还是那句话,看别人写的的总是觉得很累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦吗,还本地打Jar包,传到Linux上,最后在用jar命令运行jar包敲一遍in和out参数,我去,我是受不了了,谁让我是急性子呢, 。
。
我就想知道MapReduce的工作原理,而知道原理后,我就想在本地用Java程序跑一边整个MapReduce的计算过程,这个很难吗? 搜遍全网,没发现几个是自己想要的(也有可能漏掉了),都是可以参考的,但是零零散散很费时间,不适合入门级“玩家”像我一样的人,最后,下定决心,自己写个,从头到尾的捋一下MapReduce的原理,以及如何在本地,通过编写map和reduce函数对一个文本文件进行单词次数频率的统计,并将结果输出到HDFS文件系统上
效果:
1、 HelloWorld文件

2、上传至HDFS的intput目录下
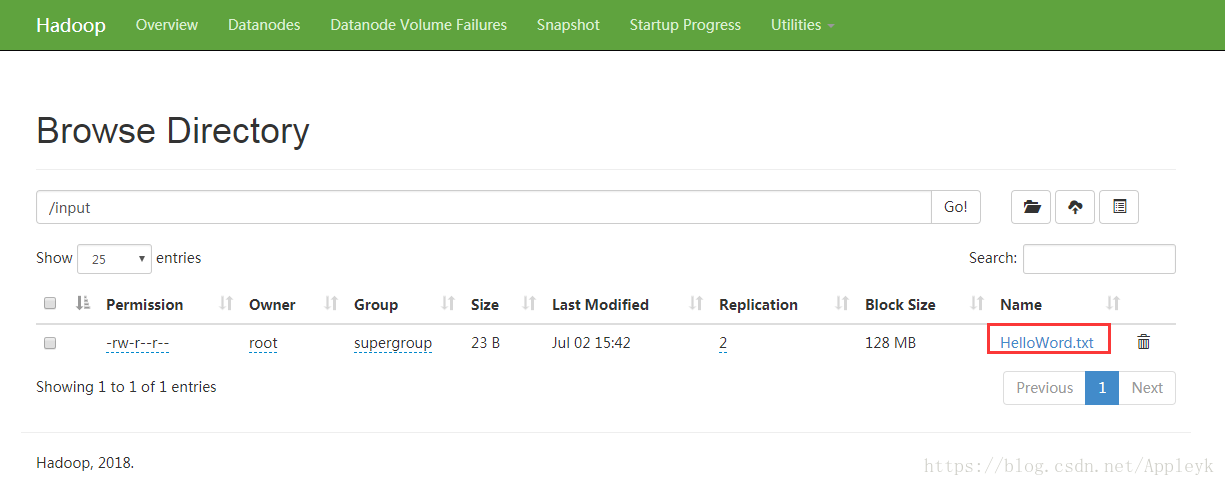
3、客户端提交Job,执行MapReduce
A、map的输出结果
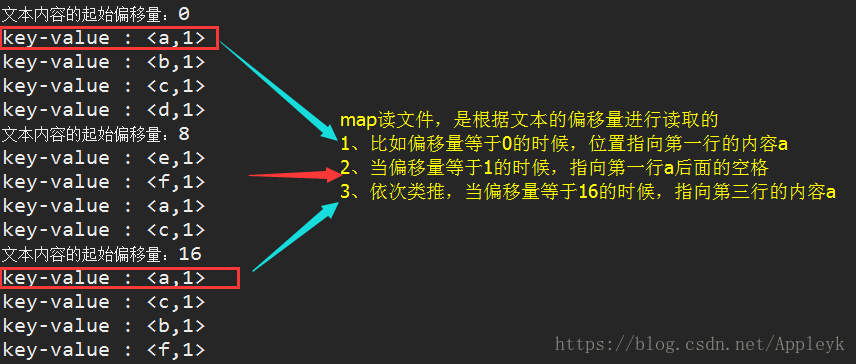
B、reduce的输入结果(上一步map的输出)

A、map输出结果