在Hadoop2.0之前,HDFS的单NameNode设计带来诸多问题:
单点故障、内存受限,制约集群扩展性和缺乏隔离机制(不同业务使用同一个NameNode导致业务相互影响)等
为了解决这些问题,除了用基于共享存储的HA解决方案我们还可以用HDFS的Federation机制来解决这个问题。
【单机namenode的瓶颈大约是在4000台集群,而后则需要使用联邦机制】
什么是Federation机制
Federation是指HDFS集群可使用多个独立的NameSpace(NameNode节点管理)来满足HDFS命名空间的水平扩展
这些NameNode分别管理一部分数据,且共享所有DataNode的存储资源。
NameSpace之间在逻辑上是完全相互独立的(即任意两个NameSpace可以有完全相同的文件名)。在物理上可以完全独立(每个NameNode节点管理不同的DataNode)也可以有联系(共享存储节点DataNode)。一个NameNode节点只能管理一个Namespace
Federation机制解决单NameNode存在的以下几个问题
(1)HDFS集群扩展性。每个NameNode分管一部分namespace,相当于namenode是一个分布式的。
(2)性能更高效。多个NameNode同时对外提供服务,提供更高的读写吞吐率。
(3)良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
(4)Federation良好的向后兼容性,已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation是简单鲁棒的设计
鲁棒性(健壮和强壮):在输入错误、磁盘故障、网络过载或有意攻击情况下,能否不死机、不崩溃
由于联盟中各个Namenode之间是相互独立的:Federation整个核心设计大部分改变是在Datanode、Config和Tools,而Namenode本身的改动非常少,这样Namenode原先的鲁棒性不会受到影响。比分布式的Namenode简单,虽然扩展性比真正的分布式的Namenode要小些,但是可以迅速满足需求。
另外一个原因是Federation良好的向后兼容性,可以无缝的支持目前单Namenode架构中的配置。已有的单Namenode的部署配置不需要任何改变就可以继续工作。
Federation不足之处
HDFS Federation并没有完全解决单点故障问题。虽然namenode/namespace存在多个,但是从单个namenode/namespace看,仍然存在单点故障。因此 Federation中每个namenode配置成HA高可用集群,以便主namenode挂掉一下,用于快速恢复服务。
Federation 架构
Federation方案的基本思路就是使用多个独立的NameSpace(NameNode节点管理)来满足HDFS命名空间的水平扩展,NameSpace之间在逻辑上是完全相互独立的(即任意两个NameSpace可以有完全相同的文件名),而在物理上可以完全独立(NameNode节点管理不同的DataNode)也可以有联系(共享存储节点DataNode)很显然,任何一个NameNode节点只能管理一个Namespace.这种在逻辑上无法统一命名空间的设计对于初学者来说,可能会常常踩到文件名冲突或文件不存在的陷阱中.很显然,任何一个NameNode节点只能管理一个Namespace.
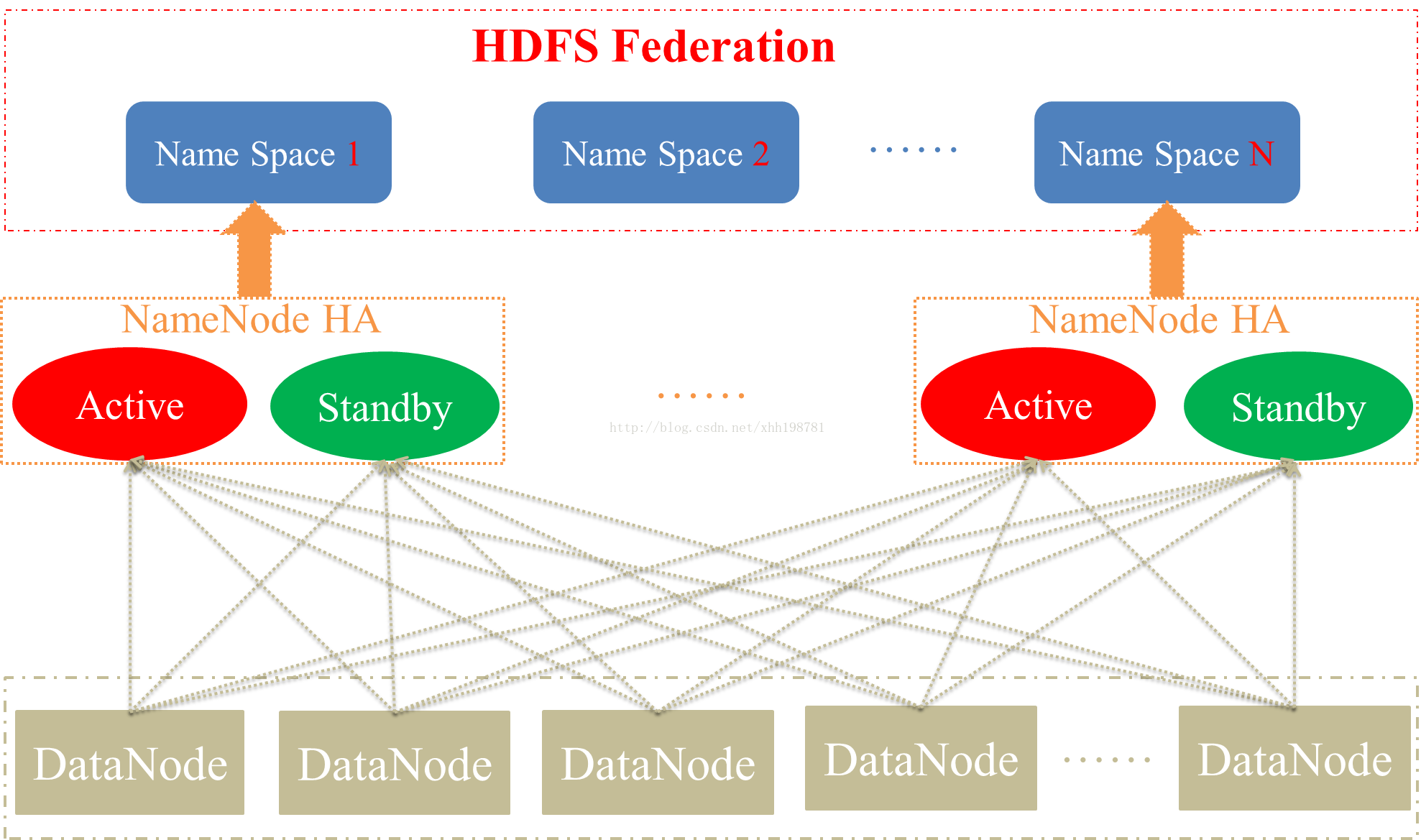
为了水平扩展namenode,federation使用了多个独立的namenode/namespace
这些namenode之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的datanode被用作通用的数据块存储存储设备。每个datanode要向集群中所有的namenode注册,且周期性地向所有namenode发送心跳和块报告,并执行来自所有namenode的命令。
每个namenode维护一个命名空间卷(namespace volume)
由命名空间的元数据和一个数据块池组成,数据块池(block pool)包含该命名空间下文件的所有数据块。
命名空间卷之间相互独立
两两之间并不互相通信,甚至其中一个namenode的失效也不会影响由其他namenode维护的命名空间的可用性。
一个namespace和它的blockpool作为一个管理单元(称为namespace volume)
数据块池不再切分,则集群中的DataNode需要注册到每个namenode,并且存储着来自多个数据块池中的数据块。当namenode/namespace被删除后,其所有datanode上对应的block pool也会被删除。集群升级时,这个管理单元也独立升级。
NameNode的HA
实现NameNode的HA方案,最重要的部分就是需要一个共享式的存储系统来实时存储NameNode的操作日志,而这种共享式的存储系统必须要满足两个基本条件:一是自身必须要高可用,二是保证强一致性.目前,Hadoop-2.x使用Quorum Journal Manager(QJM)来实现操作日志的共享,QJM是一个比ZooKeeper要轻量级的分布式存储系统,所使用的一致性约束条件远远不如paxos,raft等高可用的一致性算法.HDFS抽象出了一个日志接口JournalManager来屏蔽底层对操作日志存储的实现细节,目前主要有三种实现:
-
+ JournalManager
-
-FileJournalManager
-
-QuorumJournalManager
-
-BackupJournalManager
FileJournalManager将操作日志写入本地文件系统中,QuorumJournalManager将操作日志写入QJM中来实现主/备NameNode之间的操作日志共享,BackupJournalManager将操作日志实时的推送给backup的NameNode节点.QuorumJournalManager为了保证性能,采用了异步并发的方式将操作日志刷入所有的JournalNode节点
配置的HA的HDFS,所有NameSpace的NameNode节点在启动加载完元数据之后都处于Standby状态,之后被手动或自动的选择一个NameNode节点作为Active节点而开始正常工作.HA的自动方式是通过在每一个NameNode的本地启动一个守护进程ZKFailoverController来竞争Active NameNode的,ZKFailoverController除了为本地的NameNode争取Active角色之外,还负责监控本地的NN节点当前是否正常的,一旦它发现本地的NN不正常,要么主动替当前的Active NN退出Active角色或退出Active的竞争.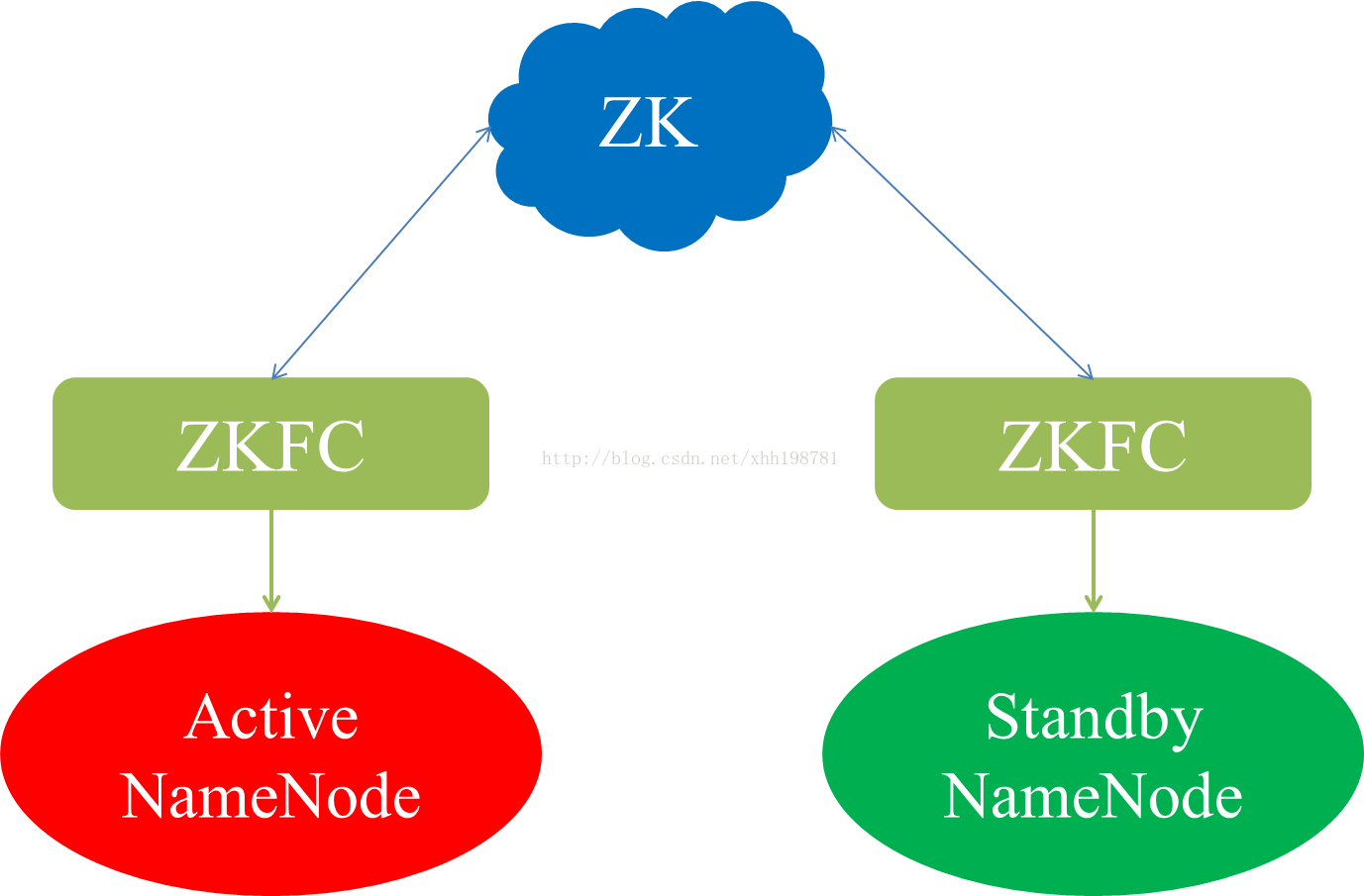
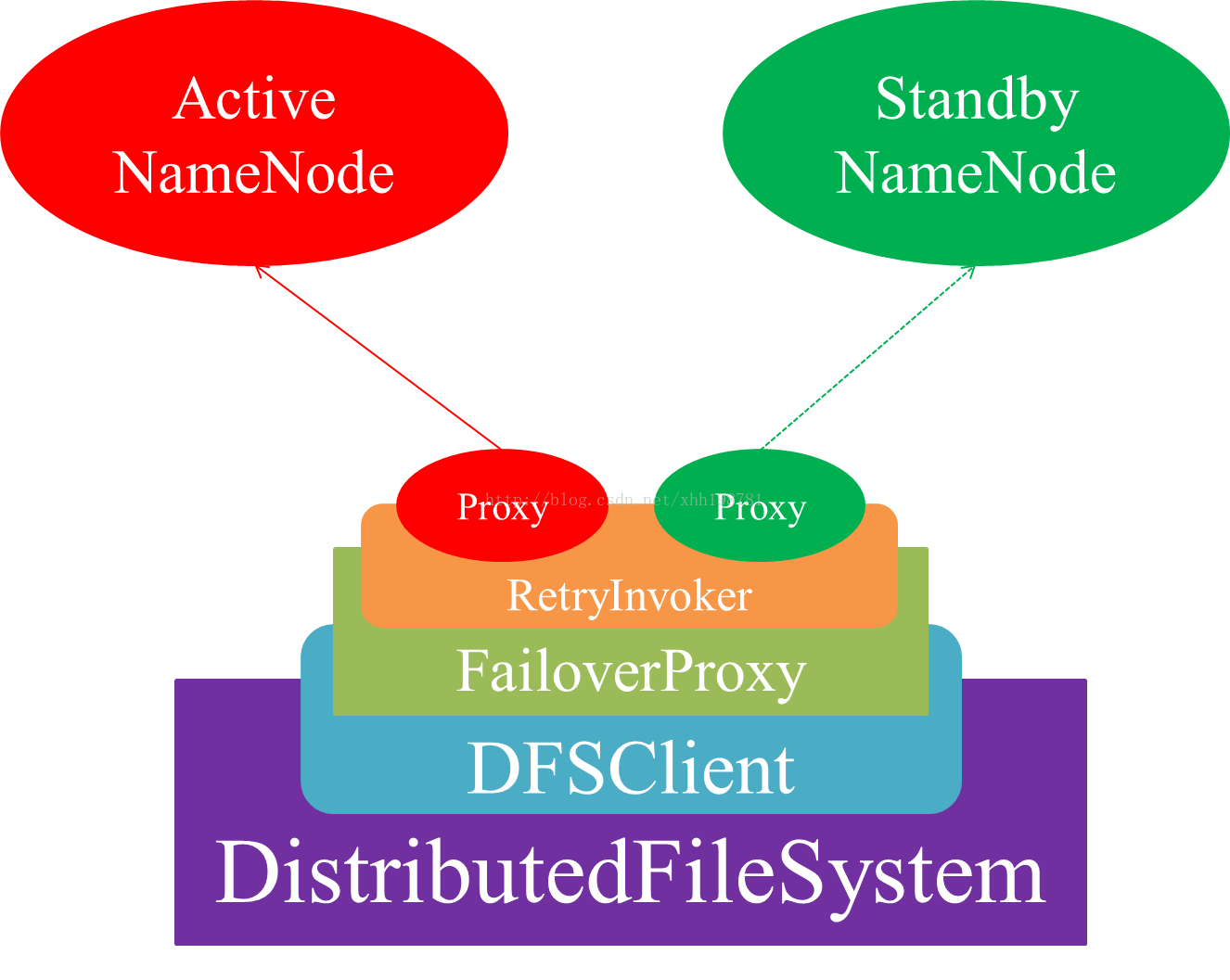
DistributedFileSystem的容错Proxy
HDFS的HA方案并不只是保证NameNode节点的高可用,还得保证客户端能够对用户透明的容忍主/备NameNode节点之间的切换.目前客户端对HA方案的实现方式主要是通过重试的机制来完成的.