前言
前面的文章已经展示了如何在windows上传文件到hdfs,上传后如何简单的做统计,本文展示一下。上传文件到HDFS链接
这里我们做一个案例,对一个上传到HDFS的文档中统计good出现的次数。
文件内容如下
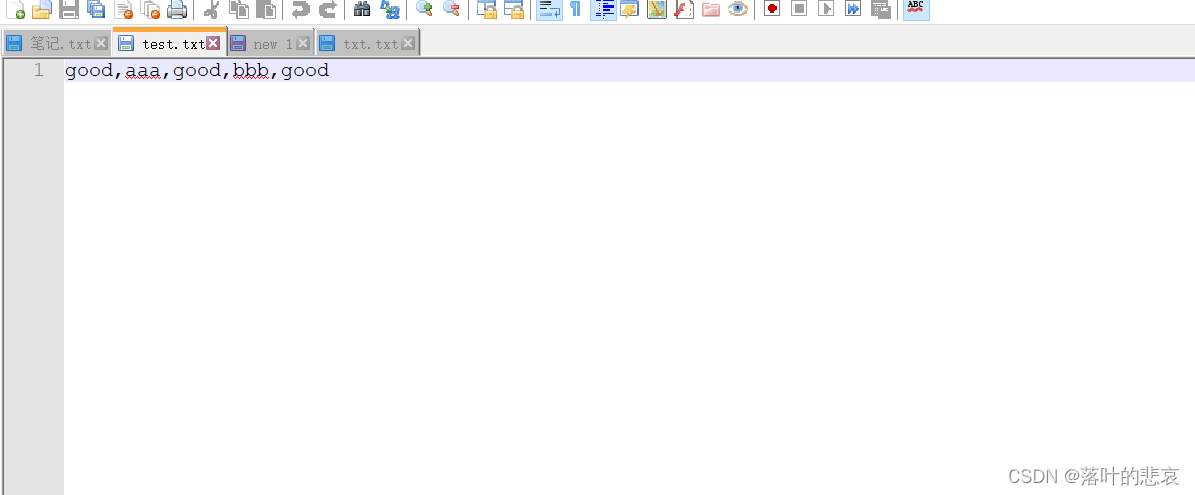
这里我使用的是【上传文件到HDFS链接】中的springboot工程,统计代码中主要用到的包是hadoopcommon包。就直接用那个工程打包了,也可以新建一个maven工程进行编写,但是要引入hadoop相关的包,具体什么包看上面的连接文章
一、流程说明
大致的流程如下,先从hdfs读取数据,然后筛选出符合要求的数据并且做标记,最后使用reduce对各个结果进行汇总,最后的预期结果应该是统计文件内容为
good 3

二、代码编写
2.1 map类
代码如下(示例):
package com.hadoop.demo.service;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountMap extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public WordCountMap() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException, IOException {
String[] split = value.toString().split(",");
System.out.println("map:"+value.toString());
if(split!=null&& split.length>0) {
for (int i = 0; i < split.length; i++) {
if (split[i].equals("good")) {
this.word.set(split[i]);
context.write(this.word, one);
}
}
}
}
}
2.2 reduce类编写
package com.hadoop.demo.service;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Iterator;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public WordCountReduce() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws InterruptedException, IOException {
int sum = 0;
IntWritable val;
for(Iterator i = values.iterator(); i.hasNext(); sum += val.get()) {
val = (IntWritable)i.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
2.3 main类编写
package com.hadoop.demo.service;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class WordCountMain {
public static void main(String[] args) throws InterruptedException, IOException, ClassNotFoundException {
Configuration conf = new Configuration();
//conf.set("demo-0.0.1-SNAPSHOT.jar", "/root/tools/hadoop-3.2.4/demo-0.0.1-SNAPSHOT.jar");
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountMain.class);
//job.setJar("demo-0.0.1-SNAPSHOT.jar");
job.setMapperClass(WordCountMap.class);
job.setCombinerClass(WordCountReduce.class);
job.setReducerClass(WordCountReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[1]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[2]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
三、打包测试
3.1 上传包到hadoop集群,并且执行jar
3.1.1
这里我先使用的是springboot的maven打包命令打包出来的jar,执行jar包命令
hadoop jar demo-0.0.1-SNAPSHOT.jar com.hadoop.demo.service.WordCountMain /mydir /output
这里的输出地址,输入地址也可以使用另一种格式
指定具体的namenode ip加网址。
hdfs://192.168.184.129:8020/output
报错如下
Caused by: java.lang.IllegalArgumentException: LoggerFactory is not a Logback LoggerContext but Logback is on the classpath. Either remove Logback or the competing implementation (class org.slf4j.impl.Reload4jLoggerFactory loaded from file:/root/tools/hadoop-3.2.4/share/hadoop/common/lib/slf4j-reload4j-1.7.35.jar). If you are using WebLogic you will need to add 'org.slf4j' to prefer-application-packages in WEB-INF/weblogic.xml: org.slf4j.impl.Reload4jLoggerFactory
at org.springframework.util.Assert.instanceCheckFailed(Assert.java:702)
at org.springframework.util.Assert.isInstanceOf(Assert.java:621)
解决:
注释掉springboot启动类,重新打包即可
3.1.2 找不到类报错解决
再次打包后测试报错如下
2023-04-11 00:12:22,740 INFO mapreduce.Job: Task Id : attempt_1681178785751_0016_m_000000_2, Status : FAILED
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.hadoop.demo.service.WordCountMap not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2636)
at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:187)
at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:760)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:348)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:174)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1762)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:168)
Caused by: java.lang.ClassNotFoundException: Class com.hadoop.demo.service.WordCountMap not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2540)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2634)
... 8 more
这里网上的答案普遍是:

job.setJarByClass(WordCountMain.class);
替换成
job.setJar("demo-0.0.1-SNAPSHOT.jar");
但是这里并不是这个原因,主要还是maven的打包问题。
解决:
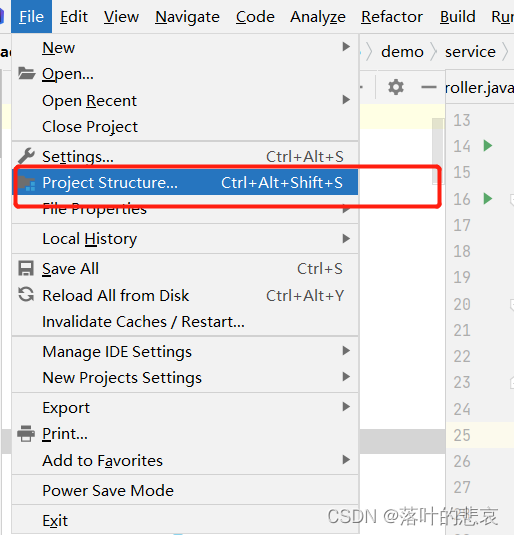
不使用maven的打包方式,使用idea的打包。
1.点击项目结构
2.新增Africa
新增jar
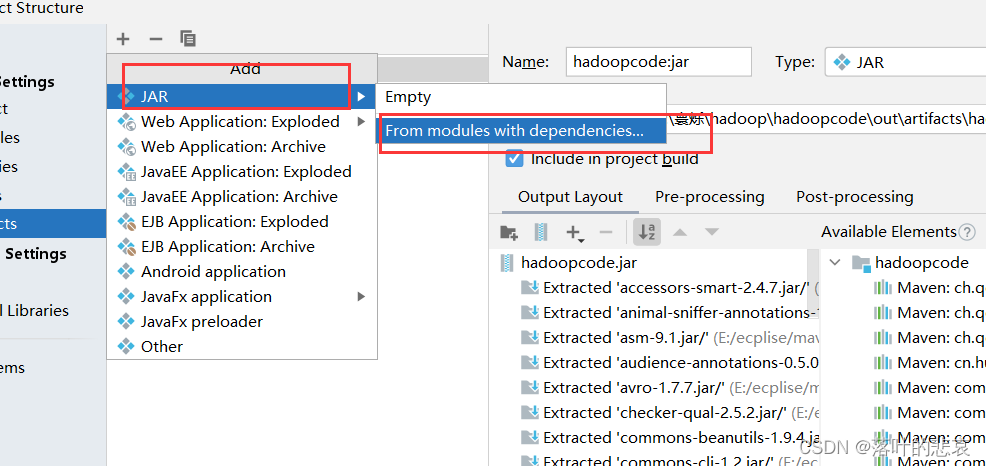
选择如下

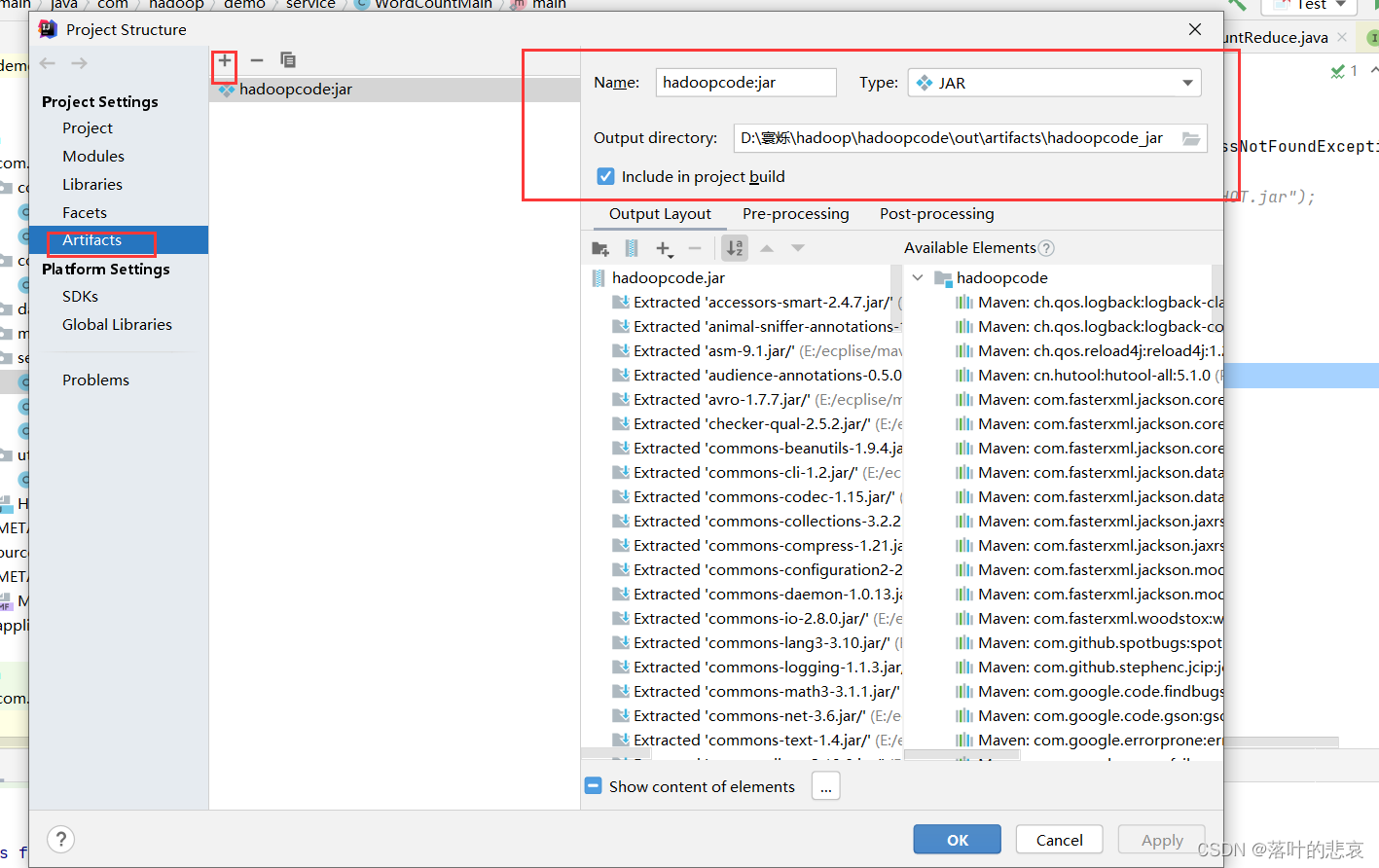
2.新增好了后就可以build了
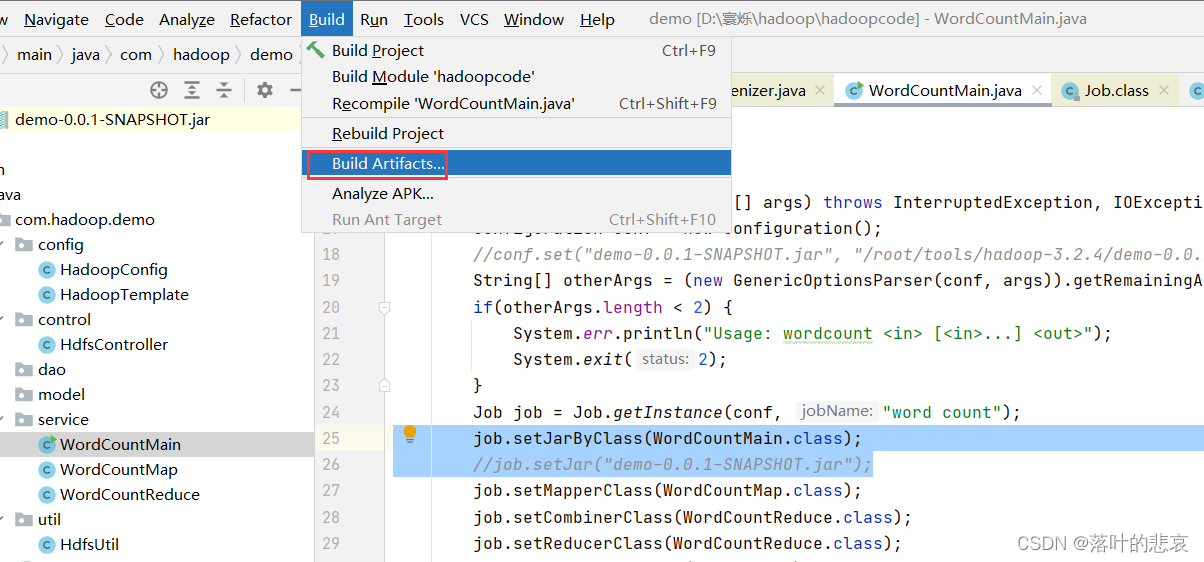
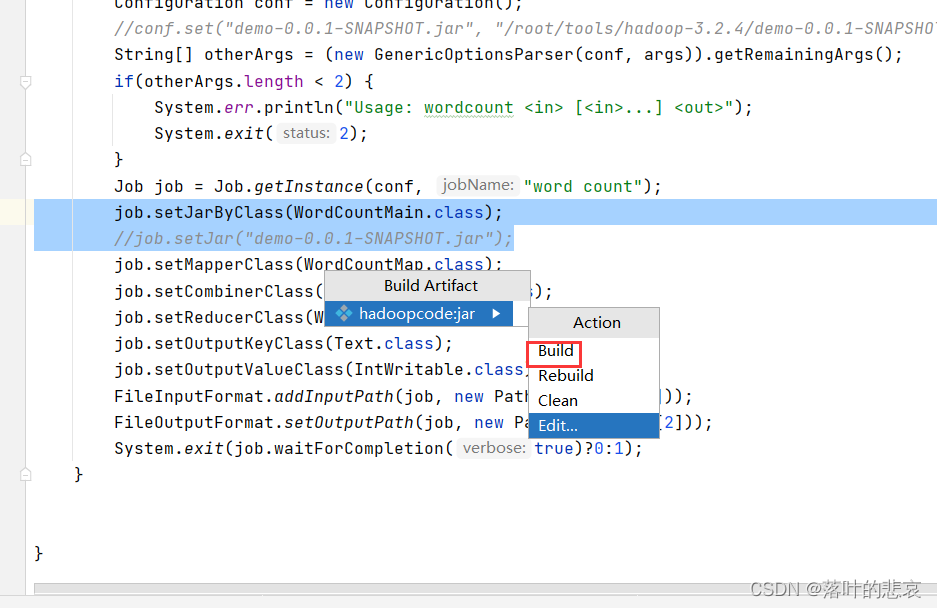
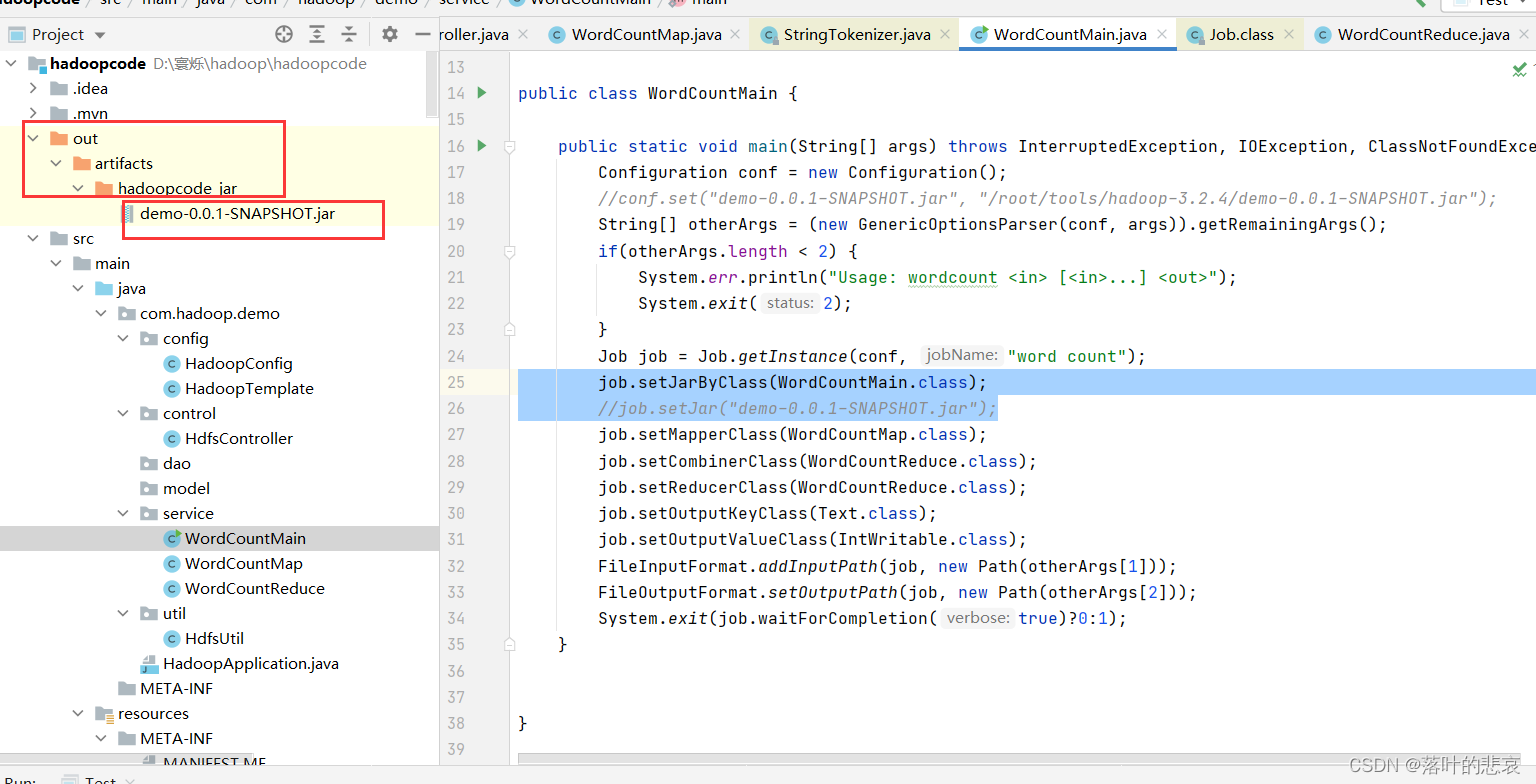
3.build之后就会生成jar包
3.2 重新执行计算的jar包命令
报错如下:
这里是因为之前已经执行过这个jar了,输出路径已经存在了报错,需要执行下命令删除目录
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.184.129:8020/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:164)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:277)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:143)
解决:
执行以下命令,或者namenode管理界面手动删除也可以。
hadoop fs -rm -r /output
3.3 结果
整个输出没有报错才是正常的,
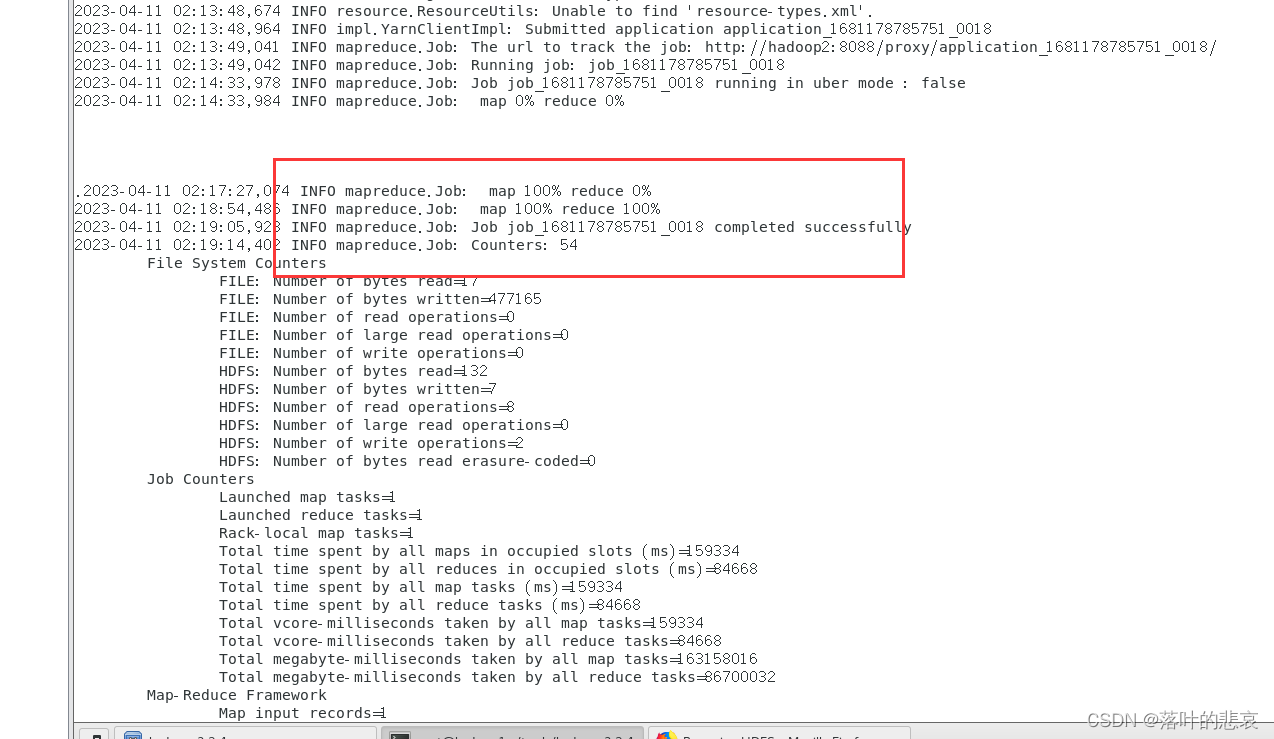
可以使用命令查看输出结果,也可以到namenode查看输出结果
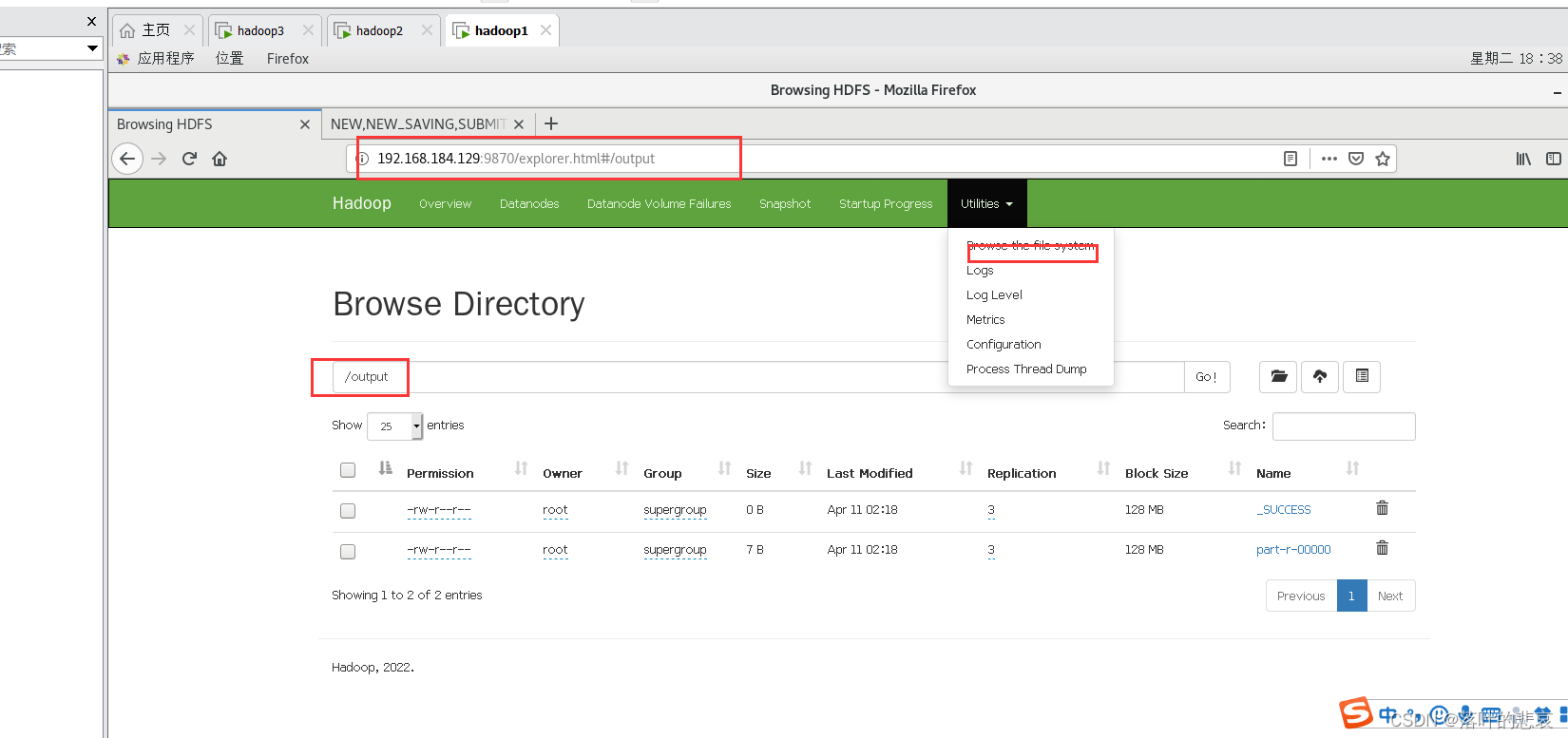
点开输出文件
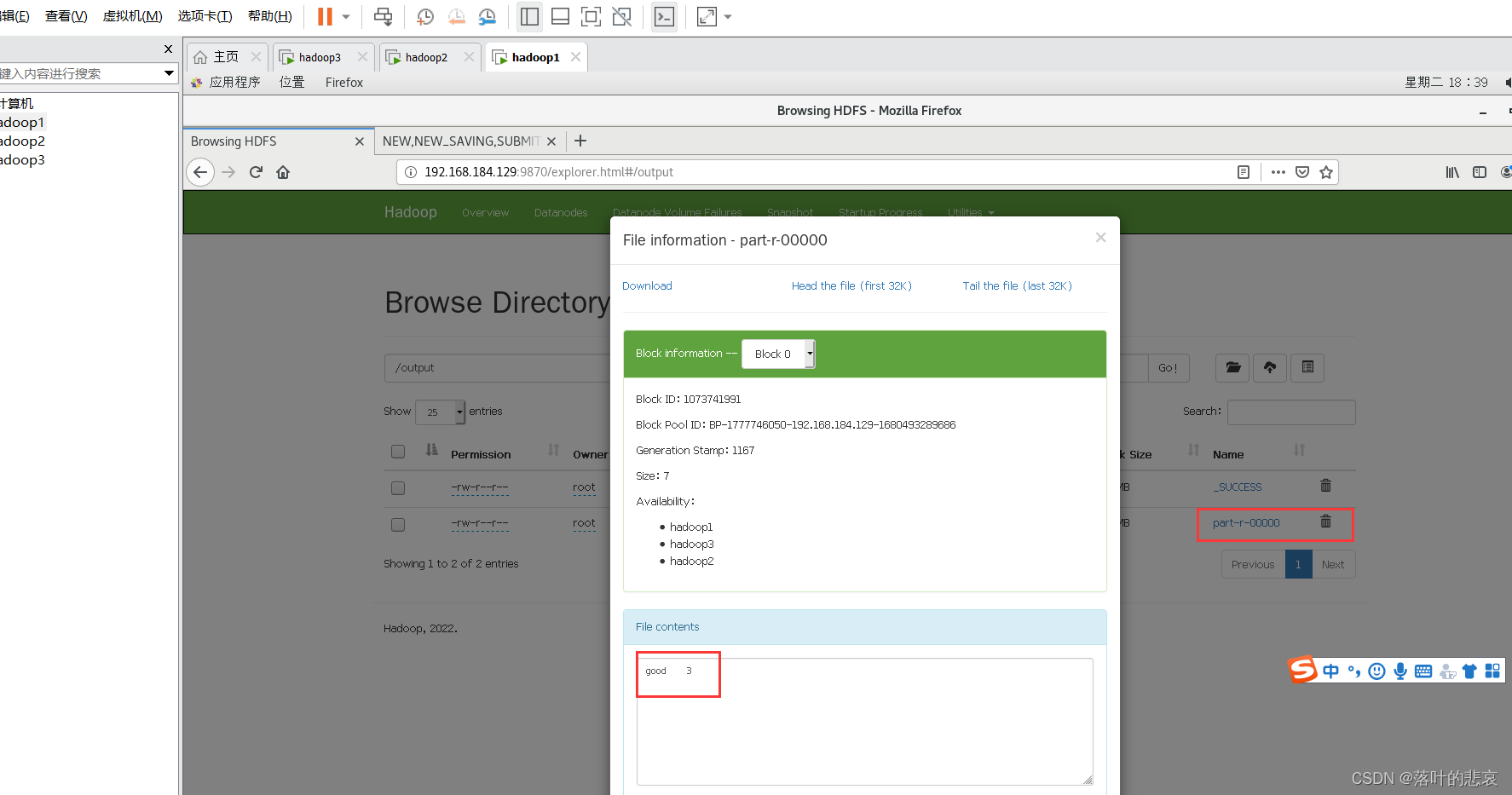
最后统计出good单词出现了三次,符合预期结果。
总结
这里展示了使用mapreduce进行统计单词数的案例,是大数据最简单的案例了,整个过程出现的问题也记录下来了,如果对你有帮助,点个赞吧。