综述文献:Federated Machine Learning: Concept and Applications 部分知识整理
文献介绍了联邦学习的概述与体系架构
人工智能面临的挑战:1)数据以孤岛形式存在;2)数据隐私和安全
传统数据处理模型:一方收集数据并将数据传输给另一方,另一方负责数据的清理和融合。最后,第三方将获取集成的数据并构建模型供其他方使用。
1. 联邦学习概述
1)概念:Their main idea is to build machine learning models based on data sets that are distributed across multiple devices while preventing data leakage. 他们的主要想法是建立基于分布在多个设备上的数据集的机器学习模型,同时防止数据泄漏。
2)克服:statistical challenges and improving security统计挑战和提高安全性
3)隐私技术:
Secure Multi-party Computation (SMC) 计算协议
Differential Privacy 噪声对敏感属性进行模糊处理,第三方无法区分个体
Homomorphic Encryption 数据和模型本身不会被传输,也不会被其他方猜到
2. 联邦学习体系架构
水平联邦学习
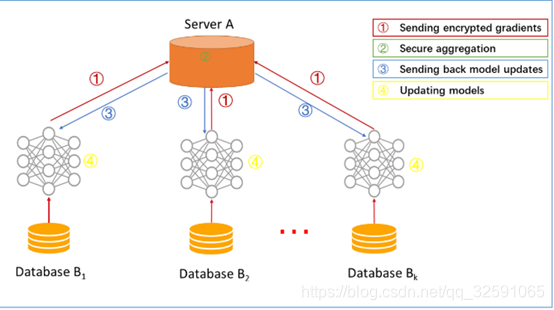
步骤1:参与者在本地计算训练梯度,使用加密、差分隐私或秘密共享技术屏蔽梯度选择,并将屏蔽结果发送到服务器;
步骤2:服务器在不了解任何参与者信息的情况下执行安全聚合;
步骤3:服务器将汇总后的结果返回给参与者;
步骤4:参与者用解密的梯度更新他们各自的模型。
通过上述步骤进行迭代,直到损失函数收敛,从而完成整个培训过程。该架构独立于特定的机器学习算法(逻辑回归、DNN等),所有参与者将共享最终的模型参数。
垂直联邦学习
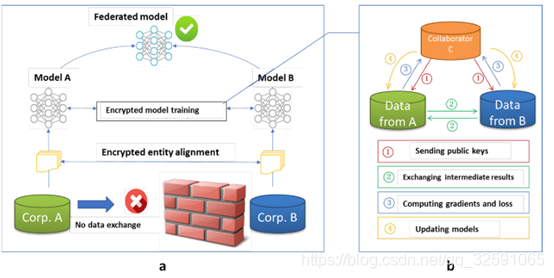
a. 加密的实体对齐,确认双方共同用户,不需要公开各自数据。
b. 加密模型训练,
步骤1:C创建加密对,向A和B发送公钥;
步骤2:A和B加密并交换中间结果以进行梯度和损失计算;
步骤3:A和B分别计算加密梯度和增加额外的掩码,B计算加密损失;A, B向C发送加密的值;
步骤4:C解密并将解密后的梯度和损耗发送回A和B;A和B解压梯度,相应地更新模型参数。
A和B的数据是局部保存的,训练中的数据交互不会导致数据隐私泄露。注:可能泄露给C的信息可能被认为侵犯隐私,也可能不被认为侵犯隐私。为了进一步防止C从A或B处获取信息,在这种情况下,A和B可以通过添加加密的随机掩码进一步隐藏它们对C的梯度。因此,在联合学习的帮助下,双方合作训练一个共同的模型。因为在训练过程中,每一方接收到的损失和梯度与在不受隐私约束的情况下,在同一地点采集数据,共同构建一个模型所接收到的损失和梯度是完全相同的,即该模型是无损的。该模型的有效性取决于加密数据的通信成本和计算成本。在每次迭代中,在A和B之间发送的信息随着重叠样本的数量而变化。因此,采用分布式并行计算技术可以进一步提高算法的效率。
