语言模型:BERT的优化方法
BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理中的预训练模型,具有强大的文本理解能力。但是BERT也存在一些缺点,主要体现在如下几个方面:
1)训练方法与测试方法不一致。因训练时把输入序列的15%随机置换为MASK标记,但这个标记在测试或微调时是不存在的,因为会影响模型性能。
2)对被置换的MASK标记,BERT的损失函数使用约等号,也就是假设那些被标记的词在给定非标记的词的条件下是独立的。但是这个假设并不是(总是)成立。
另外,模型参数量比较庞大时,自然语言理解任务效果较好,但自然语言生成任务效果欠佳,段与段之间缺乏依赖关系等。因此,有很多新的模型被提出,例如XLNet、ALBERT、ELECTRA等模型。
图解XLNet模型

论文摘要:具有建模双向上下文能力的去噪自编码预训练模型,如BERT,相比基于自回归语言建模的预训练方法表现更好。然而,由于依赖使用掩码对输入进行损坏,BERT忽略了掩码位置之间的依赖关系,存在着预训练和微调之间的差异。鉴于这些优缺点,我们提出了XLNet,这是一种广义的自回归预训练方法,它通过最大化分解顺序的所有排列的期望似然来实现双向上下文的学习,并且通过其自回归公式克服了BERT的局限性。此外,XLNet将Transformer-XL的思想整合到了预训练中,这是一种最先进的自回归模型。从实证角度来看,在可比的实验设置下,XLNet在20个任务上表现优于BERT,通常差距很大,包括问答、自然语言推理、情感分析和文档排名等任务。
为了保留BERT模型双向学习的优点,同时改进因随机重置输入序列的10%的标注为[MASK]导致训练与预测阶段不一致以及没有考虑这些被[MASK]标注的序列之间的依赖关系等问题,XLNet采用排列语言模型(Permutation Language Modeling, PLM)来解决,采用Transformer-XL的架构来解决段之间关联不足的问题。
1. 排列语言模型(Permutation Language Modeling)
排列语言模型(Permutation Language Modeling)是训练用于预测给定前文的一个token的模型,类似于传统语言模型,但与其按顺序预测token不同,它以某种随机顺序预测token。为了更清楚地说明这一点,举个例子:
“Sometimes you have to be your own hero.”
传统的语言模型将按以下顺序预测tokens:
“Sometimes”, “you”, “have”, “to”, “be”, “your”, “own”, “hero”
其中每个token 使用所有先前的token 作为上下文。
然而,在排列语言建模中,预测顺序不一定是向右。例如,可能是
“own”, “Sometimes”, “to”, “be”, “your”, “hero”, “you”, “have”
其中“Sometimes”将以看到“own “为条件,“to”将以看“own” & “Sometimes”为条件等等。
假设有一个输入序列 { x 1 , x 2 , x 3 , x 4 } \{x_1,x_2,x_3,x_4\} {
x1,x2,x3,x4},根据排列语言模型,输入序列可以分解为多种排列方式,这种使用自回归模型预测 x 3 x_3 x3时,就可以同时看到其上文 ( x 1 , x 2 ) (x_1,x_2) (x1,x2)和下文 ( x 4 ) (x_4) (x4)。如下图所示:
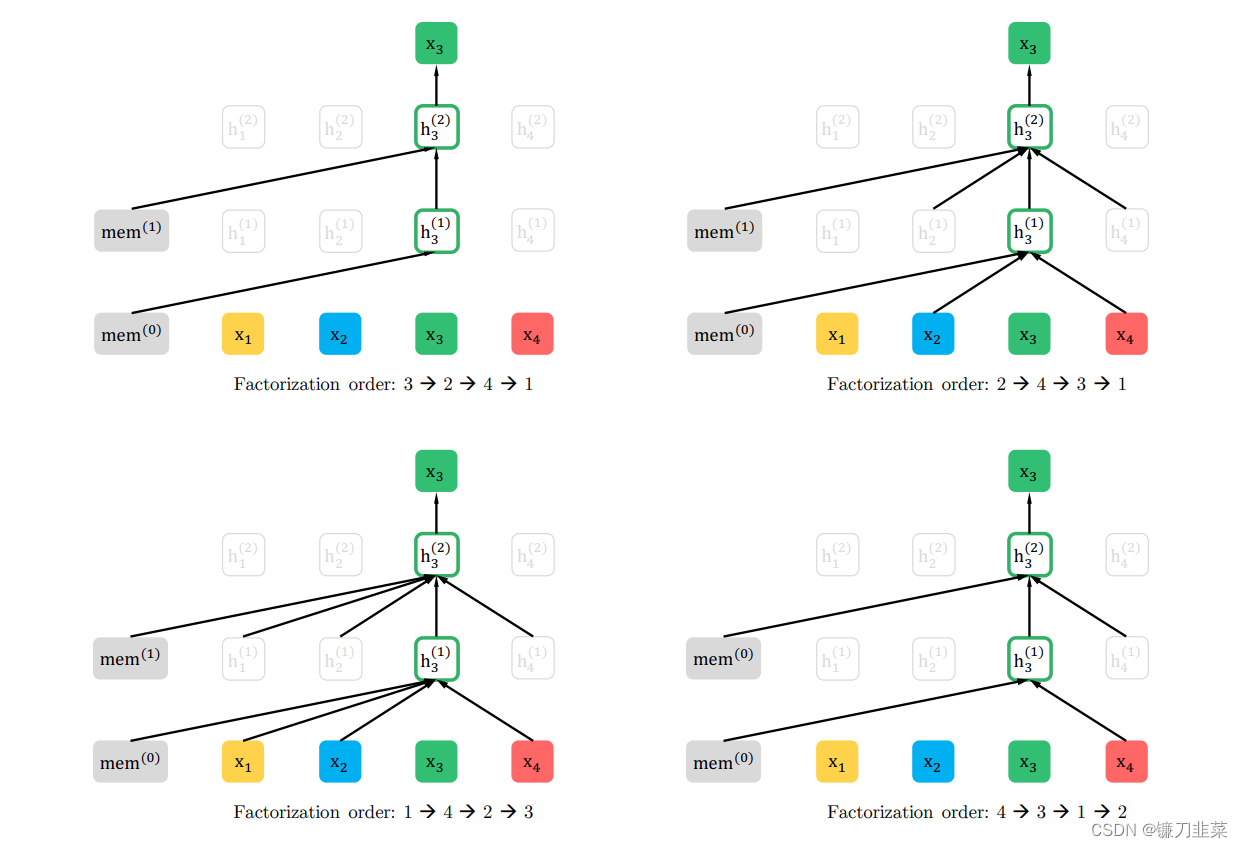
图1:以不同的因子化顺序预测 x 3 x_3 x3的排列语言建模目标示例,其输入序列x相同。左上图中对应的分解方式为 3 − > 2 − > 4 − > 1 3->2->4->1 3−>2−>4−>1,因此预测 x 3 x_3 x3时不能关注(attend to)其他任何词,只能根据之前的隐状态来预测。右上图中对应的分解方式为 2 − > 4 − > 3 − > 1 2->4->3->1 2−>4−>3−>1,因此可以根据 x 2 , x 4 x_2,x_4 x2,x4来预测 x 3 x_3 x3,既用到了 x 3 x_3 x3左边的词,也用到了 x 3 x_3 x3右边的词。同理,左下图和右下图以此类推。
注意,模型在排列语言建模中被迫建模双向依赖关系。从期望的角度来看,该模型应该学会建模输入的所有组合之间的依赖关系,而传统的语言模型只学会了单向的依赖关系。
2.XLNet融入Transformer-XL理念
除了使用排列语言建模之外,XLNet还利用了Transformer-XL,从而进一步提高了其结果。
Transformer XL模型背后的关键思想:
- 相对位置嵌入(Relative positional embeddings)。每一段都应该具有不同的位置编码,因此Transformer-XL采取了相对位置编码。
- 循环机制(Recurrence mechanism)。
- 前一个段计算的表示(representation)被修复并缓存,以便在模型处理下一个新段时作为扩展上下文重新利用。
- 最大可能依赖关系长度增加了N倍,其中N表示网络的深度。
- 解决了上下文碎片问题,为新段前面的标识符提供必要的上下文。
- 由于不需要重复计算,Transformer-XL在语言建模任务的评估期间比vanilla Transformer快1800多倍。
从前一个段落中缓存并冻结的隐藏状态,在执行当前段落的排列语言建模时保留不变。由于前一个段落的所有单词都被用作输入,因此无需知道前一个段落的排列顺序。
3. 使用双流自注意力机制(Two-Stream Self-Attention)
对于使用Transformer模型的语言模型,在预测位置 i 处的token时,包括positional embedding在内的该词的整个嵌入都被屏蔽掉。这意味着模型在预测token位置时与有关其位置的知识被隔绝。
For language models using the Transformer model, when predicting a token at position i, the entire embedding for that word is masked out including the positional embedding. This means that the model is cut off from knowledge regarding the position of the token it is predicting.
Permutation Language Modeling带来什么问题?
Permutation可以使AR模型从两个方向看到上下文,但也带来了原始Transformer无法解决的问题。排列语言建模的目标如下:
max θ E z ∼ Z T [ ∑ t = 1 T log p θ ( x z t ∣ x z < t ) ] \max_{\theta} \mathbb{E}_{\mathrm{z}\sim \mathcal{Z}_T}[\sum_{t=1}^T \log p_\theta (x_{z_t}|\mathrm{x}_{\mathrm{z}_{<t}})] θmaxEz∼ZT[t=1∑Tlogpθ(xzt∣xz<t)]
其中:
- Z \mathrm{Z} Z:a factorization order
- p θ p_\theta pθ:似然函数
- x z t x_{z}t xzt:the t t h t^{th} tth token in the factorization order
- x z < t x_z<t xz<t:the tokens before t t h t^{th} tth token
该公式是用于排列语言建模的目标函数,意味着以 t−1 个tokens 作为上下文,来预测第 t 个token。
标准的Transformer无法满足两个要求:
- 为了预测token x t x_t xt,模型只应该看到 x t x_t xt的位置,而不应该看到 x t x_t xt的内容。
- 为了预测token x t x_t xt,模型应该将 x t x_t xt之前的所有tokens作为内容进行编码。
考虑到上述的第一个要求,BERT将positional encoding与token embedding合并在一起(参见下图),因此无法将position information与token embedding分开:
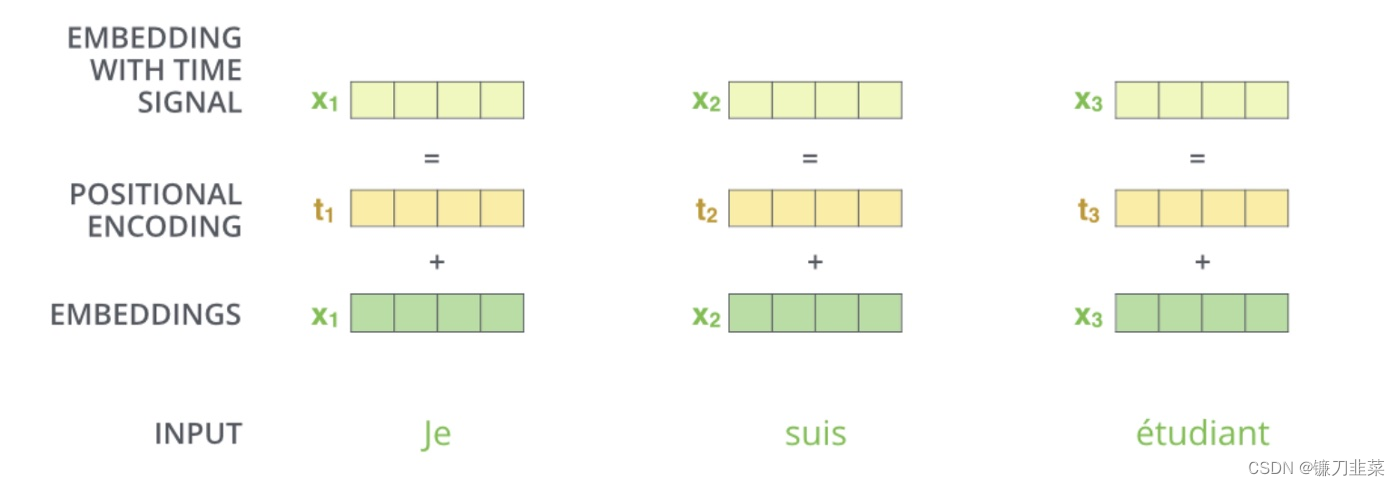
BERT是否存在将positional embedding与token embeddings分离的问题?
BERT是一种AE language model,它不需要像AR语言模型那样单独的position information。与XLNet需要position information来预测第 t 个token不同,BERT使用[MASK]来表示要预测的token(我们可以将[MASK]视为占位符)。例如,如果BERT使用 x 2 x_2 x2、 x 1 x_1 x1和 x 4 x_4 x4来预测 x 3 x_3 x3,那么 x 2 x_2 x2、 x 1 x_1 x1和 x 4 x_4 x4的embedding包含了position information以及与[MASK]相关的其他信息。因此,模型有很大的机会预测[MASK]是 x 3 x_3 x3。
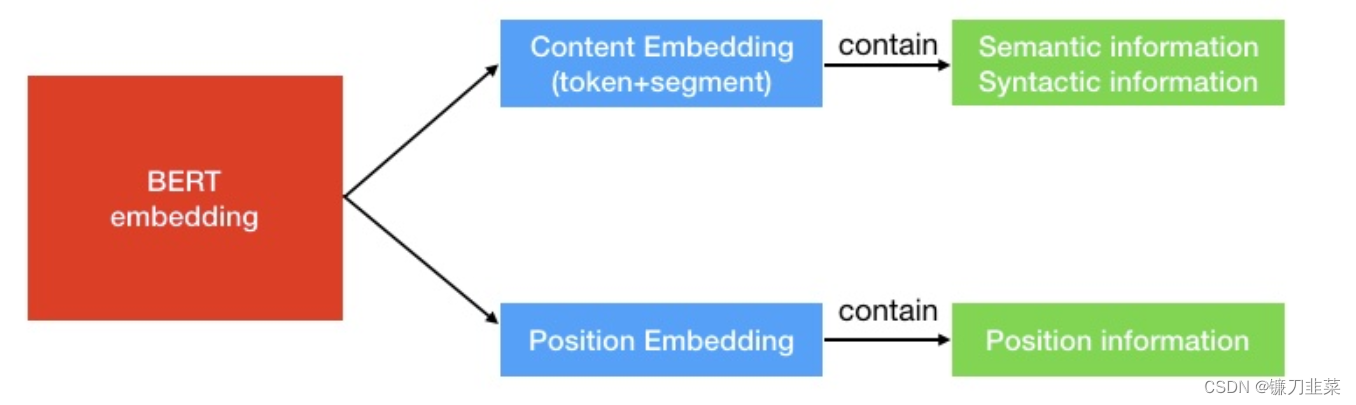
BERT的embeddings包含两种类型的信息,即positional embeddings和token/content embeddings(在这里,我们跳过了sequence embeddings,因为我们不关心下一句预测(NSP)任务),如下图所示。
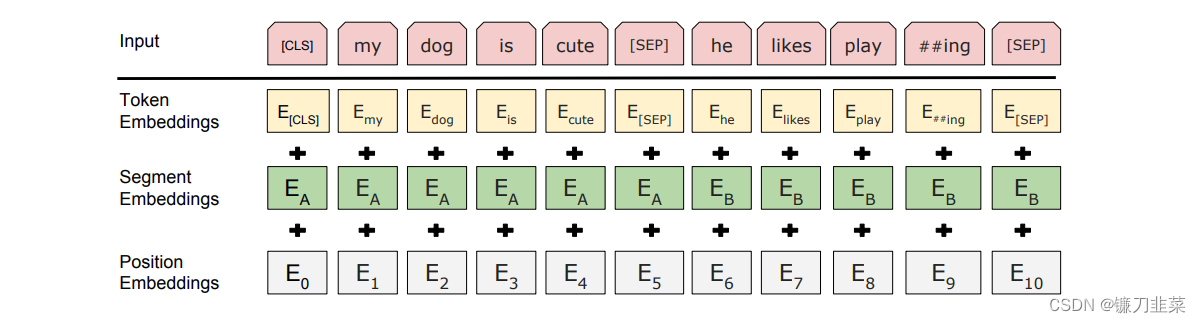
position information很容易理解,它告诉模型当前token的位置。 content information(语义和句法)包含了当前token的“含义”,如下图所示。
Word2Vec论文中使用的嵌入关系的一个直观示例是: q u e e n = k i n g − m a n + w o m a n queen=king−man+woman queen=king−man+woman
为了解决这个问题,XLNet引入了双流自注意力机制(Two-Stream Self-Attention),如下图所示:
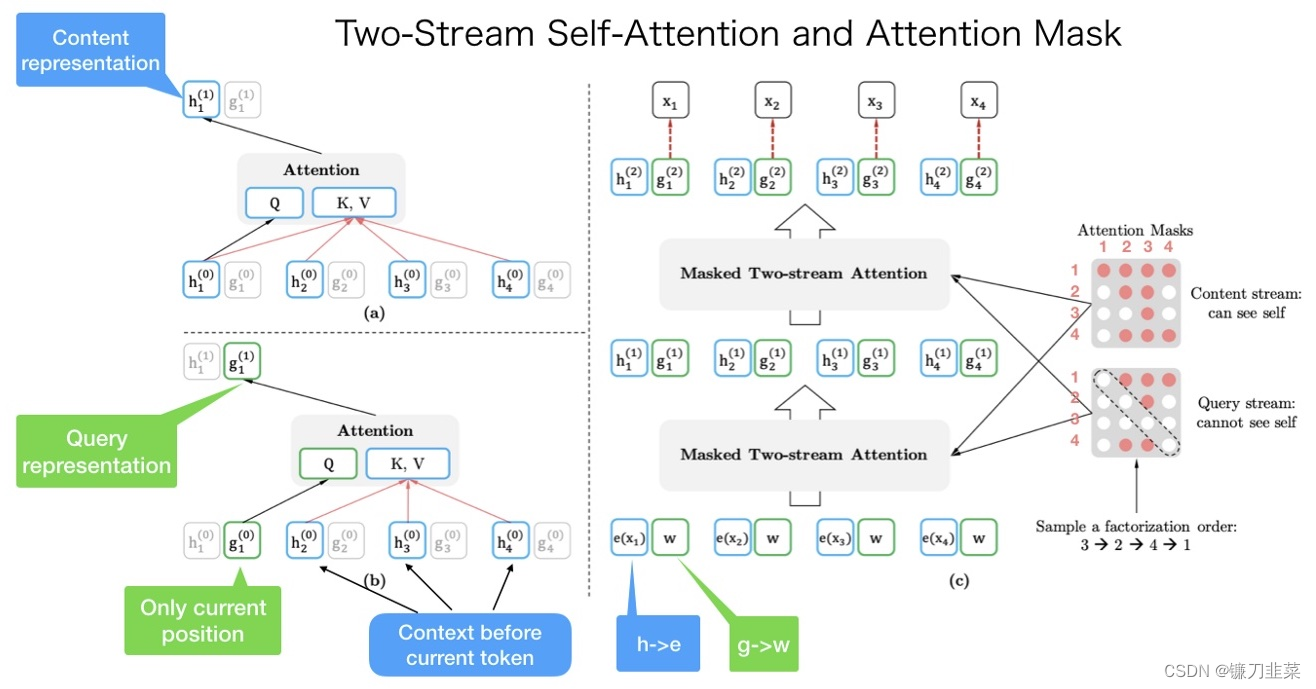
图2 目标感知表征的双流自注意力。(a)Content stream attention,这和标准的self-attention是一样的。(b)Query stream attention,它没有关于内容 x z t x_{z_t} xzt的access信息.(c)双流注意力下的排列语言建模训练概述。
正如名称所示,two-stream self-attention包含两种类型的自注意力。一种是content stream attention,这是Transformer中的标准自注意力。另一种是query stream attention。XLNet引入了它来替代BERT中的[MASK]标记。
例如,如果BERT想要在具有上下文词 x 1 x_1 x1和 x 2 x_2 x2的知识的情况下预测 x 3 x_3 x3,它可以使用[MASK]来代表 x 3 x_3 x3标记。[MASK]只是一个占位符。而 x 1 x_1 x1和 x 2 x_2 x2的嵌入包含了位置信息,帮助模型“知道”[MASK]是 x 3 x_3 x3。
但是对于XLNet来说情况不同。一个token x 3 x_3 x3将具有两种角色。当它被用作内容来预测其他标记时,我们可以使用content representation(通过内容流注意力学习)来代表 x 3 x_3 x3。但是如果我们想要预测 x 3 x_3 x3,我们只应该知道它的位置而不知道它的内容。这就是为什么XLNet使用query representation(通过查询流注意力学习)来保留 x 3 x_3 x3之前的上下文信息,只包含 x 3 x_3 x3的位置信息。
为了直观理解双流自注意力,我们可以将XLNet中的[MASK]替换为查询表示,这样就可以简单地理解。它们只是选择了不同的方法来完成相同的任务。
这样就能利用Query Stream 在对需要预测位置进行预测的同时,又不会泄露当前位置的内容信息。具体操作就是用两组隐状态(hidden states) g g g 和 h h h。其中 g g g 只有位置信息,作为 Self-Attention 里的 Q。 h h h 包含内容信息,则作为 K 和 V。
如图2所示,从图中来看,句子的原始顺序是 [ x 1 , x 2 , x 4 , x 4 ] [x_1,x_2,x_4,x_4] [x1,x2,x4,x4]。我们随机得到一个因式分解顺序(factorization order) [ x 3 , x 2 , x 4 , x 1 ] [x_3,x_2,x_4,x_1] [x3,x2,x4,x1]。左上角表示的是内容表征(content representation)的计算。如果我们想要预测 x 1 x_1 x1的内容表征,我们应该有来自所有四个tokens的token内容信息。 K V = [ h 1 , h 2 , h 3 , h 4 ] K_V=[h_1,h_2,h_3,h_4] KV=[h1,h2,h3,h4]并且 Q = h 1 Q=h_1 Q=h1。左下角表示的是查询表征(query representation)的计算。如果我们向预测 x 1 x_1 x1的查询表征,我们看不到 x 1 x_1 x1本身的内容表示。 K V = [ h 2 , h 3 , h 4 ] K_V=[h_2,h_3,h_4] KV=[h2,h3,h4]并且 Q = g 1 Q=g_1 Q=g1。
右图是整个计算过程。我们从下到上看,首先 h ( ⋅ ) h(\cdot) h(⋅)和 g ( ⋅ ) g(\cdot) g(⋅)分别被初始化为 e ( x i ) e(x_i) e(xi)和 w w w。然后由内容掩码(Content Mask)和查询掩码(Query Mask)计算第一层的输出 h ( 1 ) h(1) h(1)和 g ( 1 ) g(1) g(1),接着计算第二层,第三层等。
注意最右边的内容掩码和查询掩码。它们都是矩阵。先看内容掩码,它的第一行有4个红点,表示第一个token( x 1 x_1 x1)可以关注(attend to)其他所有的token,包括它本身(即 x 3 − > x 2 − > x 4 − > x 1 x_3->x_2->x_4->x_1 x3−>x2−>x4−>x1)。第二个行有两个红点,表示第二个token( x 2 x_2 x2)可以关注(attend to)两个token( x 3 − > x 2 x_3->x_2 x3−>x2)。而查询掩码和内容掩码的区别就是不能关注自己,因此对角线都是白点。
总而言之: 输入句只有一个顺序。但是我们可以使用不同的注意掩码(attention mask)来实现不同的因式分解顺序(factorization orders)。
Autoregressive vs. Autoencoder Models
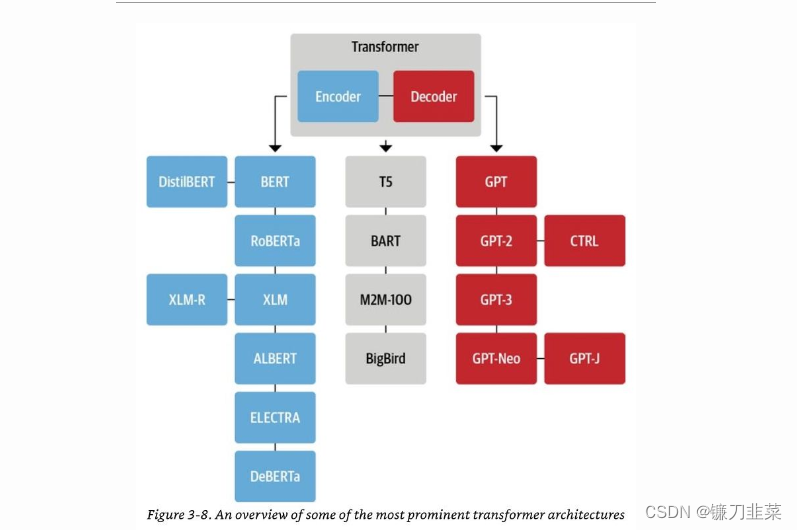
无监督表示学习(Unsupervised representation learning)在自然语言处理领域取得了极大的成功。通常,这些方法首先在大规模无标签文本语料库上对神经网络进行预训练,然后在下游任务上微调模型或表示。在这个共享的高级思想下,文献中探索了不同的无监督预训练目标。其中,自回归(autoregressive,AR)语言建模和自编码(autoencoding,AE)是最成功的两种预训练目标。将这一点与Transformer架构联系起来,Transformer encoder是一个AE模型,而Transformer decoder 是一个AR模型。
以下的树形图示意图(来源)展示了Transformer编码器/AE模型(蓝色)、Transformer解码器/AR模型(红色)以及Transformer编码器-解码器/seq2seq模型(灰色):
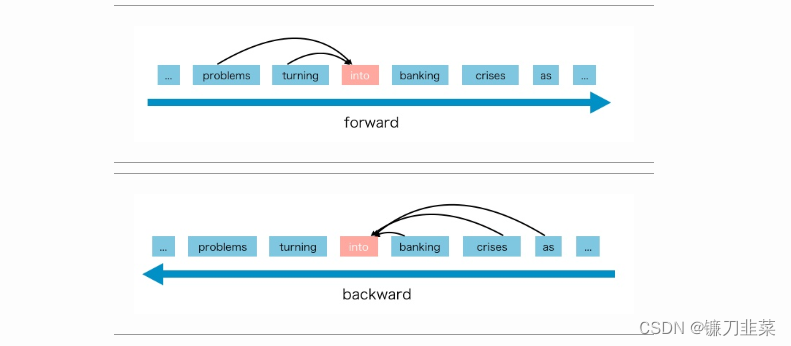
AR模型从一系列时间步骤中学习,并将先前操作的测量作为回归模型的输入,以预测下一个时间步的值。AR模型通常用于生成任务,例如自然语言生成(NLG)领域的任务,例如摘要、翻译或抽象问题回答等。代表有 ELMO, GPT等。
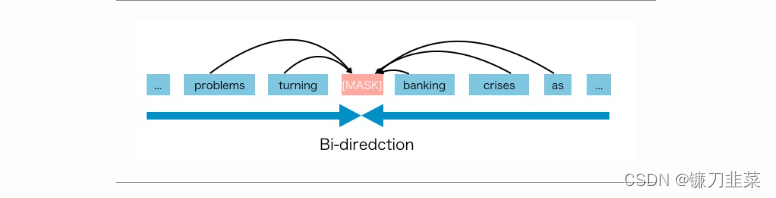
基于AE的预训练不执行显式的密集估计,而是旨在从损坏的输入中重建原始数据(“以空白填充”)。AE模型通常用于内容理解任务,例如涉及分类的自然语言理解(NLU)领域的任务,例如情感分析或抽取性问题回答等。一个著名的例子是BERT,它一直是最先进的预训练方法。在给定输入标记序列的情况下,某些标记的一部分被特殊符号[MASK]替换,模型被训练以从损坏的版本中恢复原始标记。
AE语言模型旨在从损坏的输入中重建原始数据。由于密集估计不是目标的一部分,BERT允许利用双向上下文进行重建。作为一个直接的好处,这弥合了AR语言建模中提到的双向信息差距,从而提高了性能。然而,BERT在预训练期间使用的[MASK]等人工符号在微调时从真实数据中消失,导致了预训练和微调之间的不一致。此外,由于输入中的预测标记被屏蔽,BERT不能像AR语言建模中的乘法规则那样对联合概率进行建模。换句话说,BERT假设给定未屏蔽标记的情况下,预测的标记彼此独立,这是一种过于简化,因为自然语言中存在高阶、长距离的依赖性。
使用掩码语言建模作为预训练AE模型的常见训练目标,我们预测损坏的输入中被屏蔽标记的原始值。BERT(以及其所有变体,如RoBERTa、DistilBERT、ALBERT等)、XLM都是AE模型的示例。
ALBERT方法
BERT、GPT等模型都有不同的版本。在很多情况下,如果语料库充足,模型规模越大,性能会越好,但是也有例外的情况,即模型规模越大,参数越多,性能反而越低,这被称为模型退化(Model Degradation)。

从原始论文中给出的图中,我们可以看到性能是如何下降的。BERT-xlarge的性能比BERT-large差,尽管它更大,参数也更多。
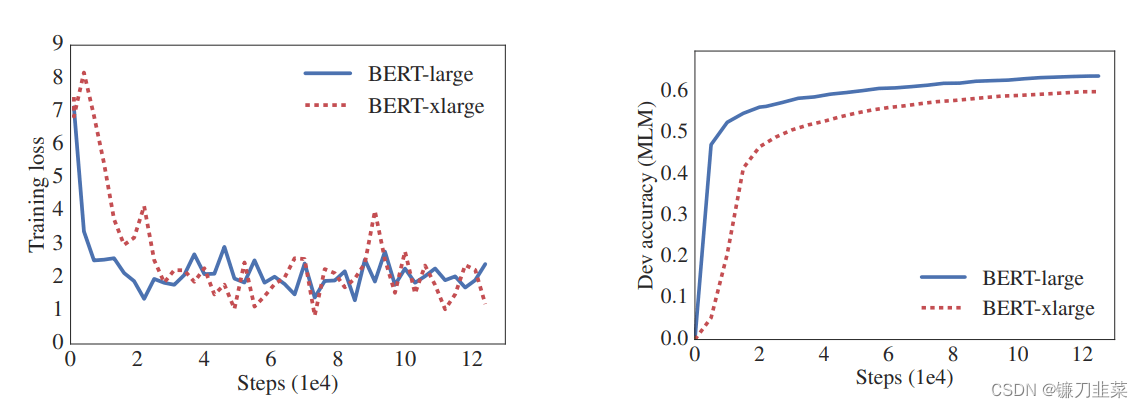
如何在降低模型复杂度的同时保持性能不变,甚至提高性能呢?ALBERT就是其中一个方法。

论文摘要:增加自然语言表示预训练模型的大小通常会在下游任务上提高性能。然而,某一点之后,由于GPU/TPU内存限制和更长的训练时间,进一步增加模型规模变得更加困难。为了解决这些问题,我们提出了两种参数减少技术,以降低内存消耗并提高BERT的训练速度。广泛的实证证据表明,我们提出的方法使模型相对于原始的BERT能够更好地扩展。我们还使用了一种自监督损失,重点是建模句子间的一致性,并且展示了它在具有多句输入的下游任务中能够始终提供帮助。因此,我们的最佳模型在GLUE、RACE和\squad基准测试上建立了新的最先进结果,同时与BERT-large相比具有更少的参数。
简单地,ALBERT(A lite BERT)减少了参数量,但维持了BERT的性能,但它只是降低了空间复杂度,把参数量从108M降到了12M,但并没有降低时间复杂度。即ALBERT降参数量,但不减计算量。
那么,ALBERT是怎么降低参数量?
- Factorized embedding parameterization(词嵌入的因式分解):把词嵌入矩阵进行分解,分解成更少的两个矩阵。
- Cross-layer parameter sharing(交叉层的参数共享):这种技术在深层的网络中更能减少参数。
参数减少技术像是一种正则化方法。ALBERT会比BERT-large的参数量少18倍,同时训练速度快1.7倍。
ALBERT还提出了另一种方法,用来代替NSP(Next-Sentence Prediction Loss)技术,这种新技术叫Sentence-Order Prediction (SOP)。SOP是一种Self-Supervised Loss。
因此,ALBERT利用了三种技术:
- factorized embedding parameterization(词嵌入的因式分解)
- cross-layer parameter sharing(交叉层的参数共享)
- sentence-order prediction (SOP,句子顺序预测)
ALBERT的骨干结构是BERT模型,同时使用了GELU激活函数。定义词典的大小为 E E E,encoder的层数为 L L L,隐藏层的大小为 H H H,attention head为 H / 64 H/64 H/64。
1. 分解Vocabulary Embedding矩阵
在BERT以及随后的建模改进(如XLNet和RoBERTa)中,WordPiece embeddings E E E与transformer隐藏层大小 H H H是绑定在一起的,即 E ≡ H E ≡ H E≡H。这些embeddings是从一个包含30,000个词汇的one-hot编码表示中学习得到的。它们直接投射到隐藏层的隐藏空间中。
假设我们有一个大小为30,000的词汇表,word-piece embedding的维度为 E = 768 E=768 E=768,隐藏层的大小为 H = 768 H=768 H=768。如果我们增加块中的隐藏单元,那么我们也需要为每个embedding添加一个新的维度。这个问题在XLNET和ROBERTA中也很常见。
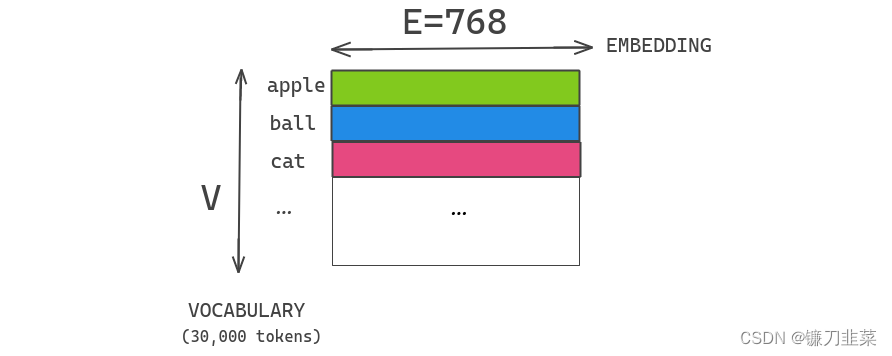
出于建模和实际原因,这个决定似乎都不是最优选择,具体原因如下:
- 从建模的角度来看,WordPiece embeddings的目的是学习与上下文无关(context-independent)的表示,而隐藏层embeddings的目的是学习与上下文相关(context-dependent)的表示。正如对上下文长度的实验所表明的那样(Liu等人,2019),类似BERT的表示的强大之处在于利用上下文来提供学习这种上下文相关表示的信号。因此,将WordPiece embeddings大小 E E E与隐藏层大小 H H H解耦,允许我们更有效地使用总模型参数,根据建模需求,需要满足 H > > E H >> E H>>E的条件。
- 从实际角度来看,通常词典大小 V V V是非常大的,如果 E ≡ H E\equiv H E≡H,增加 H H H 的大小,会使得embedding matrix V × E V\times E V×E 非常大,从而造成模型参数过大,训练速度减慢。
因此,ALBERT通过将大词汇表嵌入矩阵分解成两个较小的矩阵来解决了这个问题。这样可以将隐藏层的大小与词汇表嵌入的大小分开。这使得我们可以增加隐藏层的大小,而不会显著增加词汇表嵌入的参数大小。
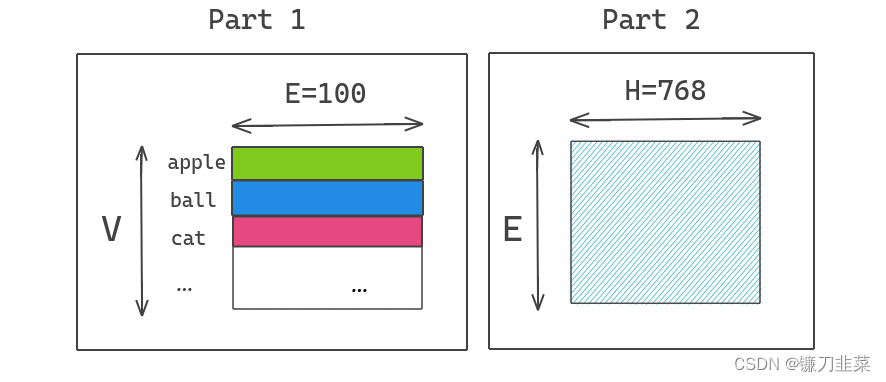
我们将One Hot编码向量投影到较低维度的嵌入空间,维度为 E = 100 E=100 E=100,然后将这个嵌入空间投影到隐藏空间 H = 768 H=768 H=768。ALBERT通过使用分解的方法,把embedding矩阵参数分解成两个矩阵。也即是把参数量 O ( V × E ) O(V\times E) O(V×E)变为 O ( V × E + E × H ) O(V\times E+E\times H) O(V×E+E×H)
在实现时,随机初始化 V × E V\times E V×E和 E × H E\times H E×H的矩阵,计算某个单词的表示需用一个单词的one-hot向量乘以 V × E V\times E V×E 维的矩阵(也就是lookup),再用得到的结果乘 E × H E\times H E×H 维的矩阵即可。两个矩阵的参数通过模型学习。
我们选择对所有的word pieces使用相同的 E E E,因为它们在文档中的分布要比whole-word embedding均匀得多,而在whole-word embedding中,为不同的词选择不同的嵌入大小是重要的。
上述矩阵分解过程代码如下(参考代码为PyTorch版ALBERT):
class AlbertEncoder(nn.Module):
def __init__(self, config):
super(AlbertEncoder, self).__init__()
self.hidden_size = config.hidden_size
self.embedding_size = config.embedding_size
self.embedding_hidden_mapping_in = nn.Linear(self.embedding_size, self.hidden_size)
self.transformer = AlbertTransformer(config)
def forward(self, hidden_states, attention_mask=None, head_mask=None):
if self.embedding_size != self.hidden_size:
prev_output = self.embedding_hidden_mapping_in(hidden_states)
else:
prev_output = hidden_states
outputs = self.transformer(prev_output, attention_mask, head_mask)
return outputs # last-layer hidden state, (all hidden states), (all attentions)
class AlbertEmbeddings(nn.Module):
"""Construct the embeddings from word, position and token_type embeddings.
"""
def __init__(self, config):
super(AlbertEmbeddings, self).__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.embedding_size, padding_idx=0)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.embedding_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.embedding_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
self.LayerNorm = AlbertLayerNorm(config.embedding_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, input_ids, token_type_ids=None, position_ids=None):
seq_length = input_ids.size(1)
if position_ids is None:
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand_as(input_ids)
if token_type_ids is None:
token_type_ids = torch.zeros_like(input_ids)
words_embeddings = self.word_embeddings(input_ids)
position_embeddings = self.position_embeddings(position_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = words_embeddings + position_embeddings + token_type_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
2. 跨层的参数共享
Bert大型模型有24层,而其基本版本有12层。当我们添加更多层时,我们会呈指数级增加参数的数量。

为了解决这个问题,ALBERT使用了跨层参数共享(cross-layer parameter sharing)的概念。为了进行说明,我们来看一个12层BERT基础模型的示例。我们不学习12层中每一层的唯一参数,而是只学习第一个块的参数,并在其余11层中重用该块。
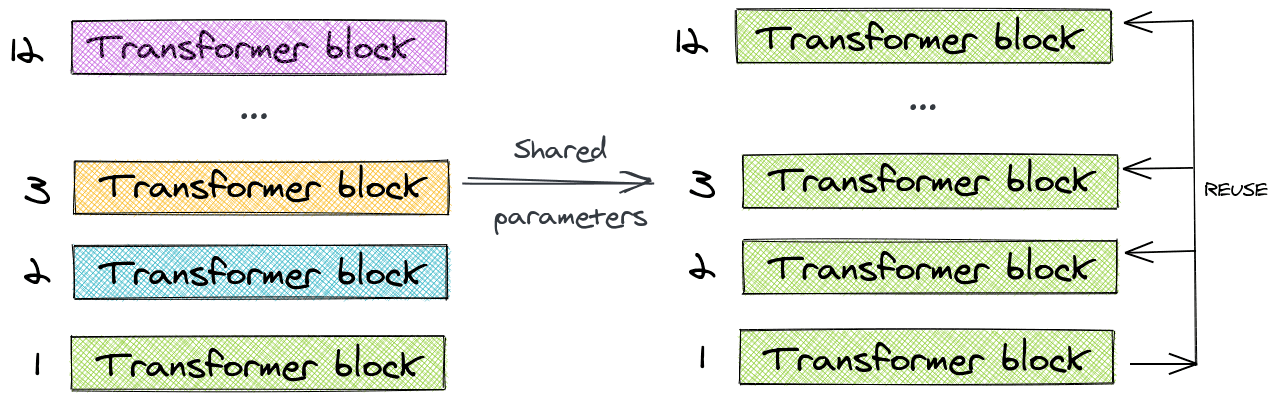
我们可以只共享前馈层的参数,或者只共享注意力参数,或者共享整个块本身的参数。本文分享了整个block的参数。
与BERT基础的1.1亿个参数相比,ALBERT模型在使用相同层数和768个隐藏单元的情况下只有3100万个参数。对于128的嵌入大小,对精度的影响是最小的。精度的主要下降是由于前馈网络参数共享。共享注意力参数的影响是最小的。
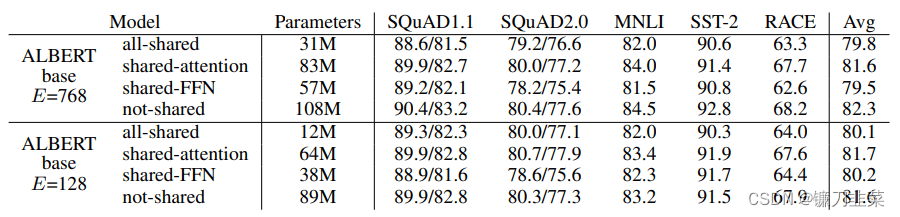
图:跨层参数策略对性能的影响
在Albert的源码中,模型的参数共享是通过modeling_utils中PreTrainedModel的_tie_or_clone_weights实现的。PreTrainedModel作为基类实现了_tie_or_clone_weights,它的子类在init_weight之后调用tie_weight实现参数共享。而tie_weight的核心就是_tie_or_clone_weights。

3. 使用SOP代替NSP
BERT使用了NSP(next-sentence prediction)作为loss,NSP是一个二分类问题。训练的正样本是一个文档中连续的句子,负样本是不同文档中的句子。但是后续的研究发现NSP的效果并不可靠,主要原因是NSP的任务过于简单。
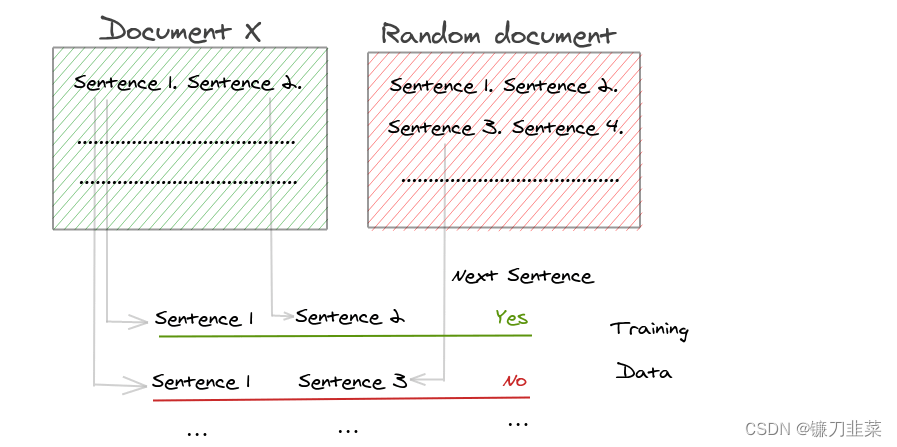
图. Next Sentence Prediction
NSP主要包含了两个任务,主题预测和一致性预测,相比于一致性预测,主题预测更加简单,而且和MLM所学习的重叠了。因为正样本的来自同一文档中,而负样本来自不同的文档,例如前一句来自娱乐新闻,而后一句来自社会新闻,两句话不连贯,而且不是一个主题,差异性可能比较大。
MLM类似于完形填空,模型需要来预测[MASK]的词。MLM的训练样本是连续的文本流,这些训练文本都是出自一个主题。这也是为什么和NSP有所重合的原因。
ALBERT关注句子的一致性问题,提出新的任务SOP(sentence-order prediction),正样本获取方法和Bert相同。负样本是将连续的句子互换顺序。这也使模型专注于句子连续性的预测。
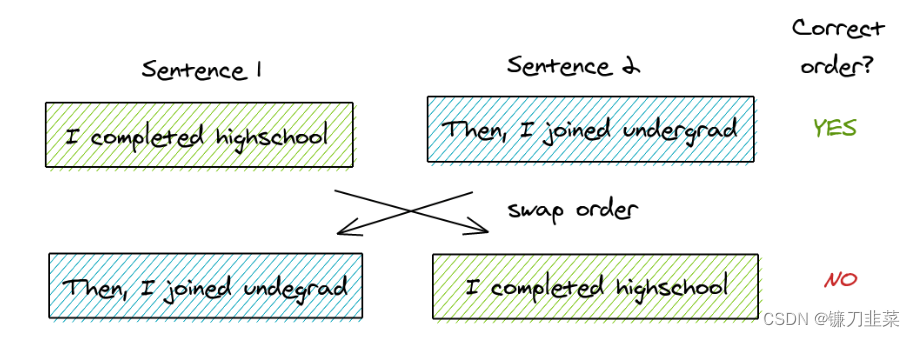
图 Sentence Order Prediction,将同一文档中的两个连续段作为正类,交换相同段的顺序,并将其作为反例使用。这迫使模型学习关于语篇层次连贯特性的更细粒度的区分。
ALBERT提出NSP无效的猜测是因为与掩码语言建模相比,它不是一项困难的任务。在单一任务中,它同时包含了主题预测和连贯性预测。主题预测部分容易学习,因为它与掩码语言模型的损失重叠。因此,即使没有学习到连贯性预测,NSP也会给出较高的分数。
4. 其他优化方法
其他优化方法如下:
1)由BERT直接对字进行掩码,改为n-gram掩码,其中n取值为1~3,这样在一定程度上避免[MASK]之间的独立问题。对中文进行分词,对词的掩码运算的性能会比对字的掩码运算的性能有一定的提升。
2)删除dropout。因为BERT在训练的时候没有出现过拟合的现象,因此删除dropout。
ELECTRA方法
现有的预训练方法通常分为两类。第一类是语言模型(LM),例如ELMo、GPT、GPT-2等,按照从左到右(或从右到左)的顺序处理文本,然后在给定先前上下文的情况下,预测下一个单词。另一类是掩码语言模型(MLM),例如BERT和ALBERT,这类模型分别预测输入中已被屏蔽的少量单词内容。
相比LM,MLM具有双向预测的优点,但是这类模型的预测仅限于输入标识符很小的子集(输入序列的15%),从而减少了它们从每个句子中获得信息的量,增加了计算成本。此外,因测试部分没有MASK标注,可能导致训练与测试阶段不一致等问题,影响模型的性能。
为了克服MLM的缺点,提出了XLNet的方法,它使用排列语言模型取得比较好的效果,但是XLNet由于预训练的每一轮都是按掩码矩阵的行、列排列,而微调阶段是普通的Transformer处理。
为了进一步提升预训练语言模型的学习效率,我们提出了RTD(replaced token detection)任务作为MLM任务的替代品——这是一种架构有点类似于GAN的学习任务,首先通过一个较小的Generator对BERT中的特殊token [MASK]进行替换,然后再训练一个Discriminator对input中的每个单词进行预测,即模型会从input序列中的全部tokens进行学习,这有别于BERT的15%,而我们认为这也是使得ELECTRA训练比BERT更快的原因。如图所示,ELECTRA总能使用更少的算力、更少的模型参数,达到比BERT等模型更好的结果。
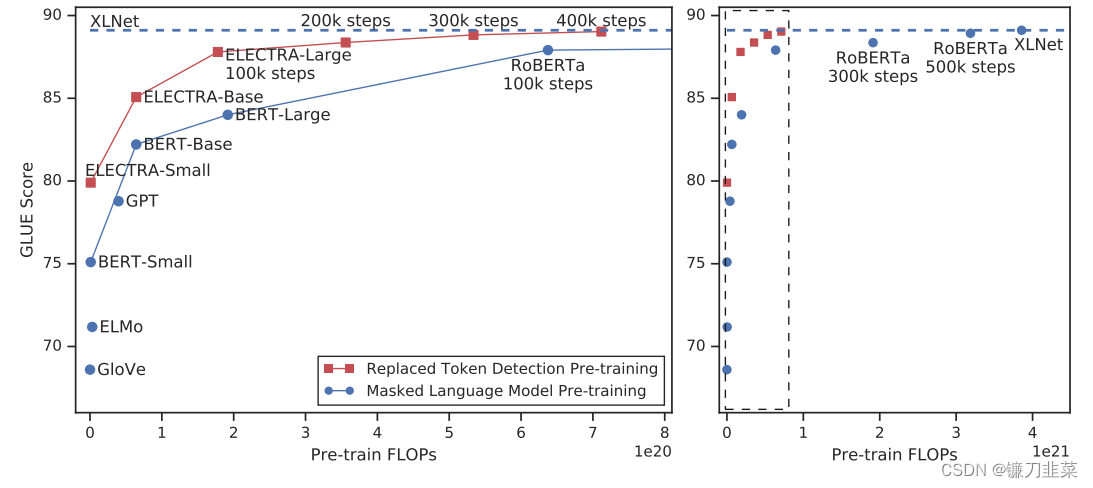
图. 替代标记检测预训练(Replaced token detection pre-training)在相同的计算资源预算下始终优于掩码语言模型预训练(masked language model pre-training)。左图是虚线框的放大视图。纵轴是GLUE分数,横轴是FLOPs (floating point operations),Tensorflow中提供的浮点数计算量统计。从上图可以看到,同等量级的ELECTRA是一直碾压BERT的,而且在训练更长的步数之后,达到了当时的SOTA模型——RoBERTa的效果。从左图曲线上也可以看到,ELECTRA效果还有继续上升的空间。
1. ELECTRA概述
ELECTRA 的创新点在于:
- 提出了新的模型预训练的框架,采用生成器(Generator)和判别器(Discriminator)的结合方式,但又不同于GAN。ELECTRA模型采用的是最大似然估计而非对抗学习
- 把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
- 在生成器Generator部分,仍然采用MLM,因为Masked Language Model 能有效地学习到context信息,即利用这个模型可对挖掉的15%的词进行预测,并对其进行替换,若替换的词不是原词,则打上被替换的标签,语句的其他词会打上没有替换的标签,所以它能很好地学习词的embedding,并且使用了Weight Sharing的方式将Generator的embedding的信息共享给Discriminator
- Dicriminator 预测了Generator输出的每个token是不是original的,从而高效地更新Transformer的各个参数,使得模型的熟练速度加快,此时预测模型转换成了一个二分类模型。这个转换可以带来效率的提升,对所有位置的词进行预测,收敛速度会快得多。
- 该模型采用了小的Generator以及Discriminator的方式共同训练,并且采用了两者Loss相加,使得Discriminator的学习难度逐渐地提升,学习到更难的token(plausible tokens)
- 模型在fine-tuning 的时候,丢弃Generator,只使用Discriminator。
2. RTD结构
由于BERT的MLM的实现,并不是非常高效的,只有15%的tokens对参数的更新有用,其他的85%是不参与gradients的update的,并且存在了预训练和fine-tuning的mismatch,因为在fine-tuning阶段,并不会有[MASK]的token。
因此ELECTRA采取了一个新的结构,并且使用了新的预训练task:RTD(Replaced Token Detection,替换标记探测),即判断每个样例的所有词汇是不是被替换过,加快训练速度。如下所示:
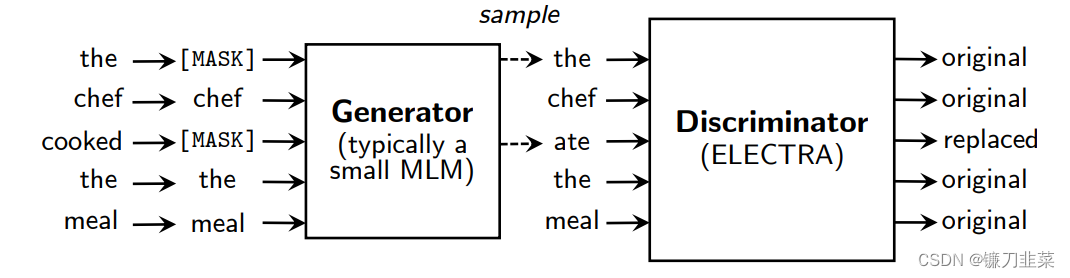
图. Replaced token detection示意图。Generator可以是任意模型,它的任务是对被随机mask掉的token进行预测,它一般是一个较小的BERT模型,与discriminator一起进行训练,而discriminator的任务就是分辨出到底哪个token是被generator篡改过以致于和原token不一致的。尽管这些模型的结构类似于GAN,但我们使用最大似然而不是对抗训练来训练生成器,因为将GAN应用于文本领域存在困难。在预训练之后,我们丢弃了生成器,仅在下游任务中对鉴别器(ELECTRA模型)进行微调。
该模型由两部分组成,分别是生成器以及判别器,两个都是Transformer的Encoder结构,只是两者的大小不同:
-
生成器
生成器即一个小的 Masked Language Model(通常是 1/4 的discriminator的size),该模块的具体作用是它采用了经典的BERT的MLM方式:- 首先随机选取15%的tokens,替代为[MASK]token(它取消了BERT的80%[MASK],10%unchange, 10% random replaced 的操作,具体原因也是因为没必要,因为我们finetuning使用的判别器)
- 然后,使用Generator去训练模型,使得模型预测Masked token,得到损坏的标记(corrupted tokens)。Generator的目标函数和BERT一样,都是希望被Masked的能够被还原成原本的Original tokens(如上图所示, token,
the和cooked被随机选为被masked,然后generator预测得到corrupted tokens,变成了the和ate)
-
判别器
判别器的接收被生成器改写之后的输入,Discriminator的作用是分辨输入的每一个token是original的还是replaced,注意:如果generator生成的token和原始token一致,那么这个token仍然是original的。所以,对于每个token,discriminator都会进行一个二分类,最后获得loss
以上的方式被称为Replaced Token Detection。
3. 损失函数
具体来说,生成器G和判别器D是我们训练得到的两个神经网络,二者都包含encoder(即Transformer网络),从而将input序列从 x = [ x 1 , . . . , x n ] x=[x_1,...,x_n] x=[x1,...,xn]映射到 h ( x ) = [ h 1 , . . . , h n ] h(x)=[h_1,...,h_n] h(x)=[h1,...,hn]。而二者的任务又是不同的,生成器的训练目标还是MLM(作者在后文也验证了这种方法更好),判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器。所以我们会选择不同的损失函数对它们的错误进行衡量。目标函数如下:
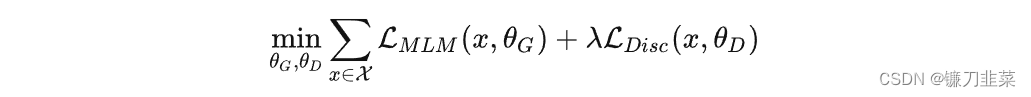
因为判别器的任务相对来说容易些,RTD loss相对MLM loss会很小,因此加上一个系数,作者训练时使用了50。
另外要注意的一点是,在优化判别器时计算了所有token上的Loss,而以往计算BERT的MLM loss时会忽略没被Mask的token。作者在后来的实验中也验证了在所有token上进行loss计算会提升效率和效果。
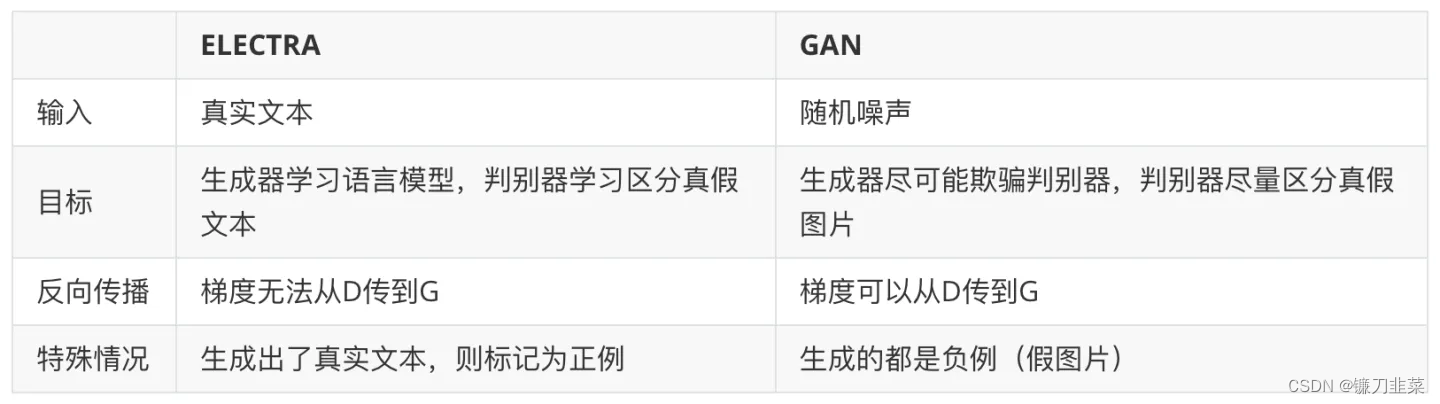
4. ELECTRA与GAN的区别
事实上,ELECTRA使用的Generator-Discriminator架构与GAN还是有不少差别,作者列出了如下几点:
5. ELECTRA的缺点
注意,判别器的二分类属性,导致其可能不适用于下游任务。BERT使用MLM进行预训练然后接下游任务,看起来是足够合理的,因为我们可以认为MLM对全词采样的过程中,其实是给所有token都建立了一个基于其上下文的词表示;然而判别器任务是二分类,也就是将token的表示划分到两个空间中,可能会导致其hidden space中信息的过早退化。
此外,判别器本身是用二分类任务来预训练的,所以当它面对“接近二分类”的任务时会明显有所助益(如GLUE的CoLA任务),但面对诸如序列标注、文本生成等不那么“分类”的任务时,效果可能就较差。
补充:一个使用PyTorch实现的ELECTRA代码
参考资料
- XLNet详解
- ALBERT:轻量级BERT语言模型 ICLR2020
- 超越 BERT 模型的 ELECTRA 代码解读
- ELECTRA中文预训练模型开源,仅1/10参数量,性能依旧媲美BERT
- XLNet: Generalized Autoregressive Pretraining for Language Understanding
- Hugging face: XLNet
- XLNet Fine-Tuning Tutorial with PyTorch
- Understand how the XLNet outperforms BERT in Language Modelling
- Autoregressive vs. Autoencoder Models
- ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- BERT和ALBERT
- Visual Paper Summary: ALBERT (A Lite BERT)
- ELECTRA 详解
- ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators