提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
在学习联邦学习时 了解的一些知识点,包括基本概念、算法优势、DPOS机制等。
一、什么时联邦学习?
联邦学习是一种基于分布式学习的机器学习方法,它允许在不共享数据或与其他设备交换原始数据的情况下对模型进行训练。在联邦学习中,多个端设备(例如移动设备、嵌入式设备、传感器等)在本地训练他们自己的模型,并将其更新传递给中央协调器,协调器将这些更新结合起来,并创建一个全局模型。这种方法旨在保护每个设备上的私有数据,同时仍允许在全局模型中获得稳健的学习结果。
联邦学习的主要应用是在大型分布式系统中,允许多个设备在本地进行训练,这些设备可以是移动设备、个人设备、传感器等,在训练完成后将修改的模型参数发送给中央服务器进行结合。与传统的集中式训练不同,联邦学习可以显著降低隐私泄露的风险,同时在保护数据隐私的基础上获得更好的模型效果,并提高训练效率和网络带宽利用率。
联邦学习的优点是可以在不泄漏客户端隐私的情况下共同协作构建模型,缺点是在模型初始状态下需要传输大量的信息,占用较高的计算资源。同时由于移动设备和嵌入式设备的计算能力和存储容量有限,少量恶意用户会对模型的性能影响比较大,需要配合其他的协同防御措施。
二、联邦学习的实现步骤、实现过程
中央服务器先将初始模型分发给各参与方,然后各参与方根据本地数据集分别对所得模型进行训练。接着,各参与方将本地训练得到的模型参数加密上传至中央服务器。中央服务器对所有模型梯度进行聚合,再将聚合后的全局模型参数加密传回至各参与方。
在联邦学习中,用户端不用上传自己的本地数据,只需要在本地训练数据形成一个本地模型,然后每个用户端将自己训练的本地模型上传到联邦服务器,联邦服务器对所有传上来的模型进行聚合,然后再把聚合后的模型发送回给用户端。用户端根据模型来继续调整自己的本地模型,或者进行数据的预测等等。
联邦学习过程: 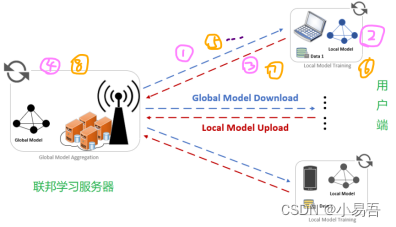
首先, 联邦学习服务器先分发一个初始模型给客户端用户 (步骤1);
客户端用户接收全局模型后,利用自己的本地数据进行训练,得到一个本地模型\局部模型 (步骤2);
所有用户端将训练好的本地模型上传到联邦学习服务器端 (步骤3);
服务器将所有上传的本地模型进行聚合,得到一个全局模型 (步骤4);
然后继续重复上述 (步骤5-8) 直到训练的模型达到理想模型为止。
通用联邦学习算法步骤:
-
确定联邦学习的目标和问题:首先需要定义算法目标,例如在分类问题中达到高准确率,或在回归问题中尽可能减小预测误差。同时需要确定执行联邦学习的问题,例如图像分类、语音识别或自然语言处理等。
-
建立联邦学习通信结构:为了实现联邦学习,需要建立客户端和服务器之间的通信通道。此过程中需要确定参与训练的客户端数量和样本分布。
-
客户端模型训练:在训练开始前,服务器会将初始全局模型参数发送给所有参与训练的客户端。客户端使用本地数据训练模型并更新本地模型参数。
-
本地模型参数共享:每个客户端训练完本地模型后,将本地模型参数梯度发送给服务器。服务器会收集所有客户端发送的模型参数梯度,计算它们的平均值,并更新全局模型参数。
-
更新全局模型:服务器在接收到所有参与训练客户端的模型参数后,通过聚合客户端更新后的模型参数来更新全局模型参数。这个过程通常使用一些算法进行聚合和更新操作,例如FedAvg等。
-
重复训练过程:重复以上步骤多次,知道全局模型收敛或达到预设训练轮数为止。
需要注意的是,联邦学习算法中最重要的是保护隐私,避免原始数据的泄露。因此,在模型聚合之前,需要进行加密或差分隐私的处理,以保证本地数据的安全性。此外,聚合算法的设计和调参也是联邦学习算法效果良好的重要要素之一。
三、比特股的DPoS机制
DPoS(Delegated Proof of Stake)即委托权益证明,是一种区块链共识机制。DPoS将权益证明机制的思想进一步发展,这种机制与联邦学习并没有直接关系,但两者有相似点。
它的原理是让每一个持有比特股的人进行投票,由此产生101位代表 , 我们可以将其理解为101个超级节点或者矿池,而这101个超级节点彼此的权利是完全相等的。从某种角度来看,DPOS有点像是议会制度或人民代表大会制度。如果代表不能履行他们的职责(当轮到他们时,没能生成区块),他们会被除名,网络会选出新的超级节点来取代他们。
在DPoS机制中,是通过选举产生一些代表节点(也叫"见证人")来进行验证和打包交易,这些代表节点的数量要比所有节点少得多。DPoS机制的目的在于,通过选举产生的代表节点,进一步提高了交易验证的效率和安全性,保证了区块链的正常运行。这个机制与联邦学习非常相似,通过一个代表节点或中央协调者来处理模型更新,减少了计算和通信开销,从而提高了训练效率和安全性。
另外,相比于传统的权益证明机制,DPoS通过简化交易验证的过程,降低了区块链网络的复杂性并提高了其性能。同样的,在联邦学习中,只有代表节点或中央协调者才会处理模型更新,其余节点只需要对模型参数进行简单的更新和传输,并不需要像传统方法一样对原始数据进行处理,因此也可以提高训练效率和网络性能。
综上所述,DPoS机制和联邦学习虽然没有直接关系,但两者都是通过选举代表节点的方法来提高系统效率和安全性的技术,都具有相似的思想和优点。