第一需要搭建复杂的运行环境,第二需要高端的硬件支持。目前国内有不少关于 deepfake 的主题社区,如 deepfakes 中文站:http://www.deepfake.com.cn,里面有各种使用教程和调参手册。

直到 2019 年,ZAO 火了,整个朋友圈都在 AI 换脸。ZAO,是隶属于 MoMo 公司的一款产品,使用门槛非常低,只需要一张清晰的人脸图片,即可成功换脸,除了一些角度融合,表情僵硬,边缘处理等问题,整体效果已经非常不错了。虽然比不上系统训练几十个小时(俗称炼丹)的成品,但是这个产出速度,不得不大写的服。

换脸在中国已经被禁了,因为其存在诸多人伦,安全等因素。主要是肖像权侵犯、隐私侵犯、不良视频传播、损害原创作品等问题。而且目前甚至连声音都可以模仿造假,一旦被不法分子利用,后果不堪设想。比如 AI 换脸曾被利用制作 YH 视频,ZAO 条款里收集人脸信息等。下图是 ZAO app 之前的安全问题:

2. FaceSwap 介绍
笔者之前有基于 FaceSwap 做过换脸相关的应用,而且 FaceSwap 在 github 上的更新与讨论十分热烈,可以说完全看不到趋冷的迹象。
之前我们做训练的时候,因为是在区块链公司,公司有自己的矿场和显卡。所以就是几个同事跟着一懂硬件的哥们打下手,从组装显卡,调风扇,功率,装系统到搭建环境。最终弄好了四台 4 卡的机器,弄坏了 2 张卡,之前由于区块链的火爆,显卡价格飙升,当时 N 卡差不多 2000 一张。整个过程大概用了 2 周,跑完后,因为主机没有显示器,所以使用 TeamViewer 远程控制。每天就是用爬虫爬网络视频,然后训练模型。要达到两张人脸训练的模型 lose (丢失率)到 0.1 以下,一台 4 张 N 卡的机器大概需要 20 几个小时。最终出来的效果并不是那么理想,换好的人脸视频色差大,并且一些特定的表情有跳帧现象。然后就不断地进行调参。Faceswap 支持人脸检测框架 (MTCNN, Dlib)、使用的显卡数、后处理效果 (边缘融合,高斯模糊,色差等) 等选项。
FaceSwap github: https://github.com/deepfakes/faceswap。对于 FaceSwap 文档,我这边简单提炼了一下:
- 2.1 硬件环境
- 强大的 CPU,笔记本电脑的 CPU 通常可以运行该软件,但其速度不足以以合理的速度进行训练;
- 强大的 GPU,当前,完全支持 Nvidia GPU。 plaidML 部分支持 AMD 和 AMD 显卡;
- 强大的耐心。
- 2.2 支持的操作系统
window 7, window 8, window 10, linux, mac os,以上所有的系统都必须是 64 位,才能支持运行。
- 2.3 软件环境
git, python, Conda3, CUDA, CUDNN, Tensorflow-gpu, OpenCV, FFMpeg, FaceSwap 客户端。
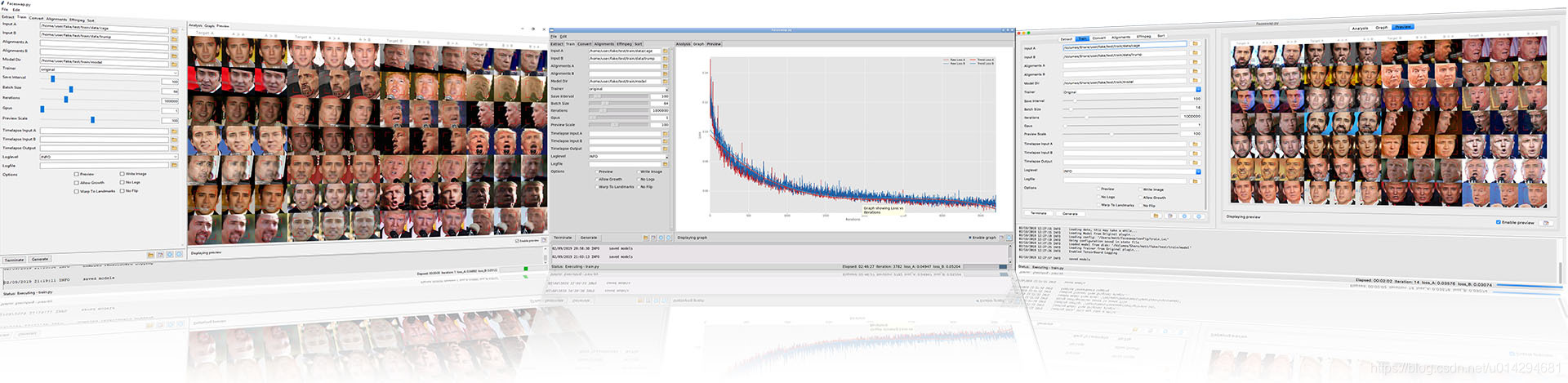
- 2.4 流程简介
- 抽取:在你设置的文件夹中,运行 pythonfaceswap.py extract。 这将从 src 文件夹中拍摄照片并将脸部提取到提取文件夹中,也可以是从视频中,视频的话就是使用 FFMpeg 将视频分割成一帧帧再处理。
- 训练:从你的设置文件夹中,运行 python faceswap.py train。 这将从两个包含两张面孔图片的文件夹中拍摄照片,并训练一个将保存在 models 文件夹中的模型(这个时间非常长,占整个流程的 90% 以上)。
- 转换:在你的设置文件夹中,运行 python faceswap.py convert。 这将从原始文件夹中拍摄照片,并将新面孔应用到修改后的文件夹中。
你可以通过命令行来执行这些操作,也可以使用 GUI 程序快速使用。
3. FaceSwap 原理
代码结构:

流程图:
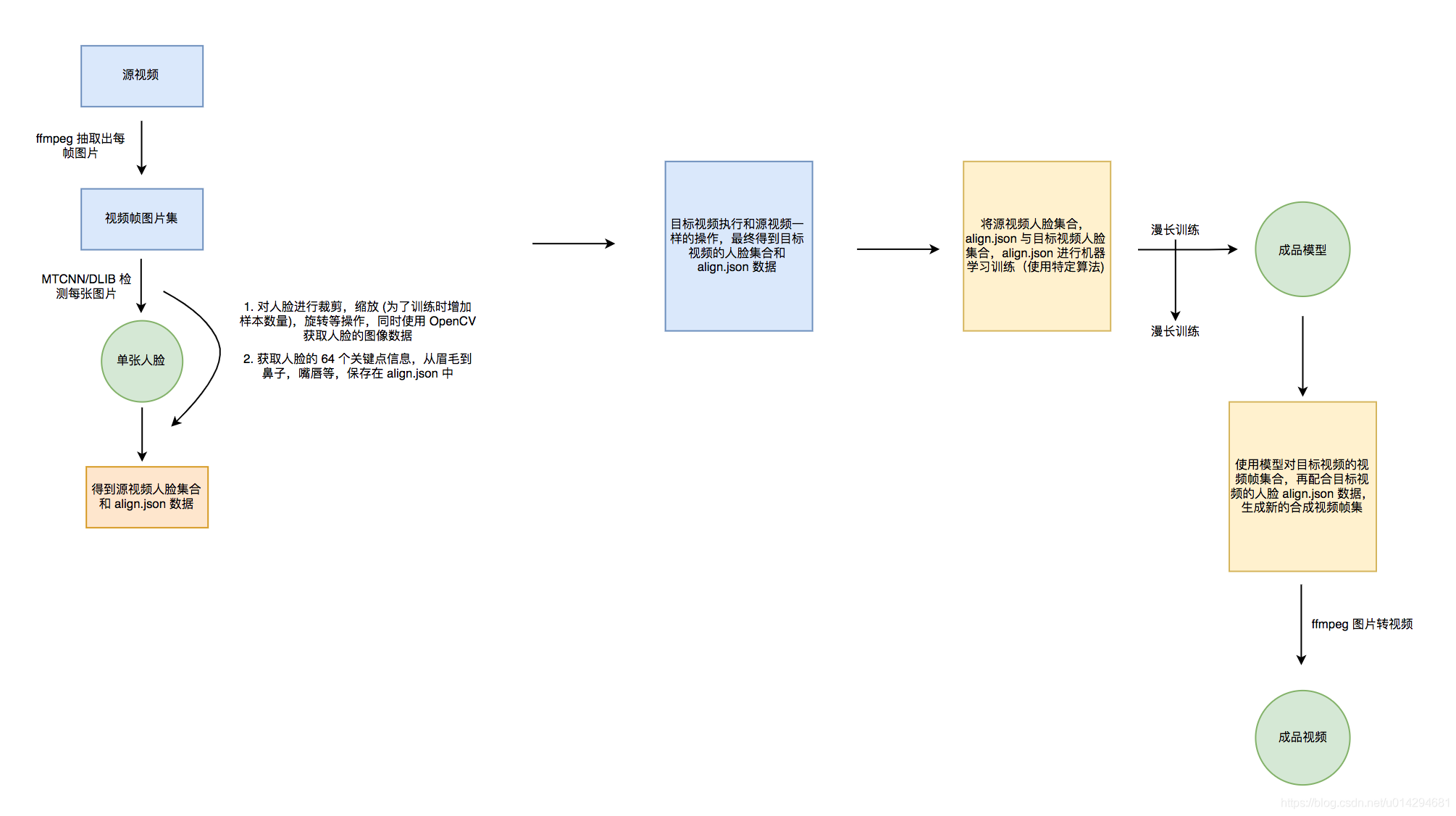
- 3.1 数据前处理
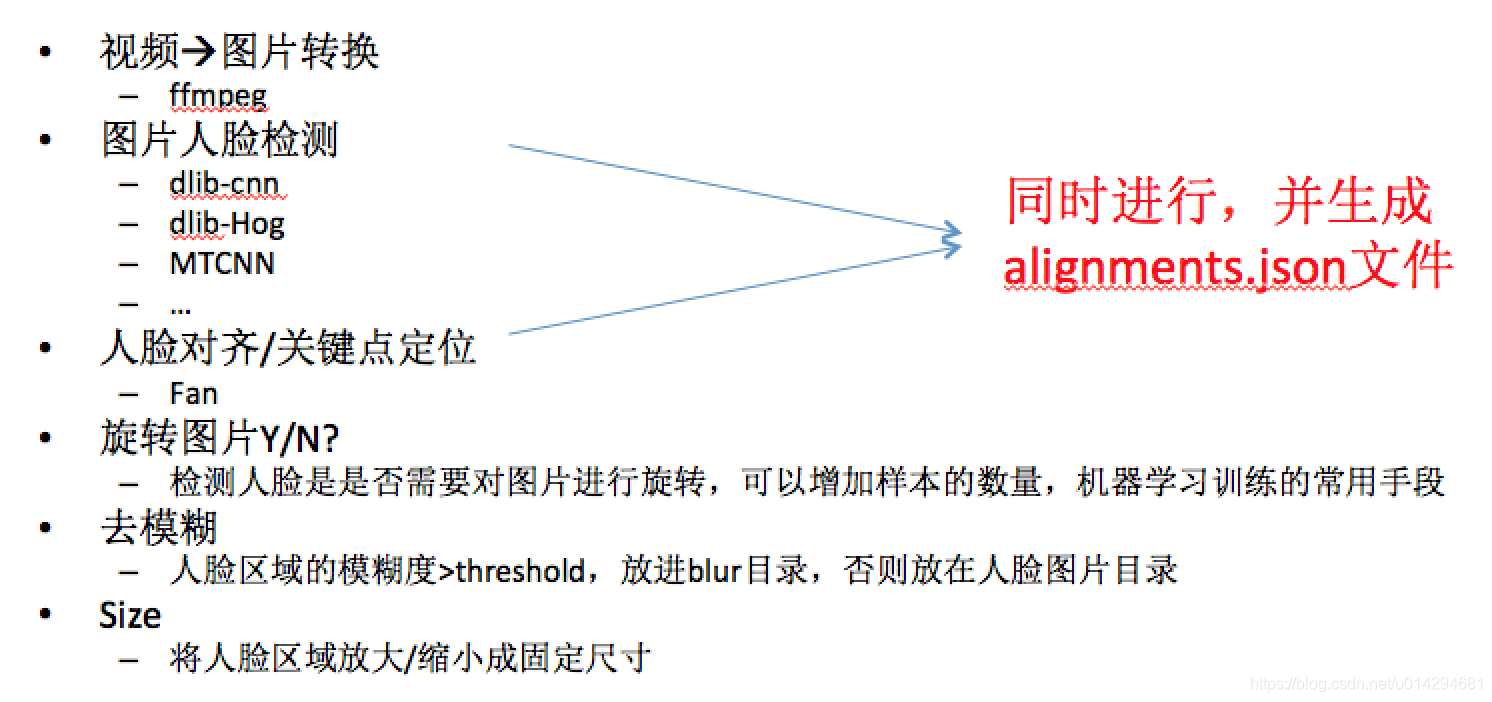

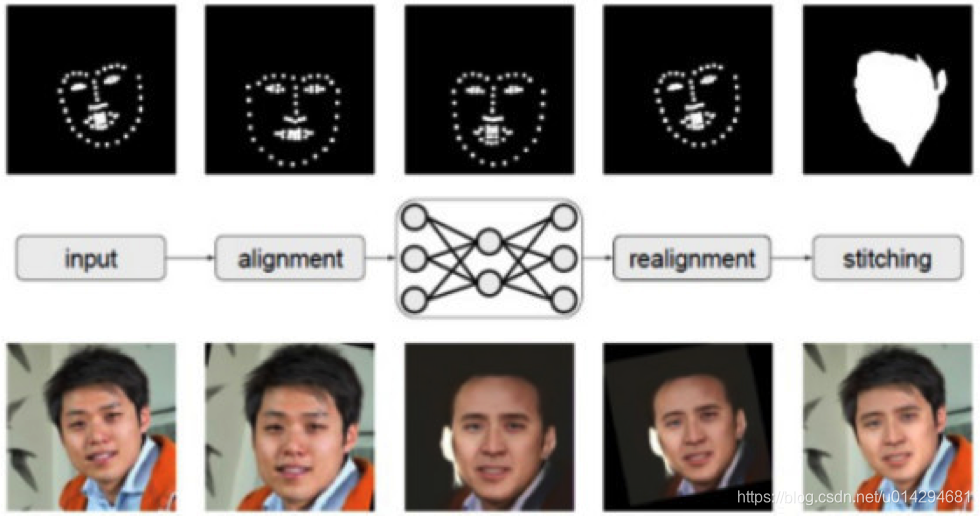
- 3.2 训练

- 3.3 转换

- 3.4 视频合成

- 3.5 出现的问题
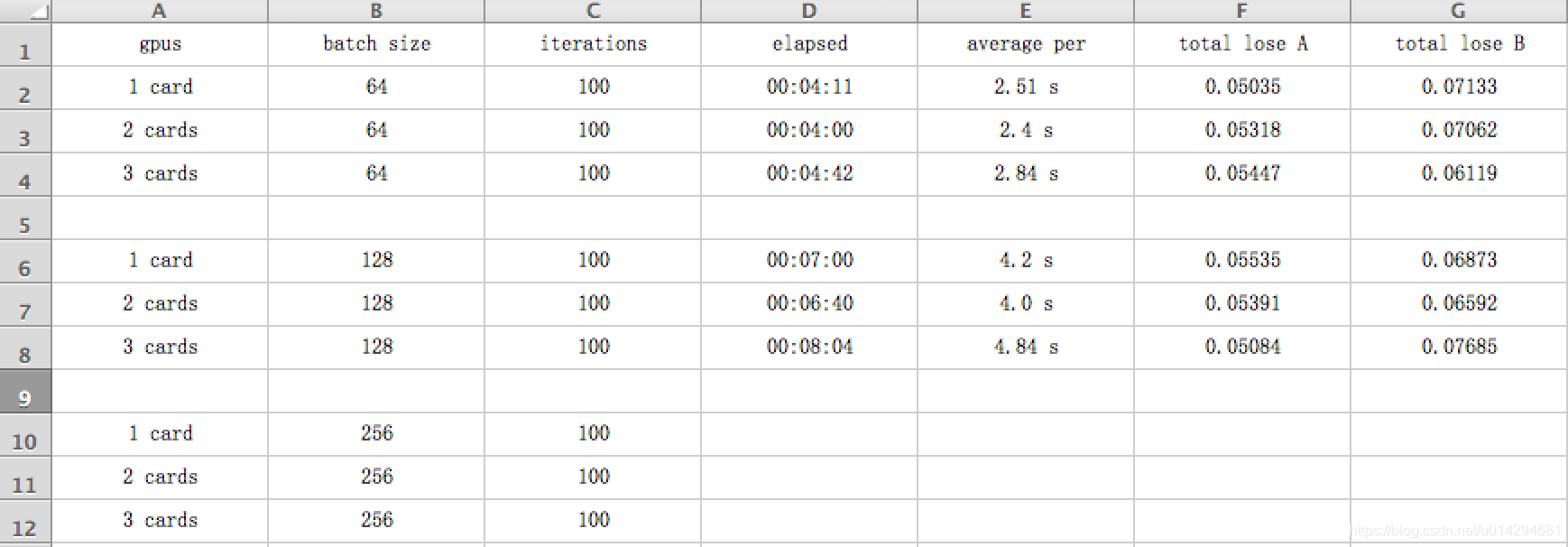
我们使用 FaceSwap 部署完环境,在 GUI 上运行,对一些视频素材使用 N 卡机器训练了 20 几个小时,最终达到的效果并不理想。原因有以下几个点:
- 1. 源视频问题:如果源视频色彩,清晰度,脸型,角度等和目标视频相差过大,最终出来的效果,在合成的图片边缘,角度出现了严重的不协调。
- 2. 耗时严重:经过各种调参,发现多卡并行与打卡运行,在 GPU 训练时,速度相差不大,查找原因是多卡需要更多的数据交换操作。
- 3. 内存占用高:内存占用非常高,导致显卡发热严重,最终使用脚本来控制显卡的使用率、功率,风扇温度等。
最终产出了一个数据:
4. 如何在移动端部署换脸
整个换脸过程包括数据前处理,训练,合成。其中训练和合成在后端来处理,而移动端只需要做数据前处理。
数据前处理包括:视频录制,人脸检测,人脸旋转 & 缩放处理,关键点数据生成,人脸图像保存。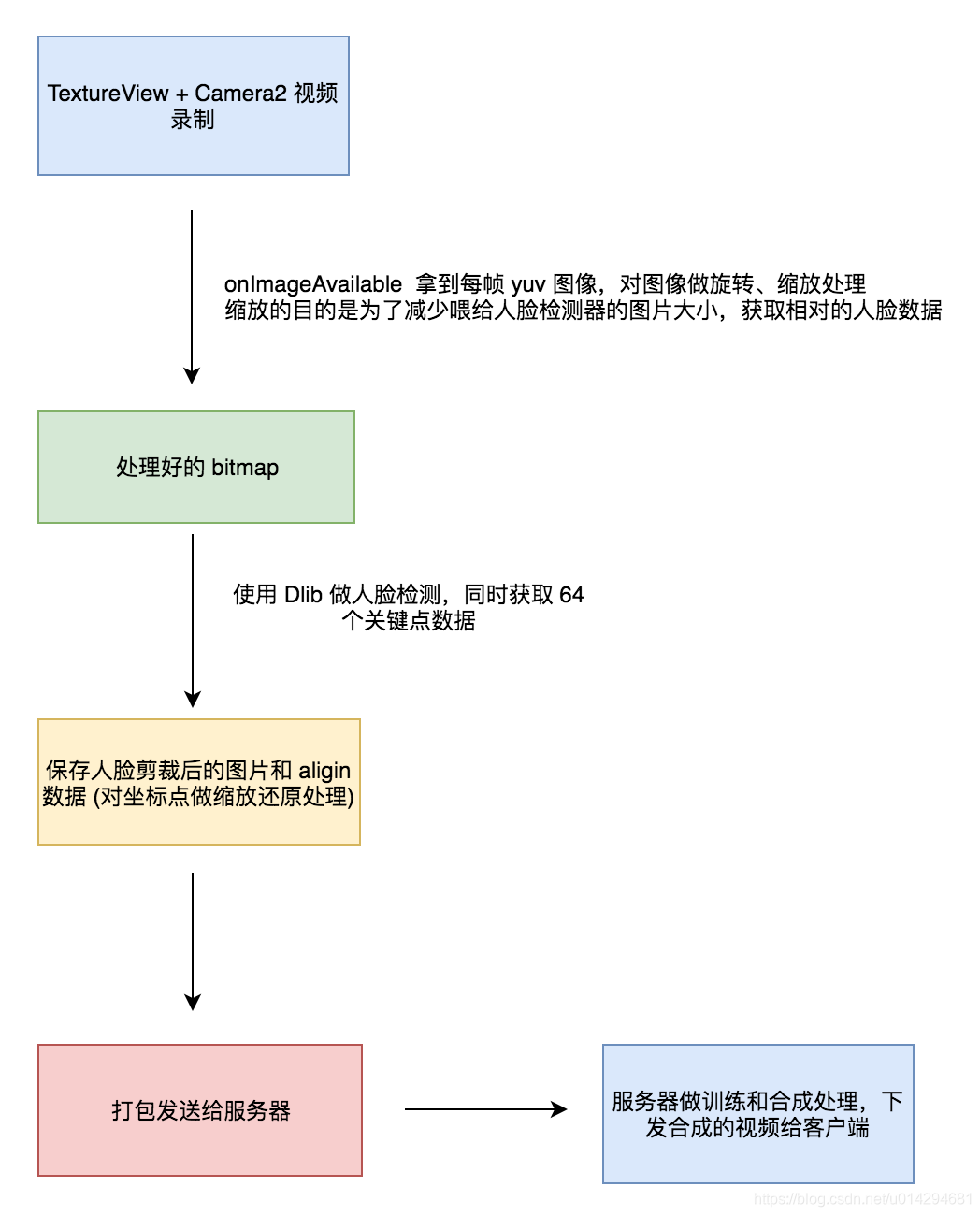
下面来一次对这几个步骤做一下分析。
- 4.1 视频录制与图片处理
视频录制使用 TextureView + Camera2 进行,目前做的处理是实时的识别人脸。
// 设置每帧回调,比 textureView.getBitmap() 更快,采用 YUV_420_888
imageReader = ImageReader.newInstance(previewSize.getWidth(),
previewSize.getHeight(), ImageFormat.YUV_420_888, 2);
imageReader.setOnImageAvailableListener(new OnImageAvailableListener() {
@Override
public void onImageAvailable(ImageReader imageReader) {
final int width = previewSize.getWidth();
final int height = previewSize.getHeight();
if (rgbBytes == null) {
rgbBytes = new int[width * height];
}
final Image image = imageReader.acquireLatestImage();
if (image == null)
return;
if (onCamera2FrameListener == null)
throw new RuntimeException("Set OnCamera2FrameListener first!");
// 此处需要加上限制,否则缓冲区会出问题
if (isProcessingImage) {
image.close();
return;
}
isProcessingImage = true;
Trace.beginSection("imageAvailable");
taskExecutor.execute(new Runnable() {
@Override
public void run() {
try {
final Plane[] planes = image.getPlanes();
fillBytes(planes, yuvBytes);
yRowStride = planes[0].getRowStride();
final int uvRowStride = planes[1].getRowStride();
final int uvPixelStride = planes[1].getPixelStride();
ImageUtils.convertYUV420ToARGB8888(yuvBytes[0], yuvBytes[1], yuvBytes[2],
width, height, yRowStride, uvRowStride, uvPixelStride, rgbBytes);
// 先根据图片数据创建位图
Bitmap rgbBitmap = Bitmap.createBitmap(width, height, Config.ARGB_8888);
rgbBitmap.setPixels(rgbBytes, 0, width, 0, 0, width, height);
// YUV 图像是旋转过的
final Bitmap bitmap = ImageUtils.adjustPhotoRotation(rgbBitmap, 360 - sensorOrientation);
rgbBitmap.recycle();
// 先执行完图片处理
backgroundHandler.post(new Runnable() {
@Override
public void run() {
onCamera2FrameListener.onImageAvailable(bitmap);
}
});
image.close();
isProcessingImage = false;
} catch (Exception e) {
e.printStackTrace();
}
}
});
Trace.endSection();
}
}, backgroundHandler);YUV 图像处理,先科普下 YUV:
RGB 模型是目前常用的一种彩色信息表达方式,它使用红、绿、蓝三原色的亮度来定量表示颜色。该模型也称为加色混色模型,是以RGB三色光互相叠加来实现混色的方法,因而适合于显示器等发光体的显示。
YUV,分为三个分量,"Y" 表示明亮度 (Luminance或Luma),也就是灰度值;而 "U" 和 "V" 表示的则是色度 (Chrominance或 Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
与我们熟知的 RGB 类似,YUV 也是一种颜色编码方法,主要用于电视系统以及模拟视频领域,它将亮度信息 (Y) 与色彩信息 (UV) 分离,没有 UV 信息一样可以显示完整的图像(是不是写错了),只不过是黑白的,这样的设计很好地解决了彩色电视机与黑白电视的兼容问题。并且,YUV 不像 RGB 那样要求三个独立的视频信号同时传输,所以用 YUV 方式传送占用极少的频宽。
比如常见的手机直播流程:
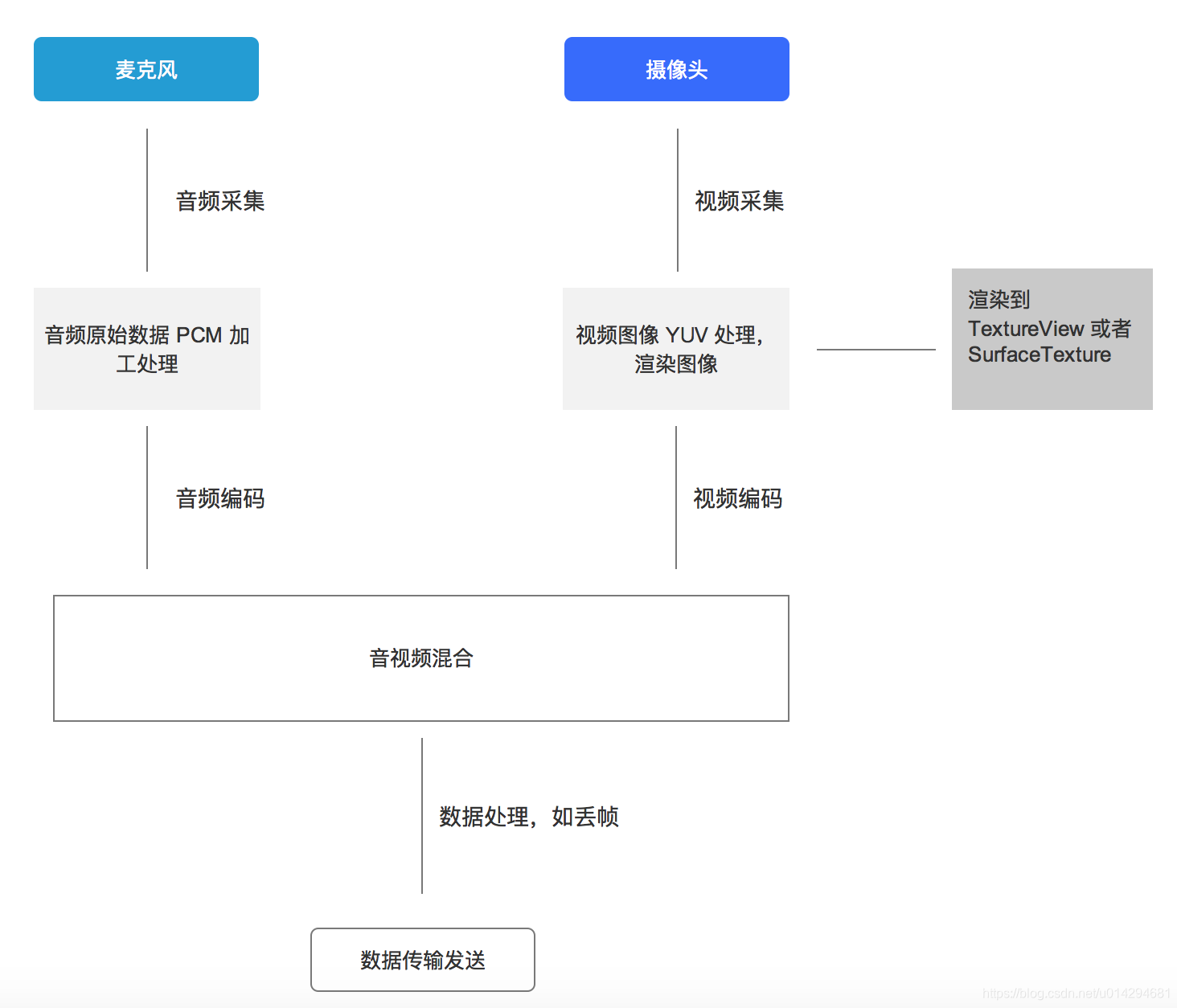
目前 Android 本身提供了 YUVImage,用于摄像头预览回调的每一帧 Nv21 数据做 jpeg 压缩,不过这个 convertNv21ToJpeg 函数存在着内存泄漏。目前主流的处理方式还是通过 JNI,网上 YUV 的旋转,转换算法还是非常多的。
#include <jni.h>
#include <stdio.h>
#include <stdlib.h>
#include "rgb2yuv.h"
#include "yuv2rgb.h"
#define IMAGEUTILS_METHOD(METHOD_NAME) \
Java_com_wayne_face_ImageUtils_##METHOD_NAME // NOLINT
#ifdef __cplusplus
extern "C" {
#endif
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertYUV420SPToARGB8888)(
JNIEnv* env, jclass clazz, jbyteArray input, jintArray output,
jint width, jint height, jboolean halfSize);
JNIEXPORT void JNICALL IMAGEUTILS_METHOD(convertYUV420ToARGB8888)(
JNIEnv* env, jclass clazz, jbyteArray y, jbyteArray u, jbyteArray v,
jintArray output, jint width, jint height, jint y_row_stride,
jint uv_row_stride, jint uv_pixel_stride, jboolean halfSize);
JNIEXPORT void JNICALL IMAGEUTILS_METHOD(convertYUV420SPToRGB565)(
JNIEnv* env, jclass clazz, jbyteArray input, jbyteArray output, jint width,
jint height);
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertARGB8888ToYUV420SP)(
JNIEnv* env, jclass clazz, jintArray input, jbyteArray output,
jint width, jint height);
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertRGB565ToYUV420SP)(
JNIEnv* env, jclass clazz, jbyteArray input, jbyteArray output,
jint width, jint height);
#ifdef __cplusplus
}
#endif
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertYUV420SPToARGB8888)(
JNIEnv* env, jclass clazz, jbyteArray input, jintArray output,
jint width, jint height, jboolean halfSize) {
jboolean inputCopy = JNI_FALSE;
jbyte* const i = env->GetByteArrayElements(input, &inputCopy);
jboolean outputCopy = JNI_FALSE;
jint* const o = env->GetIntArrayElements(output, &outputCopy);
if (halfSize) {
ConvertYUV420SPToARGB8888HalfSize(reinterpret_cast<uint8_t*>(i),
reinterpret_cast<uint32_t*>(o), width,
height);
} else {
ConvertYUV420SPToARGB8888(reinterpret_cast<uint8_t*>(i),
reinterpret_cast<uint8_t*>(i) + width * height,
reinterpret_cast<uint32_t*>(o), width, height);
}
env->ReleaseByteArrayElements(input, i, JNI_ABORT);
env->ReleaseIntArrayElements(output, o, 0);
}
JNIEXPORT void JNICALL IMAGEUTILS_METHOD(convertYUV420ToARGB8888)(
JNIEnv* env, jclass clazz, jbyteArray y, jbyteArray u, jbyteArray v,
jintArray output, jint width, jint height, jint y_row_stride,
jint uv_row_stride, jint uv_pixel_stride, jboolean halfSize) {
jboolean inputCopy = JNI_FALSE;
jbyte* const y_buff = env->GetByteArrayElements(y, &inputCopy);
jboolean outputCopy = JNI_FALSE;
jint* const o = env->GetIntArrayElements(output, &outputCopy);
if (halfSize) {
ConvertYUV420SPToARGB8888HalfSize(reinterpret_cast<uint8_t*>(y_buff),
reinterpret_cast<uint32_t*>(o), width,
height);
} else {
jbyte* const u_buff = env->GetByteArrayElements(u, &inputCopy);
jbyte* const v_buff = env->GetByteArrayElements(v, &inputCopy);
ConvertYUV420ToARGB8888(
reinterpret_cast<uint8_t*>(y_buff), reinterpret_cast<uint8_t*>(u_buff),
reinterpret_cast<uint8_t*>(v_buff), reinterpret_cast<uint32_t*>(o),
width, height, y_row_stride, uv_row_stride, uv_pixel_stride);
env->ReleaseByteArrayElements(u, u_buff, JNI_ABORT);
env->ReleaseByteArrayElements(v, v_buff, JNI_ABORT);
}
env->ReleaseByteArrayElements(y, y_buff, JNI_ABORT);
env->ReleaseIntArrayElements(output, o, 0);
}
JNIEXPORT void JNICALL IMAGEUTILS_METHOD(convertYUV420SPToRGB565)(
JNIEnv* env, jclass clazz, jbyteArray input, jbyteArray output, jint width,
jint height) {
jboolean inputCopy = JNI_FALSE;
jbyte* const i = env->GetByteArrayElements(input, &inputCopy);
jboolean outputCopy = JNI_FALSE;
jbyte* const o = env->GetByteArrayElements(output, &outputCopy);
ConvertYUV420SPToRGB565(reinterpret_cast<uint8_t*>(i),
reinterpret_cast<uint16_t*>(o), width, height);
env->ReleaseByteArrayElements(input, i, JNI_ABORT);
env->ReleaseByteArrayElements(output, o, 0);
}
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertARGB8888ToYUV420SP)(
JNIEnv* env, jclass clazz, jintArray input, jbyteArray output,
jint width, jint height) {
jboolean inputCopy = JNI_FALSE;
jint* const i = env->GetIntArrayElements(input, &inputCopy);
jboolean outputCopy = JNI_FALSE;
jbyte* const o = env->GetByteArrayElements(output, &outputCopy);
ConvertARGB8888ToYUV420SP(reinterpret_cast<uint32_t*>(i),
reinterpret_cast<uint8_t*>(o), width, height);
env->ReleaseIntArrayElements(input, i, JNI_ABORT);
env->ReleaseByteArrayElements(output, o, 0);
}
JNIEXPORT void JNICALL
IMAGEUTILS_METHOD(convertRGB565ToYUV420SP)(
JNIEnv* env, jclass clazz, jbyteArray input, jbyteArray output,
jint width, jint height) {
jboolean inputCopy = JNI_FALSE;
jbyte* const i = env->GetByteArrayElements(input, &inputCopy);
jboolean outputCopy = JNI_FALSE;
jbyte* const o = env->GetByteArrayElements(output, &outputCopy);
ConvertRGB565ToYUV420SP(reinterpret_cast<uint16_t*>(i),
reinterpret_cast<uint8_t*>(o), width, height);
env->ReleaseByteArrayElements(input, i, JNI_ABORT);
env->ReleaseByteArrayElements(output, o, 0);
}
- 4.2 人脸检测与关键点获取
注:人脸检测需要依靠机器学习的推断 (inference),所以需要依赖:
implementation 'org.tensorflow:tensorflow-android:+'class CameraFragment : Fragment(), TextureView.SurfaceTextureListener, Camera2Wrapper.OnCamera2FrameListener {
private val mContext: Context? = FaceDetectApp.sAppContext
/**
* TextureView
*/
private var mTextureView: AutoFitTextureView? = null
/**
* 人脸框和关键点控件
*/
private var mBoundingBoxView: BoundingBoxView? = null
/**
* MTCNN 进行人脸检测,检测效果比 DLib 更佳,目前返回的数据包括人脸的 (x, y, w, h) 和 5 个关键点
*/
private var mtcnn: MTCNN? = null
/**
* 相机包装类
*/
private var mCamera2Wrapper: Camera2Wrapper? = null
/**
* Handler 对象
*/
private val mHandler = android.os.Handler()
/**
* 构造器
*/
init {
if (Constants.LOG_DEBUG)
Log.i(TAG, "CameraFragment construct")
}
override fun onCreateView(inflater: LayoutInflater, container: ViewGroup?, savedInstanceState: Bundle?): View? {
return inflater.inflate(R.layout.fragment_camera, container, false)
}
override fun onViewCreated(view: View, savedInstanceState: Bundle?) {
mTextureView = view.findViewById(R.id.textureView)
mCamera2Wrapper = Camera2Wrapper(activity, mTextureView)
mCamera2Wrapper?.setOnCamera2FrameListener(this)
mBoundingBoxView = view.findViewById(R.id.boundingBoxView)
val switchCameraBtn: View = view.findViewById(R.id.camera_switch_View)
switchCameraBtn.setOnClickListener { mCamera2Wrapper?.switchCamera() }
init_MTCNN()
}
override fun onResume() {
super.onResume()
mCamera2Wrapper?.startBackgroundThread()
when (mTextureView?.isAvailable()) {
true -> {
mCamera2Wrapper?.openCamera(
mTextureView?.getWidth() ?: 0,
mTextureView?.getHeight() ?: 0
)
}
false -> {
mTextureView?.setSurfaceTextureListener(this)
}
}
}
override fun onPause() {
super.onPause()
mCamera2Wrapper?.closeCamera()
mCamera2Wrapper?.stopBackgroundThread()
}
override fun onDestroy() {
super.onDestroy()
mCamera2Wrapper?.release()
}
override fun onSurfaceTextureAvailable(surface: SurfaceTexture?, width: Int, height: Int) {
mCamera2Wrapper?.openCamera(width, height)
}
override fun onSurfaceTextureSizeChanged(surface: SurfaceTexture?, width: Int, height: Int) {
mCamera2Wrapper?.configureTransform(width, height)
}
override fun onSurfaceTextureUpdated(surface: SurfaceTexture?) {
}
override fun onSurfaceTextureDestroyed(surface: SurfaceTexture?): Boolean {
return false
}
override fun onImageAvailable(bitmap: Bitmap) {
if (mtcnn != null) {
Thread(Runnable {
Log.d(TAG, "begin detect faces")
val results: Vector<Box>?
// 同步 this || this@CameraFragment
synchronized(this@CameraFragment) {
results = mtcnn?.detectFaces(bitmap, 40)
}
Log.d(TAG, "end detect faces")
if (results != null && results.size > 0) {
mHandler.postAtFrontOfQueue {
if (AppUtils.isSecureContextForUI(activity)) {
mBoundingBoxView?.setResults(results)
}
}
} else {
bitmap.recycle()
}
}).start()
}
}
private fun init_MTCNN() {
Thread(Runnable {
Log.d(TAG, "initMTCNN_DLib begin")
/**
* 拷贝 DLib 需要的模型到 SD 卡
*/
/**
* 拷贝 DLib 需要的模型到 SD 卡
*/
val faceShapeModelPath = Constants.getFaceShapeModelPath()
if (!File(faceShapeModelPath).exists()) {
FileUtils.copyFileFromAssetsToOthers(
mContext,
Constants.FACE_SHAPE_MODEL_PATH, faceShapeModelPath
)
}
mtcnn = MTCNN(activity?.assets)
Log.d(TAG, "initMTCNN_DLib end")
}).start()
}
companion object {
private const val TAG = "CameraFragment"
fun newInstance(): CameraFragment {
return CameraFragment()
}
}
}
由于是之前的公司项目,所以部分代码不方便开源,我这边写了一个小 demo,感兴趣的同学可以前往:https://github.com/kuangzhongwen/MTCNN_FaceDetect
