前言
本期内容为对Nerf神经辐射场的网络结构以及其使用的体渲染技术的一个介绍。文章会同步更新到公众号 AI知识物语 ,并且后续有需要也会更新响应的讲解视频到B站,同名 出门吃三碗饭
开讲!
简单介绍Nerf
Nerf是2020年的一篇ECCV论文,其贡献就是通过提供2维信息来渲染3维复杂的真实场景。
在介绍Nerf网络结构以及体渲染近似前,我们需要知道下面的知识:
(1)Nerf流程:
输入数据(空间、方向信息)—>通过MLP网络—>输出对应的数据(点密度、颜色信息)—>对各个点、光线进行渲染—>渲染后输出像素值—>对比预测的像素值和实际像素值的损失值,并优化—>网络训练好后,可以得到各个角度的视图(视图也就是各个像素值组成的)

(2)光学知识、拍照原理:
1:物体反射光线—>反射光线进入小孔—>反射光线打在感光面上—>通过处理形成像素—>像素最终组成图像
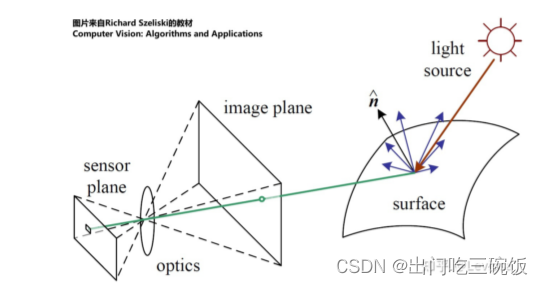
2:光线由一个个粒子组成,也可以叫光子,其有很多属性,对像素值影响比较大的两个属性是密度和颜色(也叫发光强度)。
颜色: 发光强度越大,对像素贡献越大;
密度:可以假设粒子A密度为1,粒子B穿过A的时候会被反弹,为0.7,大部分的粒子B在经过A后会消失(准确说是散射掉),为0的话,则认为A是透明,B可以完全顺利通过。再通俗点,A密度越大,光线通过A后减弱越多(可以是变暗)。
(2)神经辐射场网络结构
(1)这个网络是一个简单的全连接神经网络,在左边是输入处理过后的输入位置空间位置数据,最后通过Relu激活函数处理输出 σ \sigma σ.
Care1:空间位置数据x,y,z并不是真实场景的坐标,而是经过相机(or手机相机)处理过后的空间坐标系下的坐标
Care2:通过对三维数据坐标进行升维,提高到60维,来获取更丰富的输出信息。(基于前任研究:输入信息维度越高,输出的信息信号也越高,丰富)
Care3:在图最上面,也就是空间数据送入结构处理一半的过程中,再次输入空间坐标。目的是为了加强坐标信息。
(2)同时在另一个位置(图下方),方向坐标通过升维,并且和处理过的空间坐标信息特征拼接在一起,通过最后的两层网络处理,由Sigmoid激活函数输出RGB值,也叫 c c c值,是代表颜色,发光强度。
(3)体渲染
大概过程:通过网络输出的每个点的密度 σ \sigma σ和颜色 c c c,去模拟一条光线,并计算其成像的像素。

先来看两个公式
光线公式:
r ( t ) = o + t d r(t)=o+td r(t)=o+td
r表示一条光线,o是光线的起点,t代表光线在方向d上前进的距离
渲染公式:

(1) C ( r ) C(r) C(r)代表某条光线在平面形成的像素值
(2) t f t_f tf代表光线的起点, t n t_n tn代表终点
(3) T ( t ) T(t) T(t)代表透光率,其具体表达看右式,通过密度 σ \sigma σ求积分并取指数得到,物理意义可以理解为其值越大,透射程度越大,即光穿过该位置后能量减少程度小
(4) σ \sigma σ ( r ( t ) ) (r(t)) (r(t)) c ( r ( t ) , d ) c(r(t),d) c(r(t),d) 表示粒子密度和颜色的乘积
(5)通过对上述属性在时间区间上求积分,可以求出其最终在平面的成像像素值
(4)相关工作
1:在隐式神经渲染爆火之前,业界常用的渲染方法是显式渲染,如下图,


显示表达通常采用点云、网格、体素等形式去进行场景的表达,但是其在渲染过程去对显存的要求比较大,也就是其需要占用过多的内存、算力,而隐式渲染则使用一个相对较小的神经网络去代替了上述的工作,因为隐式表示,在表达复杂场景时其参数量相比显示表示是较少的,并且隐式函数因为其连续性,对场景表达更精细。
NeRF做到了利用”隐式表示“实现了照片级的视角合成效果,把Volume作为中间3D场景表征,并通过“体渲染”实现了特定视角照片合成效果。因此,NeRF实现了从离散的照片集中学习出了一种隐式的体表达,然后在某个特定视角,利用该隐式体表达和体渲染得到该视角下的照片。
2:另外Nerf在数据处理上还做了一些小的创新。
(1)位置编码:
这里位置编码的作用在于对输入的数据进行一个升维操作,因为研究表明输入数据维度越高,其输出数据维度也越高,也就是输出数据更加丰富。

def positional_encoding(inputs, L=10):
"""
inputs: 输入向量,包含(x,y,z)三个坐标
"""
L = 10
# freq_bands: [2^0, 2^1, ..., 2^(L-1)]
freq_bands = 2 ** torch.linespace(0, L-1, L)
outputs = []
for freq in freq_bands:
# [sin(2^f \pi x), sin(2^f \pi y), sin(2^f \pi z)]
outputs += [torch.sin(freq * inputs)]
# [cos(2^f \pi x), cos(2^f \pi y), cos(2^f \pi z)]
outputs += [torch.cos(freq * inputs)]
# [sin(2^0 \pi x), sin(2^0 \pi y), sin(2^0 \pi z), cos(2^0 \pi x), cos(2^0 \pi y), cos(2^0 \pi z), ...]
outputs = torch.cat(outputs, -1)
return outputs
(2)分层采样(由粗到细采样)
因为对所有光线的所有粒子进行计算模拟需要大量的算力,并且十分费时,为了提高效率,论文作者先对每条光线各个区域选取一部分采样,采样处理后,选取上一步采样中信息比较丰富的的区域进行细采样。通过该操作可以提高数据采样计算的整体速度。
(5)结果展示
论文采用了PSNR和SSIM这两个指标来进行评价:

可以看到本文结果相比上述结果有了很大的提升,在PSNR值体现比较大。


参考资料
港大本科余同学对Nerf体渲染相关的介绍
AI小男孩 对体渲染以及Nerf的介绍
论文是最好的老师 Nerf论文
Talk is cheap, give me your code!!!