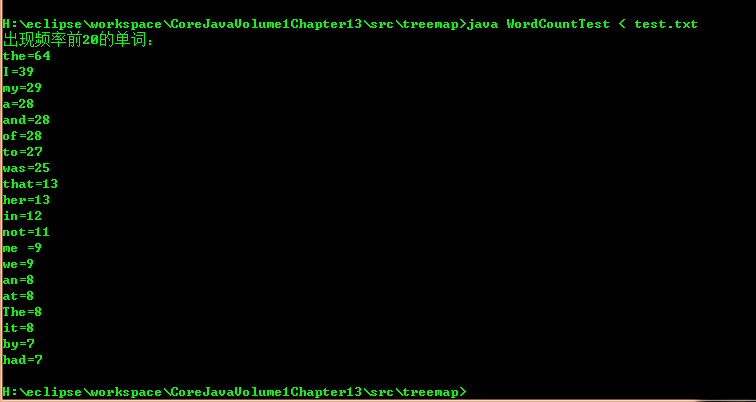
统计一篇文章中单词出现的次数,要存储单词和次数,根据次数排序输出,要用Map数据结构保存键值对。首先想到是用TreeMap<String, Integer>,它为有序映射表,但默认按照键Key排序,要让Map按照Value值排序,难以直接实现,所以用先存储再排序的方法。先用HashMap<String, Integer>存储单词和单词的次数,利用Map的entrySet()方法获取映射关系视图,再由此构建ArrayList<Map.Entry<String, Integer>>,最后用Collections.sort()方法,自定义一个比较Integer的comparator,对该ArrayList排序。
import java.util.*;
public class WordCountTest
{
public static void main(String[] args)
{
//读取
Map<String,Integer> map = new HashMap<>();
Scanner in = new Scanner(System.in);
while (in.hasNext())
{
String word = in.next();
word =word.replace(",", " ").replace(".", " ").replace("\"", " ").replace("“", " ").replace("”", " ").replace(";", " ");
if (!map.containsKey(word))
map.put(word, 1);
else
map.put(word, (map.get(word)+1));
}
//排序
List<Map.Entry<String, Integer>> arraylist = new ArrayList<Map.Entry<String, Integer>>(map.entrySet());
Collections.sort(arraylist,new Comparator<Map.Entry<String, Integer>>(){
public int compare(Map.Entry<String, Integer> obj1, Map.Entry<String, Integer> obj2)
{
return ((Integer) obj2.getValue()).compareTo((Integer) obj1.getValue());
}
});
// 输出次数前20的单词
List<Map.Entry<String, Integer>> list = arraylist.subList(0, 20);
System.out.println("出现频率前20的单词:");
for (Map.Entry<String, Integer> item : list)
System.out.println(item.getKey() + "=" + item.getValue());
}
}运行结果: