需求:现有数据格式如下,每一行数据之间都是使用逗号进行分割,求取每个单词出现的次数
hello,hello
world,world
hadoop,hadoop
hello,world
hello,flume
hadoop,hive
hive,kafka
flume,storm
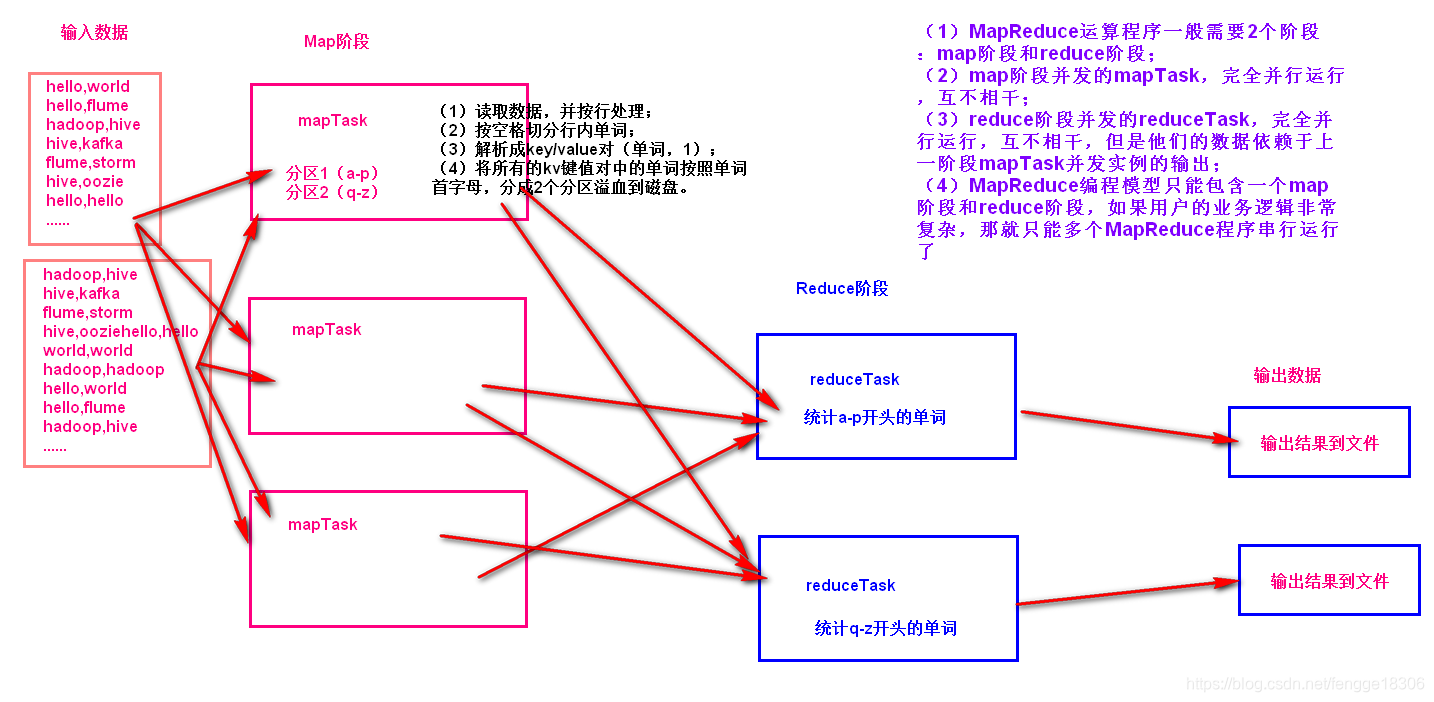
MapReduce编程思路(8个步骤)如图:

(1)创建maven工程并导入以下jar包
略
(2)自定义mapper类
/** * 自定义mapper类需要继承Mapper,有四个泛型, * keyin: k1 行偏移量 Long hadoop中为LongWritable * valuein: v1 一行文本内容 String hadoop中为Text * keyout: k2 每一个单词 String hadoop中为Text * valueout : v2 1 int hadoop中为IntWritable * 在hadoop当中没有沿用Java的一些基本类型,使用自己封装了一套基本类型 *(hadoop数据类型详见上一篇内容) */
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
/**
* 继承mapper之后,重写map方法,每次读取一行数据,都会来调用一下map方法
* @param key:对应k1
* @param value:对应v1
* @param context 上下文对象。承上启下,承接上面步骤发过来的数据,通过context将数据发送到下面的步骤里面去
* @throws IOException
* @throws InterruptedException
* k1 v1
* 0;hello,world
* k2 v2
* hello 1
* world 1
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();//获取一行数据
String[] split = line.split(",");//按“,”分割
Text text = new Text();
IntWritable intWritable = new IntWritable(1);
for (String word : split){
//将每个单词出现都记做1次
//key2 Text类型
//v2 IntWritable类型
text.set(word);
//将我们的key2 v2写出去到下游
context.write(text,intWritable);
}
}
}
(3)定义reducer类
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
//第三步:分区 相同key的数据发送到同一个reduce里面去,相同key合并,value形成一个集合
/**
* 继承Reducer类之后,覆写reduce方法
* @param key
* @param values 每个单词出现的次数都在这个迭代器里面
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values){
//将我们的结果进行累加
count +=value.get();
}
//继续输出我们的数据
IntWritable intWritable = new IntWritable(count);
//将我们的数据输出
context.write(key,intWritable);
}
}
(4)编写main方法
/*
这个类作为mr程序的入口类,这里面写main方法
*/
public class WordCountMain extends Configured implements Tool {
/**
* 实现Tool接口之后,需要实现一个run方法,
* 这个run方法用于组装我们的程序的逻辑,其实就是组装八个步骤
* @param args
* @return
* @throws Exception
*/
/**
* 第一步:读取文件,解析成key,value对,k1,v1
* 第二步:自定义map逻辑,接收k1,v1转换成新的k2 v2输出
* 第三步:分区,相同key的数据发送到同一个reduce里面去,key合并,value形成一个集合
* 第四步:排序,对key2进行排序,字典顺序排序
* 第五步:规约,combiner过程,调优步骤,可选
* 第六步:分组
* 第七步:自定义reduce逻辑,接收k2,v2转换成新的k3,v3输出
* 第八步:输出k3 v3进行保存
*/
@Override
public int run(String[] args) throws Exception {
//获取Job对象,组装我们的八个步骤,每一个步骤都是一个class类
//从父类中获取conf
Configuration conf = super.getConf();
//获取job对象
Job job = Job.getInstance(conf, "MapReduceDemo1");
//实际工作当中,程序运行完成之后一般都是打包到集群上面去运行,打成一个jar包
//如果要打包到集群上面去运行,必须添加以下设置
// job.setJarByClass(WordCountMain.class);
//第一步:读取文件,解析成key/value对,k1:行偏移量 v1:一行文本内容
job.setInputFormatClass(TextInputFormat.class);
//指定我们去哪一个路径读取文件
// //本地运行模式
TextInputFormat.addInputPath(job,new Path("file:///E:\\fengge\\MapReduce\\1、wordCount\\input"));
//第二步:自定义map逻辑,接收k1 v1,转换成k2,v2输出
job.setMapperClass(WordCountMapper.class);//将自定义mapper类放入job中
//设置map阶段输出的key,value的类型,其实就是k2,v2的类型
job.setMapOutputKeyClass(Text.class); //k2类型为Text
job.setMapOutputValueClass(IntWritable.class);//v2类型为IntWritable
//第三步到第六步:分区,排序,规约,分组省略
//第七步:将自定义的reducer逻辑
job.setReducerClass(WordCountReducer.class);
//设置key3 value3的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//第八步:输出k3 v3进行保存
job.setOutputFormatClass(TextOutputFormat.class);
//一定要注意,输出路径是不需要存在的,如果存在,就报错
//本地运行模式
TextOutputFormat.setOutputPath(job,new Path("file:///E:\\fengge\\MapReduce\\1、wordCount\\output"));
//提交job任务
boolean b = job.waitForCompletion(true);
return b ? 0:1;
}
//作为程序的入口类
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
//提交run方法后,得到一个程序的退出状态码
//WordCountMain实现了Tool接口,直接调用ToolRunner类中的run方法,
//run方法中三个参数run(Configuration conf, Tool tool, String[] args)
int run = ToolRunner.run(configuration, new WordCountMain(), args);
//根据我们程序的退出状态码,退出整个进程
System.exit(run);
}
}
(5)查看本地对应路径新生成的结果文件