基于MVS的三维重建基础
三维信息表示方法
一般分为深度图/视差图、点云、网格。它们都是表达3D信息的一种方式,会根据实际应用场景不同来选取不同的方式来表示。比如说做一些背景序化、人脸特效就可以只使用深度图就可以了;而如果我们要重建一个大型场景,如博物馆什么的,需要将其显示出来供大家浏览,可以使用网格来表示;而做定位的时候,我们只需要用点云就可以了。但是如果我们要制作点云或者网格,都必须要使用深度图,这一步是必须要经历的。有了深度图才可能得到点云或者是三维的网格。
- 深度图/视差图
- 深度图:场景中每个点到相机的距离;
- 视差图:同一个场景在两个相机下成像的像素的位置偏差dis
- 两者关系:depth=bf/dis
- 是三维信息的常用表示方式
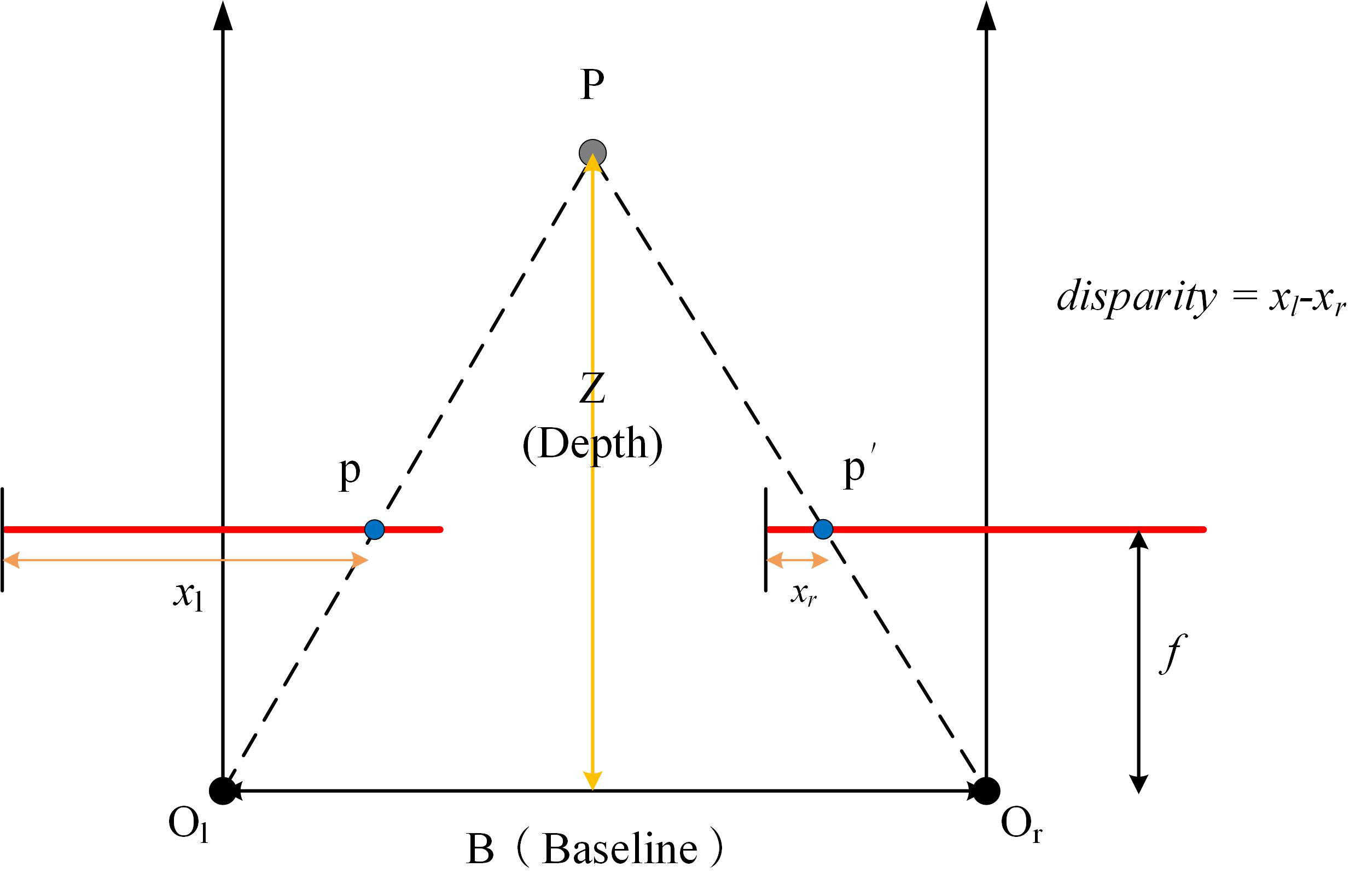
在上图中,Ol和Or是两个相机,我们一般称为双目相机,它们之间的距离称为基线(Baseline)。空间的一个点P,它到基线的距离Z称为深度。上图中的两条红线分别是两个相机不同的成像。p点和p'分别是点P在Ol和Or相机成像中的点。视差d等于同名点对在左视图的列坐标减去在右视图上的列坐标,是像素单位
![]()

上图就是双目摄像机拍摄的照片,电动车后视镜的视差就为80-35=45.
立体视觉里,视差概念在基线校正后的像对里使用。也就是说两个相机是校正好的,平行的,都是朝前去拍摄物体的,此时才能使用视差图。一般来说我们使用的都是深度图,视差图更容易拍摄,然后转换成深度图。视差的单位是像素,深度的单位是毫米(mm),转换公式为depth=bf/dis,这里b为双目相机的基线距离,这个是已知的,f表示归一化的焦距,也就是内参中的fx,这个也是已知的,dis就是视差值。
{{o.name}}
{{m.name}}