什么是联邦学习?
联邦学习是在多参与方或多计算结点之间开展高效率的机器学习框架,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私。
我们用一张图来描述联邦学习的流程:

参与者有2个及以上,他们想利用各方的数据集合作训练一个模型但是又不想让自己的数据集泄露给server,所以他们约定了一份协议:采用同一种机器学习结构(比如DNN)和算法(比如SGD)。开始训练前,Server 先初始化 DNN模型 中的参数
(就是W,b),在每一轮训练中,participant1 和 participant2 从Server下载模型的参数
,并把参数配置到 local model 中,这样就可以利用 SGD 算法获得损失函数
对参数
的梯度
了。得到各自的梯度后,每一位participant 把梯度上传到 Server上的 global model ,global model 根据这些梯度来更新自己的参数:
(k是participants的个数,
可以当作学习率)。这样就完成的一轮的 参数更新。
参数更新的两种机制
-
synchronized gradient updates(同步梯度更新)

注意在这种方式下:server每一轮的参数更新中,每一个participant都在本地选取一批次数据进行计算,只计算一次,然后把计算得到的梯度上传到 server。如果本地模型在本地数据集上训练了多轮的话,返回的梯度需要校正。----至于怎么校正,可以看看 Federated Learning with Unbiased Gradient Aggregation and Controllable Meta 这篇文章。 -
model averaging

(n is the total size of all particpants’ training data)
不同于第一种,第二种会随机选择participant 进行参数更新,这加大了 inferen attack 的难度。在理想条件下,一般选取所有的participants,或者说我们知道server每次选取哪些参与者,这样才能针对某些participants进行推断攻击。
在第二种情况下,server每一轮的参数更新,对应的是每一个participant整个数据集(区分第一种更新方式只针对数据集中某一批的数据),而且上传的是 。
联邦学习的推断攻击
根据联邦学习参数更新的机制,引出了对应的推断攻击。理想条件下,我们一般假设participants = 2,一个是target participant(被攻击者)。一个是adversary participant(攻击者),为什么不讨论 participants >2的情况?—攻击者无法从整体的 参数 (被攻击者的参数 以及 其他无辜的参与者 的 average 参数)中 distinguish 被攻击者的参数。攻击如下图:
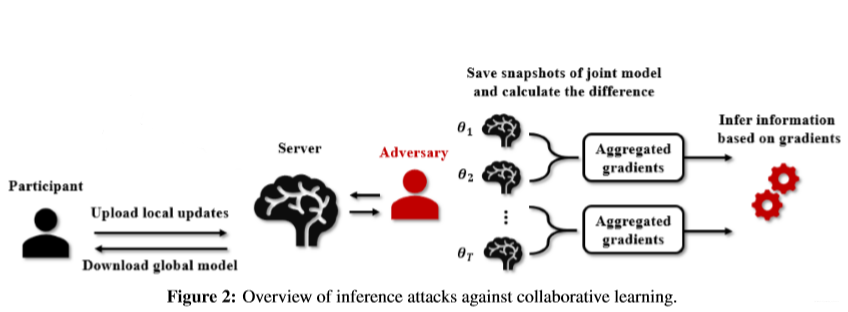
每次server更新全局参数后,adversary都会把更新的参数存放起来,也就得到了{
}(假设server共更新了k轮全局参数),我们可以把相邻两次的参数相减,得到的就是k次全局参数的变化量,也就时每次参数更新的变化量,比如第t次更新的变化量是:
,并且
对于adversary来说是已知的,那么
可以被adversary间接地计算出来。
1.利用embedding layer的成员推断
对于一个深度网络中,字段类数据是利用embedding layer处理的,比如一个属性“性别”有以下三个类:“man”,“woman”,“unknown”,那么我们在数据预处理时需要做的是对这个属性的所有字段进行one-hot编码,得到如下结果:
| 原字段 | one-hot处理后 |
|---|---|
| man | 1 0 0 |
| woman | 0 1 0 |
| unknown | 0 0 1 |
更深入可以参考:https://www.cnblogs.com/bonelee/p/7904495.html
给定一批文本,embedding layer只更新这一批文本中出现的单词对应的参数,比如在上面举的例子里,输出层有三个输出单元按次序分别代表“man”,“woman”,“unknown”,如果某一次训练中只更新了第二个输出单元(第二个输出单元的
发生改变),那么说明“woman”出现在了这次参与训练的数据中。
2. Passive property inference(被动属性推断)
这和成员推断攻击本质相似的
假设adversary有 auxiliary data,也就是和target participant类似的数据。假设我们想知道target participant的某一批训练数据中有没有出现“性别“属性为“man”的数据,为此,我们训练了针对”性别“属性的** Batch property classifier**(针对synchronized gradient updates机制):

简单地来说:adversary有两类数据——有“man”的数据和没“man”的数据,在local 计算这两类数据对应的参数梯度
—是在本地偷偷的做所以不会把这个参数上传到server从而不会影响 main task(区分与下面的主动属性推断) ,有“man”的梯度标记1,没“man”的梯度标记0,用以上的数据训练一个二分类模型,这个模型具有根据给定一批数据的梯度,判断”man“类有无出现在这批数据的能力。我们前面得到了
,这个其实就是第 t 轮训练的梯度,凭此我们可以判断第 t 轮训练中有没有出现”man“这个类。
为什么可以这么做?:
用 t-sne对 server model 的几个层的输出进行降维:
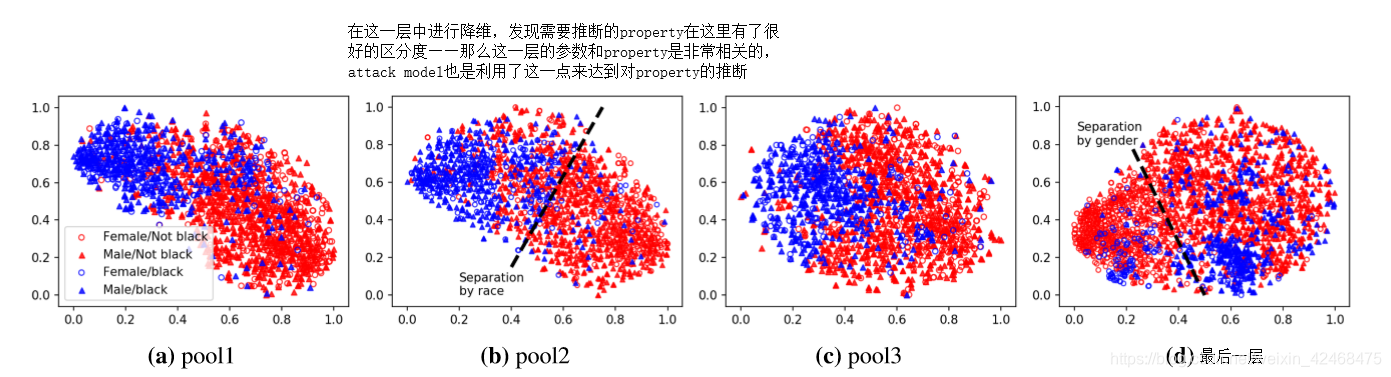
不同层的输出对于不同属性有着不一样的区分度,区分度好则说明这一层的参数可能和某属性有较大的关联,比如最后一层,它能很好的区分 main task 的分类任务,第二层则可以很好的区分属性 ”race“ 的两个分类。
3. Active property inference(主动属性推断)
Adversary修改local model的损失函数,假设联邦学习的main task是y,adversary要针对属性p进行推断,那么他把自己的 local model 的损失函数变成:
左边那一项是原来的损失函数。这样一来,main task 从原来的 对 y 分类,逐渐偏移到对 p 分类,这会在 server model 的最后一层显现出来:
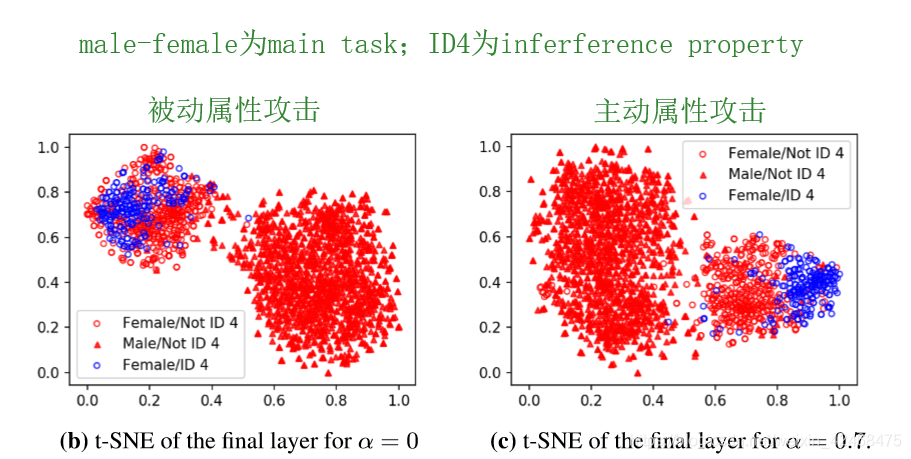
然后再仿照被动属性推断,重复相同步骤。这样做的原理是让 server model 最后一层的参数和要推断的属性p挂上钩,,这样得到的攻击模型Batch property classifier具有更高的准确率。
这样做是牺牲main task 的准确率来提高推断的准确率。
应用
Membership inference :利用embedding layer的成员推断
Property inference :两种属性攻击
Inferring when a property occurs :两种属性攻击
参考:Exploiting Unintended Feature Leakage in Collaborative Learning
