本文首发于 CVHub,白名单账号转载请自觉植入本公众号名片并注明来源,非白名单账号请先申请权限,违者必究。

Title: LightGlue: Local Feature Matching at Light Speed
Paper: https://arxiv.org/pdf/2306.13643.pdf
导读
本文介绍了LightGlue,这是基于深度学习局部特征匹配方法。论文重新审视了SuperGlue的多个设计决策,这是稀疏匹配领域的最新技术,并得出了简单但有效的改进方法。这些改进使得LightGlue在内存和计算方面更加高效,更准确,并且更容易训练。其中一个关键特性是LightGlue对问题的难度是自适应的:对于直观上易于匹配的图像对,例如具有更大的视觉重叠或有限的外观变化,推理速度更快。这为在对延迟敏感的应用中部署深度匹配器(例如3D重建)打开了令人兴奋的前景。
贡献


本文的主要贡献可以总结如下:
-
设计了LightGlue,一种深度网络,如图1所示,在准确性、效率和训练易用性方面优于现有的SuperGlue。通过对架构进行简单而有效的修改,提出了训练高性能深度特征匹配器的方法。
-
LightGlue具有自适应的特性,可以根据图像对的难度进行灵活调整。如图2所示,通过预测对应关系并允许模型自省,可以在易于匹配的图像对上实现更快的推理速度,而在具有挑战性的图像对上仍然保持准确性。
-
LightGlue的应用前景广阔,特别适用于对延迟敏感的应用,如SLAM和基于众包数据的更大场景重建。
-
LightGlue的模型和训练代码将以宽松的许可证公开发布,为研究和应用领域提供了有用的资源。
快速特征匹配方法
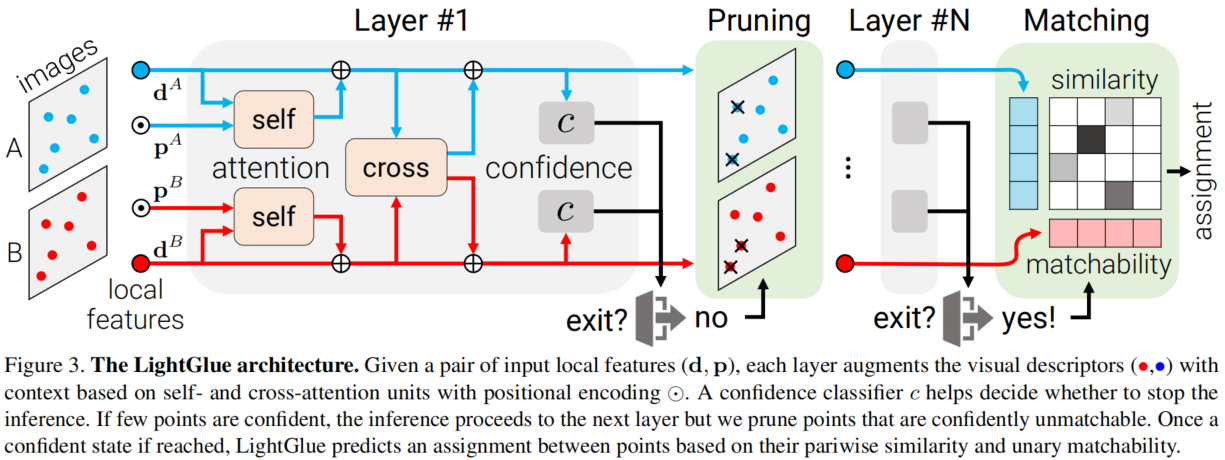
整体网络结构如上图所示,LightGlue是基于SuperGlue的,它预测从图像A和B提取的局部特征集之间的部分匹配关系。LightGlue由L个相同的层组成,这些层共同处理两个特征集合。每个层由自注意力和交叉注意力单元组成,用于更新每个点的表示。然后,一个分类器在每个层次上决定是否停止推理,从而避免不必要的计算。最后,一个轻量级的head从这些表示中计算出部分匹配。
Transformer backbone
输入两个图像上的2D点位置 p p p,以及特征描述子 d d d,每个层由一个自注意力单元和一个交叉注意力单元组成。
Self-attention
每个点都关注同一图像中的所有点。对于每个点 i i i,当前状态 x i x_i xi通过线性变换分解为键向量 k i k_i ki和查询向量 q i q_i qi。使用旋转编码 R R R来定义点 i i i和 j j j之间的注意力得分 a i j a_{ij} aij,以捕捉它们的相对位置:

通过将空间分割为 d 2 \frac{d}{2} 2d个2D子空间,并进行旋转投影到可学习的基向量 b k b_k bk上,实现了位置编码。旋转编码使模型能够检索到具有学习到的相对位置的点 j j j。这种编码在所有层中都是相同的,并且只计算一次并缓存。
Cross-attention
**每个图像中的点都会关注另一个图像中的所有点。**论文为每个元素计算一个键 k i k_i ki,但没有query。双向注意力得分为:

由于相对位置在图像间没有意义,论文不添加位置信息。
特征匹配关系预测
论文设计了一个轻量级的head,在任意层次上根据更新后的状态预测特征匹配情况。
Assignment scores
如图3所示,首先计算两个图像中点之间的成对相似性分数矩阵 S ∈ R M × N S ∈ R^{M\times N} S∈RM×N:

分数表示每对点成为对应关系的亲和性,即相同3D点的2D投影。论文还为每个点计算了一个可匹配性分数(matchability score):

Correspondences
将相似性分数和可匹配性分数结合起来,形成一个soft partial assignment矩阵,具体为:
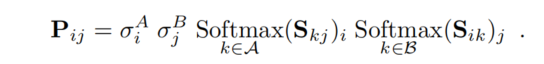
当且仅当两个点都被预测为可匹配,并且它们的相似性高于两个图像中的任何其他点时,点对 ( i , j ) (i,j) (i,j)才会产生对应关系。选择 P i j P_{ij} Pij大于阈值 τ τ τ,并且大于其所在行和列的任何其他元素的点对。
网络自适应深度和宽度
论文设计了一个轻量级的置信度分类器,它预测给定任何层更新状态的分配。置信度分类器帮助决定是否停止推理过程。如果有少数点具有高置信度,则推理过程继续到下一层,但会剪除置信度低的不可匹配点。
Confidence classifier
LightGlue的backbone通过上下文增强输入的视觉描述符。当图像对易于匹配时,早期层的预测结果与后期层的预测结果相同且置信度高。可以输出这些预测结果并停止推理。在每个层结束时,LightGlue使用一个紧凑的MLP推断每个点预测分配的置信度:
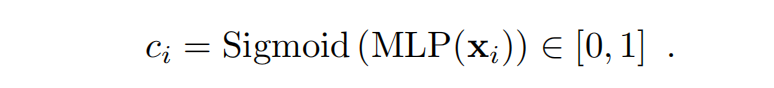
这个策略在语言和视觉任务中被广泛应用。紧凑的MLP仅在推理时间中增加很少的开销,通常能节省更多时间。
Exit criterion
对于给定的层 ℓ \ell ℓ,如果 c i > λ ℓ c_i > \lambda_\ell ci>λℓ,则认为一个点是可信的。如果有足够比例 α \alpha α 的点是可信的,停止推理:
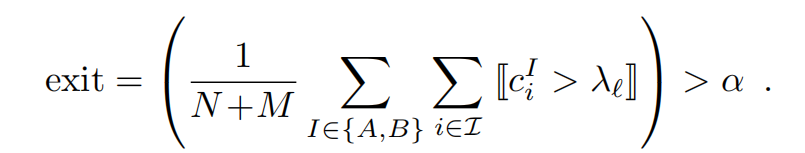
λ ℓ \lambda_\ell λℓ 根据每个分类器的验证准确性逐渐降低, α \alpha α 控制准确性和推理时间的权衡。
Point pruning
当不满足停止准则时,被预测为既可信又不可匹配的点很可能不会在后续层次中对其他点的匹配有帮助。这些点通常位于图像中明显不可见的区域。因此,在每个层次上丢弃这些点,并仅将剩余的点传递到下一个层次。这显著减少了计算量,考虑到注意力的二次复杂度,并且不会影响准确性。
训练策略
论文分为两个阶段训练LightGlue:首先训练它来预测对应关系,然后再训练置信度分类器。因此,后者不会影响最后一层的准确性或训练的收敛性。
Correspondences
使用从两视图单应变换得到的ground truth标签来监督soft partial assignment矩阵P。ground truth真实匹配M是在两个图像中具有低重投影误差和一致深度的点对。通过最小化每个层ℓ预测的分配的对数似然,我们让LightGlue尽早预测正确的对应关系。损失函数如下:

实验
论文从单应变换估计、相对位姿估计和视觉定位三个方向进行评估
单应变换估计

表格1显示,LightGlue在精确度上优于SuperGlue和SGMNet,并且在召回率上相当。当使用DLT方法估计单应性变换时,LightGlue比其他匹配算法获得更准确的估计结果。因此,LightGlue使得简单的求解器DLT在准确性上能够与计算开销高且速度较慢的MAGSAC竞争。在5像素的较大阈值下,尽管受到稀疏关键点的限制,LightGlue仍比LoFTR更准确。
相对位姿估计

表2显示,LightGlue在SuperPoint特征上明显优于现有方法SuperGlue和SGMNet,并且可以大大提高与DISK局部特征的匹配准确性。它产生更好的对应关系和更准确的相对位姿,并且减少了30%推理时间。LightGlue通常比SuperGlue预测稍少的匹配点,但这些匹配点更准确。通过在模型中及早检测到自信的预测,自适应变体比SuperGlue和SGMNet快2倍以上,仍然更准确。通过精心调整的LO-RANSAC,LightGlue的准确性可以超过一些流行的密集匹配算法,而这些算法的速度慢5到11倍之间。在评估的密集匹配算法中,ASPANFormer是最准确的。综合考虑准确性和速度之间的权衡,LightGlue在各种方法中都具有明显的优势。
户外视觉定位
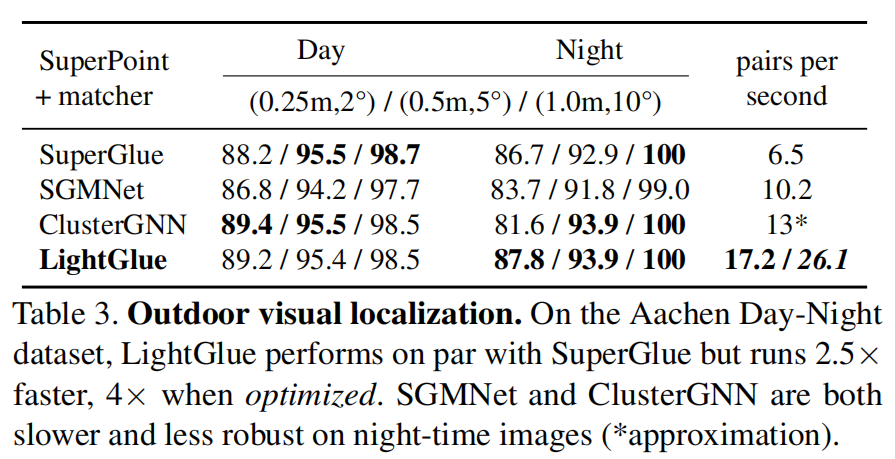
表3显示,LightGlue达到了与SuperGlue相似的准确性,但吞吐量高出2.5倍。经过优化的变体利用高效的自注意力机制,将吞吐量提高了4倍。因此,LightGlue可以实时匹配多达4096个关键点。
总结
本论文介绍了LightGlue,这是一个经过训练的深度神经网络,用于在图像之间匹配稀疏的局部特征。借鉴了SuperGlue的成功,论文将注意力机制的能力与匹配问题的见解以及Transformer的最新创新相结合。论文赋予这个模型自省其预测的置信度的能力。这产生了一种优雅的方案,根据每对图像的难度自适应计算量。模型的深度和宽度都是自适应的:1)如果所有预测都已准备好,推理可以在较早的层停止;2)被认为不可匹配的点从进一步的步骤中提前丢弃。最终得到的模型LightGlue比传统的SuperGlue更快、更准确,并且更容易训练。总之,LightGlue是一个可立即使用的替代方案,只有好处。代码将公开发布,以造福社区。