一、概述
Transfomer架构与传统CNN和RNN最大的区别在于其仅依赖自注意力机制,而没有卷积/循环操作。其相较于RNN,不需要进行时序运算,可以更好的进行并行;相较于CNN,其一次可以关注全图而不局限于感受野尺寸。
二、模型架构
1.功能模块
功能模块结构如下图所示:

Inputs:编码器输入
Outputs:解码器输入(解码器之前时刻的输出作为输入)
Positional Encoding:
Transformer Block(编码器):由一个具有残差连接的多头注意力层和一个具有残差连接的前向传递网络组成。编码器的输出会作为解码器的输入。

Transformer Block(解码器):相较于编码器多了一个Masked Multi-Head Attention(掩码多头注意力)机制。

2.网络结构
①编码器
堆叠了6个Transfomer Block,每个Block中有两个Sublyaer(子层)(Multi-head self-attention mechanism(多头自注意力机制)+MLP(多层感知机)),最后经过一个Layer Normalization。
其采用公式可表达为:<具备残差连接>
Layer Norm类似于Batch Nrom,均为求均值的算法,不同点在于Batch Nrom是求一个batch内(列)的均值,而Layer Norm是求一个样本(行)内的均值。
②解码器
堆叠了6个Transfomer Block,每个Block中有三个Sublyaer(子层),解码器内会做一个自回归(当前时刻的输入是上一个时间的输出)。而为了保证 t 时刻不会看到之后的输出,在第一个多头注意力块中增加了一个掩码机制进行屏蔽。
③注意力机制
注意力函数(将query和一些key-value对映射成一个输出的函数,每个value的权重是其对应的key和查询的query的相似度得来的)
其公式可以写为:
query和key的长度均等于,value的长度等于
;将每组query和key进行内积作为相似度(值越大,相似度越高--cos函数);得出结果后再除以
(即向量长度);最后以一个softmax得到权重。
得出权重后与vuale进行乘积即可得到输出。
实际运算时,query和key均可写作矩阵,采用下图所示方法计算。

掩码机制: 对于时间 k 的输入而言,在计算时应该只看
至
时刻的值,但实际上注意力计算时
会和所有 k 进行运算。固引入掩码机制,具体做法为:将
及其之后计算的值替换为一个很大的负数,在经过softmax后就会变为0。
多头机制:将整个query、key、value投影到低维(h次,原文的h=8),再做h次注意力函数;将每个函数的输出并在一起,再投影回高维度得到结果。如下图所示:
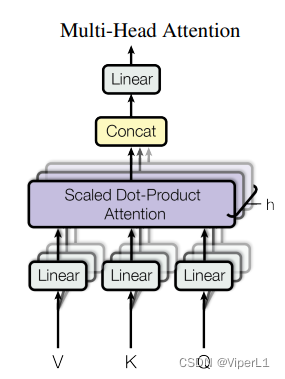
图中的Linear用于低维投影;Scaled Dot-Product Attention为注意力机制。concat负责将结果合并。
其公式为:
where
三、VIT(Vision Transformer)
将Transformer应用在图像处理上还有一个难点:如果直接将图像的像素点作为输入序列的话会面对输入序列过长的问题。而VIT网络采用将图像划分成小patch的方式来解决这个问题。
VIT将尺寸为16x16划为一个patch,以224x224的标准图像输入为例,在patch后就变为了196个patch,大大降低了输入序列的尺寸。

1.模型结构
首先,将图片划分为多个patch;将这些patch放入线性投射层(Linear Projection of Flattened Patches--即一个全连接层),之后为每个patch加一个位置编码信息(为了防止图片顺序颠倒)合并为一个token(直接相加而不是合并)。随后将这个token送入transformer的编码器中。同时,token的头部需要放入cls token(分类信息) 以标明所属类别;自注意力机制最后的输出的cls即为分类信息。

2.Transformer Encoder
