一、论文信息
论文名称:AVoiD-DF: Audio-Visual Joint Learning for Detecting Deepfake
作者团队:

二、主要创新
以前的方法仅侧重单模态的伪造,即使有多模态的数据也只是将音频信号当做监督信号,忽略了音频被伪造的可能。
-
提出一个新的多模态基准数据集DefakeAVMiT,其包含足够多的视频和音频伪造内容,两个模态均有伪造。
-
提出了一种检测Deepfake的视听联合学习方法(AVoiD-DF),其利用视听不一致性进行多模态伪造检测。
三、方法
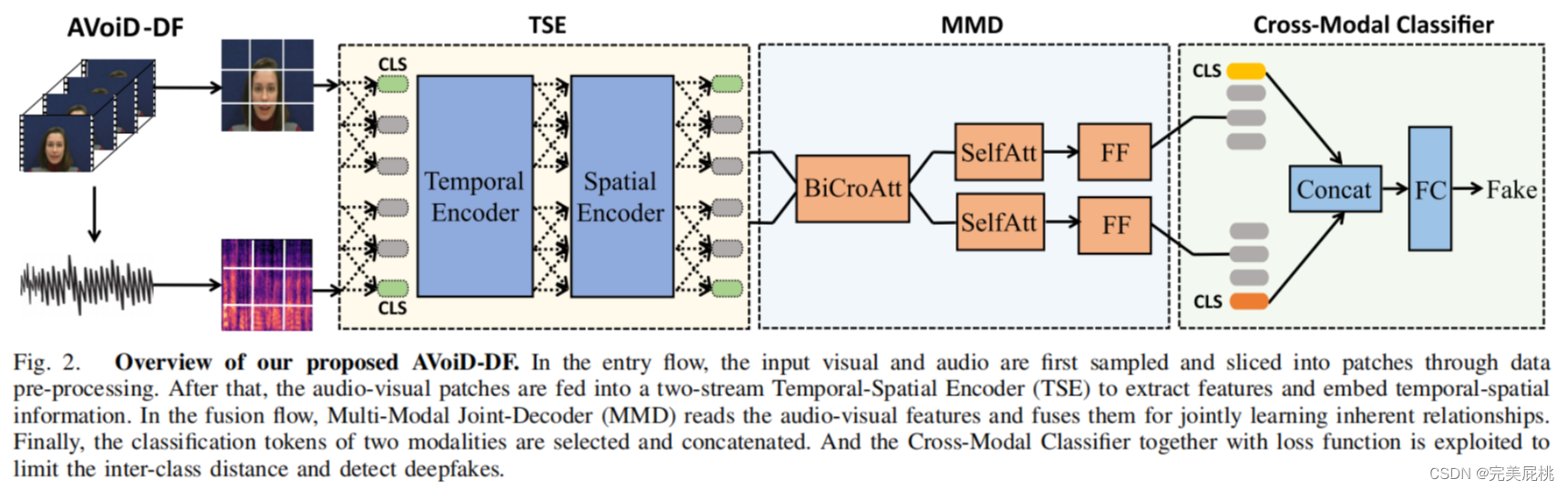
AVoiD-DF包含三个关键部分:时空编码器TSE、多模态联合解码MMD、Cross-Modal Classifier利用MMD的输出进行多模态分类。
1、时空编码器TSE
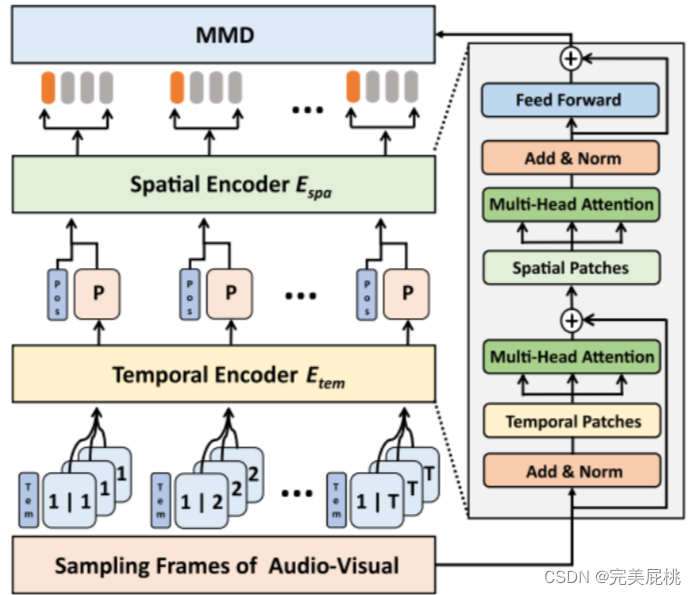
该模块包括串联的两个transformer编码器。首先对音频和视频模态进行统一的帧采样和预处理, 第一个时序编码器模型编码的是同一窗口的时间步长与时间嵌入之间的交互信息。 第二个空间编码器产生的编码表示每个时间索引的空间特征。 因此,它对应于时空信息。 然后两种模态的特征将并行送到MMD进行多模态融合。
2、多模态联合解码MMD

使用MMD模块进行模态融合。 输入的视觉和声音嵌入块将是通过两个并行解码器通道馈送。 每个通道都有一个双向交叉注意 (BiCroAtt) 模块,之后有自注意力块和前馈层。 该模块主要使用双向交叉注意力BiCroAtt 使两种模态之间的信息共享、联合学习。
BiCroAtt:
 self-attention:
self-attention:

3、跨模态分类器Cross-Modal Classifier
结合MMD的最终输出,进行最后的多模态分类。
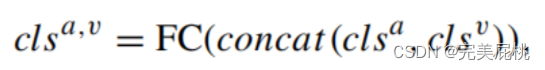
4、损失函数
1)对比损失Lcon:设置为最大化假标签和真实标签的分类标记的相似度。音视匹配的为正样本,其余为负样本。

2)交叉熵损失
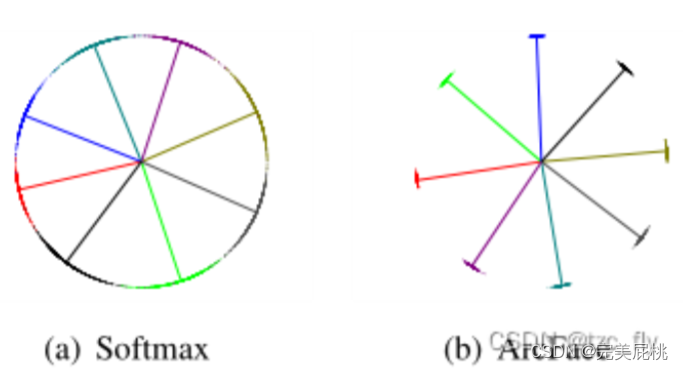
3)Additive Angular Margin Loss(ArcfaceLoss)加性角裕度损失:人脸识别
4)总体损失如下:
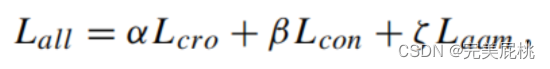
四、数据集:DefakeAVMiT
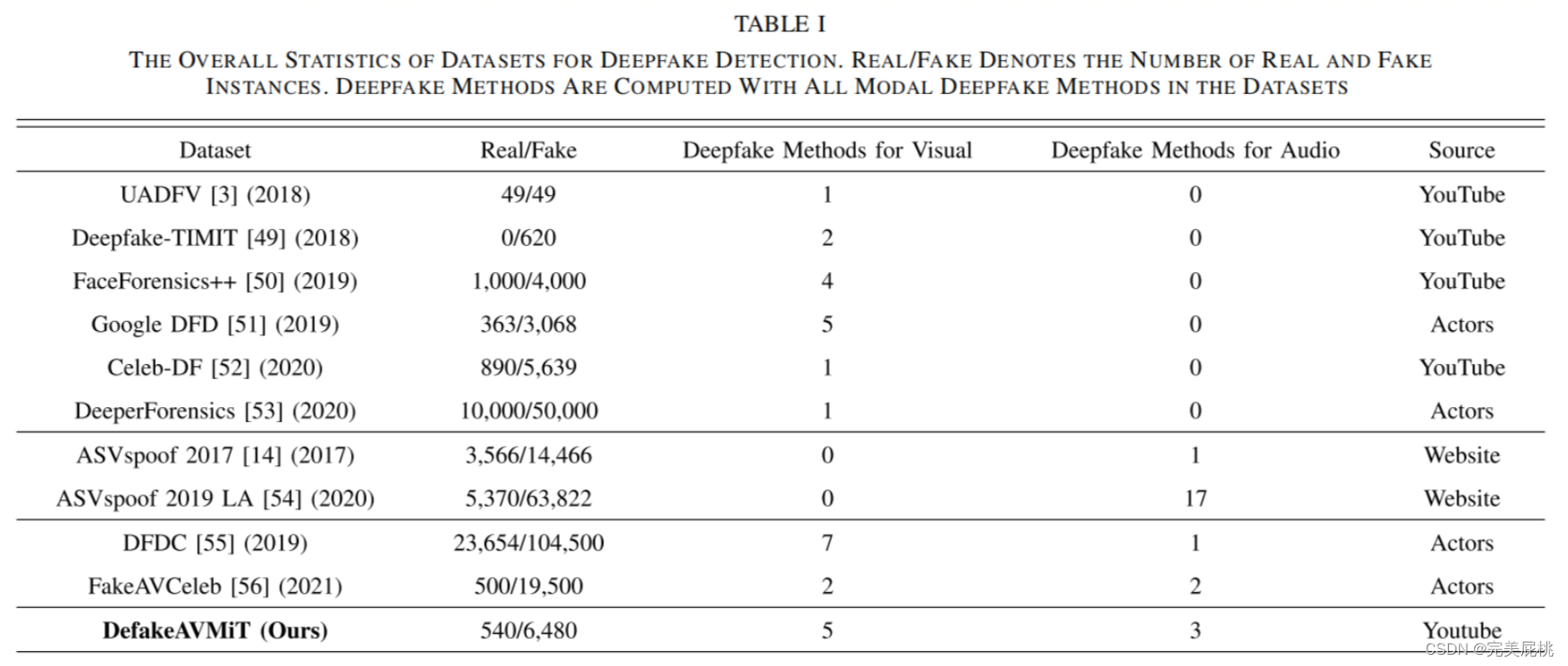 共8种伪造生成技术,5种视觉生成技术、3种语音生成技术。真实视频来自VidTIMIT数据集,虚假视频由Faceswap(换脸) 、DeepFaceLab (高质量换脸)、Wave2Lip(生成口型同步的talking face)、EVP(音频驱动画面)、PC-AVS(生成口型同步的talking face)、SV2TTS(实时语音克隆,不同说话人生成相同语音音频) 、Voice Replay(语音重放,使用真实人物预先录制的音频对应虚假身份)、AV exemplar autoencoders(将任何输入语音转换为视听流,输入模仿特定目标的语音)。
共8种伪造生成技术,5种视觉生成技术、3种语音生成技术。真实视频来自VidTIMIT数据集,虚假视频由Faceswap(换脸) 、DeepFaceLab (高质量换脸)、Wave2Lip(生成口型同步的talking face)、EVP(音频驱动画面)、PC-AVS(生成口型同步的talking face)、SV2TTS(实时语音克隆,不同说话人生成相同语音音频) 、Voice Replay(语音重放,使用真实人物预先录制的音频对应虚假身份)、AV exemplar autoencoders(将任何输入语音转换为视听流,输入模仿特定目标的语音)。
 五、实验结果
五、实验结果
1、检测性能
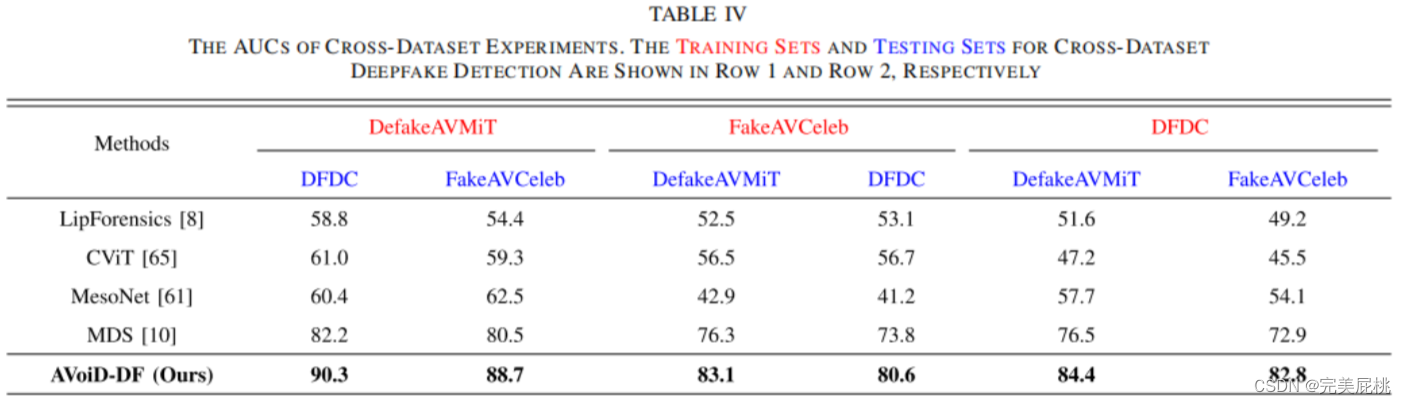
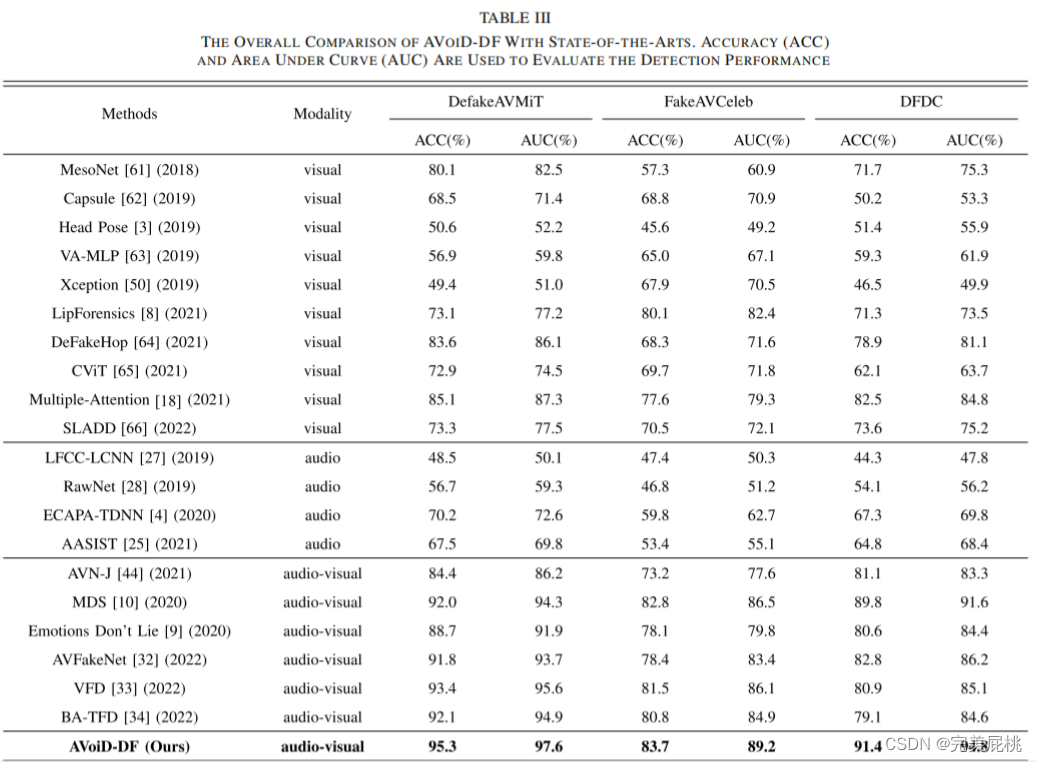 2、泛化性
2、泛化性
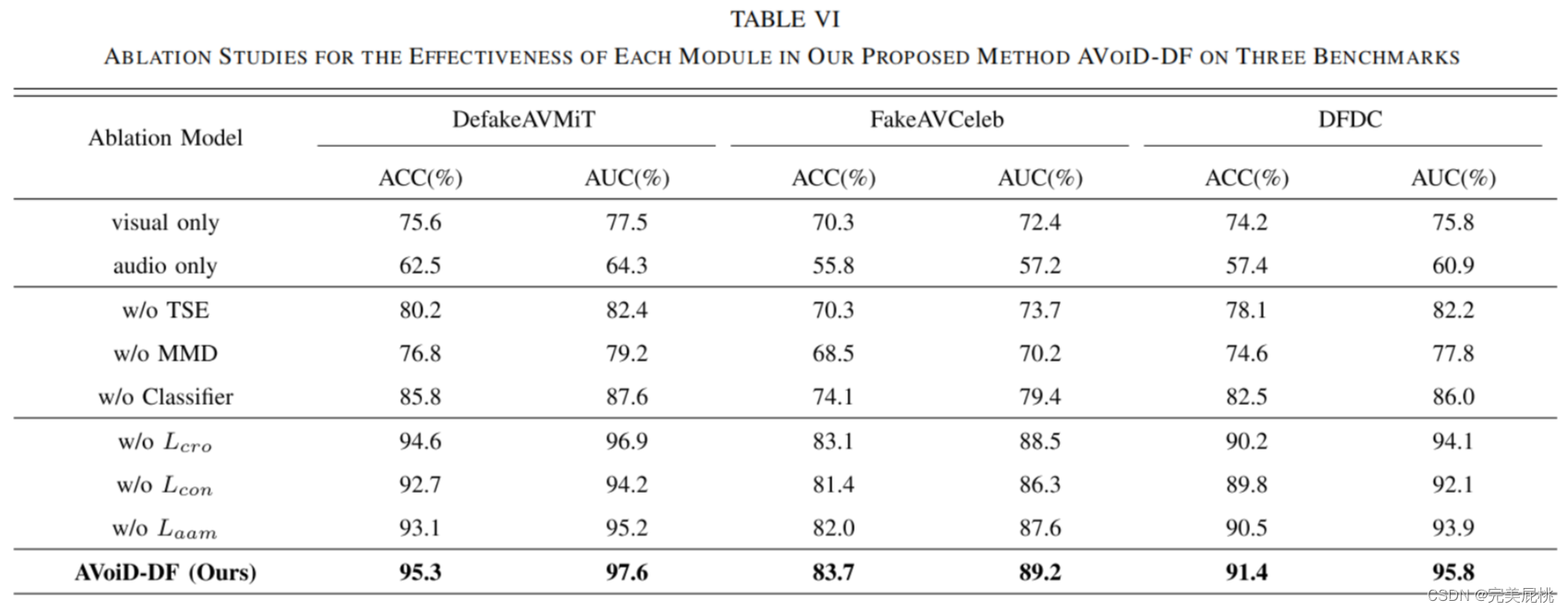
 3、消融实验
3、消融实验