简介
联邦学习(Federated Learning)是一种新兴的人工智能基础技术,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合法合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。其中,联邦学习可使用的机器学习算法不局限于神经网络,还包括随机森林等重要算法。联邦学习有望成为下一代人工智能协同算法和协作网络的基础。
联邦学习由来
在神经网络中,如果一个网络的训练数据越多,其训练效果往往会越好。那么如果说一个公司有数据,另一个公司也有数据,两家公司的数据共享出来一起使用岂不是更爽?但是,用户数据能够被随意的使用和转发吗?答案是否定的。那么有什么办法可以使得两家公司不泄露用户的情况下,利用到用户数据呢?
2016年,为解决安卓系统更新的问题。谷歌提出,可以在用户的手机上部署神经网络训练,只需要将训练好的模型参数上传,而不需要上传用户数据,一定程度上保证了个人数据的私密。这就是联邦学习(federated learning)的核心理念。
联邦学习的系统构架
以包含两个数据拥有方(即企业 A 和 B)的场景为例介绍联邦学习的系统构架。该构架可扩展至包含多个数据拥有方的场景。假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私保护和安全考虑,A 和 B 无法直接进行数据交换,可使用联邦学习系统建立模型。联邦学习系统构架由三部分构成。
1.加密样本对齐
由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户,以便联合这些用户的特征进行建模。
2.加密模型训练
在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步:
第①步:协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密。
第②步:A 和 B 之间以加密形式交互用于计算梯度的中间结果。
第③步:A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把结果汇总给 C。C 通过汇总结果计算总梯度值并将其解密。
第④步:C 将解密后的梯度分别回传给 A 和 B,A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
3.效果激励
联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供数据多的机构所获得的模型效果会更好,模型效果取决于数据提供方对自己和他人的贡献。这些模型的效果在联邦机制上会分发给各个机构反馈,并继续激励更多机构加入这一数据联邦。以上三部分的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了以一个共识机制奖励贡献数据多的机构。所以,联邦学习是一个「闭环」的学习机制。
联邦学习优势
数据隔离,数据不会泄露到外部,满足用户隐私保护和数据安全的需求;
能够保证模型质量无损,不会出现负迁移,保证联邦模型比割裂的独立模型效果好;
参与者地位对等,能够实现公平合作;
能够保证参与各方在保持独立性的情况下,进行信息与模型参数的加密交换,并同时获得成长。
联邦学习(Federated Learning, a.k.a. Federated Machine Learning)可以分为三类:
- 横向联邦学习(Horizontal Federated Learning)
- 纵向联邦学习(Vertical Federated
- Learning) 联邦迁移学习(Federated Transfer Learning)
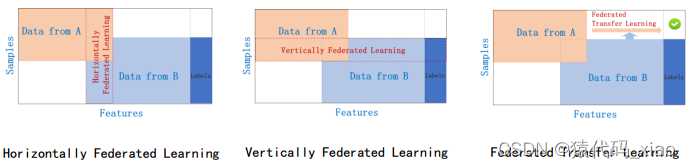
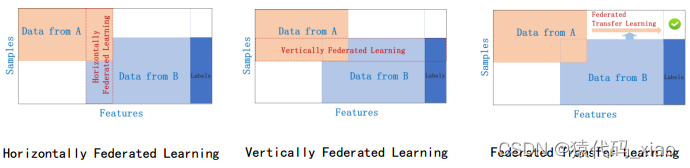
横向联邦学习
数据矩阵(也可以是表格,例如,Excel表格)的横向的一行表示一条训练样本,纵向的一列表示一个数据特征(或者标签)。通常用表格查看数据(例如,病例数据),用一行表示一条训练样本比较好,因为可能有很多条数据。
横向联邦学习,适用于参与者的数据特征重叠较多,而样本ID重叠较少的情况。
比如有两家不同地区的银行,它们的用户群体分别来自各自所在的地区,相互的交集很小。但是,它们的业务很相似,因此,记录的用户特征是相同的。此时,我们就可以使用横向联邦学习来构建联合模型。
“横向”二字来源于数据的“横向划分(horizontal partitioning, a.k.a. sharding)”。如图1所示例,联合多个参与者的具有相同特征的多行样本进行联邦学习,即各个参与者的训练数据是横向划分的,称为横向联邦学习。图2给出了一个横向划分表格的示例。横向联邦使训练样本的总数量增加。
横向联邦学习也称为特征对齐的联邦学习(Feature-Aligned Federated Learning),即横向联邦学习的参与者的数据特征是对齐的,如图3所示例。“特征对齐的联邦学习”这个名字有点长,还是用“横向联邦学习”比较好。
横向联邦学习的学习过程:
- 参与者在本地计算训练梯度,使用加密,差分隐私或秘密共享技术加密梯度的更新,并将加密的结果发送到服务器;
- 服务器在不了解有关任何参与者的信息的情况下,聚合各用户的梯度更新模型参数;
- 服务器将汇总结果模型发回给各参与者;
- 各参与者使用解密的梯度更新各自的模型。
纵向联邦学习
纵向联邦学习,适用于参与者训练样本ID重叠较多,而数据特征重叠较少的情况。
比如有两个不同的机构,一家是某地的银行,另一家是同一个地方的电商。它们的用户群体很有可能包含该地的大部分居民因此用户的交集较大。但是,由于银行记录的都是用户的收支行为与信用评级,而电商则保有用户的浏览与购买历史,因此它们的用户特征交集较小。
“纵向”二字来源于数据的“纵向划分(vertical partitioning)”。如图4所示例,联合多个参与者的共同样本的不同数据特征进行联邦学习,即各个参与者的训练数据是纵向划分的,称为纵向联邦学习。图5给出了一个纵向划分表格的示例。纵向联邦学习需要先做样本对齐,即找出参与者拥有的共同的样本,也就叫“数据库撞库(entity resolution, a.k.a. entity alignment)”。只有联合多个参与者的共同样本的不同特征进行纵向联邦学习,才有意义。纵向联邦使训练样本的特征维度增多。
纵向联邦学习也称为样本对齐的联邦学习(Sample-Aligned Federated Learning),即纵向联邦学习的参与者的训练样本是对齐的,如图6所示例。“样本对齐的联邦学习”这个名字有点长,还是用“纵向联邦学习”比较好。
纵向联邦学习的学习过程:
第一步:第三方C加密样本对齐。是在系统级做这件事,因此在企业感知层面不会暴露非交叉用户。
第二步:对齐样本进行模型加密训练:
- 合作者C创建加密对,将公钥发送给A和B;
- A和B分别计算和自己相关的特征中间结果,并加密交互,用来求得各自梯度和损失;
- A和B分别计算各自加密后的梯度并添加掩码发送给C,同时B计算加密后的损失发送给C;
- C解密梯度和损失后回传给A和B,A、B去除掩码并更新模型。
联邦迁移学习
联邦迁移学习,适用于参与者训练样本ID和数据特征重叠都较少的情况。
我们不对数据进行切分,而利用迁移学习来克服数据或标签不足的情况。这种方法叫做联邦迁移学习。
比如有两个不同机构,一家是位于中国的银行,另一家是位于美国的电商。由于受地域限制,这两家机构的用户群体交集很小。同时,由于机构类型的不同,二者的数据特征也只有小部分重合。在这种情况下,要想进行有效的联邦学习,就必须引入迁移学习,来解决单边数据规模小和标签样本少的问题,从而提升模型的效果。
算法介绍:
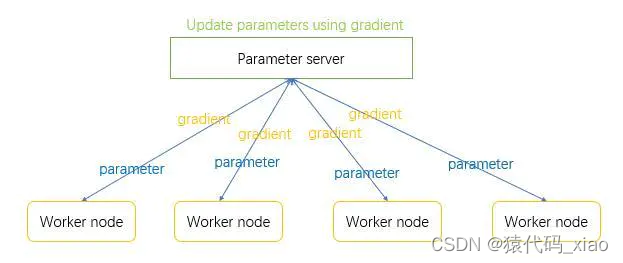
这里的数据计算由worker node来进行。服务器会下发parameters来使worker node有一个初始参数。worker node将自己的数据计算后将梯度发送给服务器。由服务器来进行梯度下降。在数据的传输过程中,空间复杂度为:参数的数量。
worker node的工作内容:
- receive parameters from sever;
- using paramters and local data tocompute gradients
- send gradients to server
server的工作内容:
receive
- gradients from every worker node;
- compute sum(g1, g2, g3, ……gm);
- updating model parameters,直接使用梯度下降的方法;
- send parameters to every worker node;
联邦学习和传统的分布式学习的区别:
(1)用户对自己的设备和数据有绝对的控制权,用户可以随时停止计算和参与通信。而在传统的分布式学习中worker node完全由server控制。
(2)参与联邦学习的设备往往是不稳定的,计算能力也不尽相同。
(3)联邦学习的通信代价大,通信量多。(我们要减少通信次数)
(4)参与联邦学习的数据并非独立同分布,不利于算法设计,因为每个用户的数据是不一样的。
(5)联邦学习的节点负载不平衡,每个用户的数据量不一样,不好分配权重,建模复杂。计算时间不一样。
相关研究方向:
(1)降低通信次数:其核心要点就是,worker node多计算少通信。
这里介绍一种新的算法和上述算法有些差别。叫做federated averaging algorithm
worker node的工作内容:
- receive parameters from sever;
- using paramters and local data to compute gradients;
- local update parameters; 循环几次
- send new_parameters to server;
server的工作内容:
- receive new_parameters from every worker node;
- compute W = sum(p1,p2, p3, ……pm);
- parameters = 1/m ( W )可以做加权平均,也可以是直接平均;
- send parameters to every worker node;
**优点:**可以在相同的通信次数下,FedAvg比原算法(Grad Desent)的收敛速度更快。
**缺点:**让移动设备计算相同的数据量,FedAvg比原先的Grad Desent梯度下降慢,收敛更慢。
**总结:**以牺牲worker node的计算量来换取通信量的减少。但是由于联邦学习的通信代价大而计算代价小,所以其有一定的作用。
(2)隐私保护
虽然data仍然还保存在手机中,我们将gradient和parameters进行传输,真的做到了数据保护吗。
我们简单的来看一下梯度下降的算法:
loss = 1/2 (y^ - y) ^2
gradient = ( xi*W - yi ) xi
所以gradient就是对x进行了一个简单的变换,x的信息基本上都包含在了gradient里面了。所以可以将原始数据反推出来。
那么下面是不是可以做到呢?

那么怎么进行隐私保护呢?
- 加噪声,不是什么好方法。加的少,没作用,加的多,数据遭到破坏,测试准确度下降。
- 现在仍没有什么较好的方法。
(3)增强联邦学习的鲁棒性(让模型抵抗拜占庭错误,和恶意攻击。)
拜占庭错误:
就是在worker node中出现了一个叛徒,可能他的数据和标签都是动过手脚的,他的异常导致整个神经网络的崩溃。
attack1:data poisoning attack;毒药攻击,给数据做一些手脚
attack2:model poisoning attack;模型攻击,针对分布式学习。直接做法就是样本和标签错对。
这些攻击可以使得模型收敛变慢,可以让准确度下降,甚至可以留下一个bug。
defense1:server check validation accuracy。让server对上传的数据在测试集上进行准确度的检验,从而判断是不是一个好数据。(这不是一个好的判断方法,因为联邦学习中的数据不具有独立同分布的性质,并且server是不允许看到用户数据的)
defense2:server check gradient statistic。(因为独立同分的数据都相近,所以梯度也不会差的太多,比较不同节点上传的梯度差异,如果个别梯度的差异过大,就认为这个节点叛变了。但是数据不是独立同分布,也不是特别好)
defense3:byzantine-tolerant aggregation;使用更稳定的方法整合梯度;
总结
横向联邦学习的名称来源于训练数据的“横向划分”,也就是数据矩阵或者表格的按行(横向)划分。不同行的数据有相同的数据特征,即数据特征是对齐的。
纵向联邦学习的名称来源于训练数据的“纵向划分”,也就是数据矩阵或者表格的按列(纵向)划分。不同列的数据有相同的样本ID,即训练样本是对齐的。