本篇博客要介绍的是图注意力网络(Graph Attention Networks,GAT),它通过注意力机制(Attention Mechanism)来对邻居节点做聚合操作,实现对不同邻居权重的自适应分配(GCN中不同邻居的权重是固定的,来自归一化的拉普拉斯矩阵),从而大大提高了图神经网络模型的表达能力。论文下载(提取码:68e6)
注意力机制
DNN中的注意力机制是受到认知科学中人类对信息处理机制的启发而产生的。由于信息处理能力的局限,人类会选择性地关注完整信息中的某一部分,同时忽略其他信息。例如,我们在看一幅画时,通常会把视觉关注焦点放到语义信息更丰富的前景物体上,而减少对背景信息的关注,这种机制大大提高了人类对信息的处理效率。
如下图所示,我们的视觉会更加关注画面上的猫,这种对视觉信息集中处理的机制在视觉问答场景中被发挥得淋漓尽致。 比如,如果要确定上图中的猫在做什么,人类会把视觉信息快速集中在猫的前爪以及面部上,而忽略对其他视觉信息的辨职,从而准确得出图中的猫在睡觉的答案。

可见,注意力机制的核心在于对给定信息进行权重分配,权重高的信息意味着需要系统进行重点加工。 下面来进一步阐述神经网络中注意力机制的数学表达形式(如下图所示):

如上图所示,Source是需要系统处理的信息源,Query代表某种条件或者先验
信息,Attention Value 是给定 Query信息的条件下,通过注意力机制从Source中提取得到的信息。一般Source里面包含有多种信息,我们将每种信息通过Key-Value对的形式表示出来,注意力机制的定义如下:
上式中的 Query,Key,Value,Attention Value在实际计算时均可以是向量形式。 表示Query 向量和Key向量的相关度,最直接/简单的方法是可以取两向量(向量维度相同)的内积 (用内积去表示两个向量的相关度是DNN里面经常用到的方法,对于两个单位向量(两个单位向量的内积就是余弦相似度[-1,1]),如果内积接近1,代表两向量接近重合,相似度就高),上式清晰地表明,注意力机制就是对所有的Value信息进行加权求和,权重是Query与对应Key的相关度。
我们可以继续通过上述视觉问答的例子来说明注意力机制是怎样运用的。
首先,显然Query 应该是代表问题句子“小猫在做什么?”的语义向量表达,一
般我们用LSTM模型进行提取。H表示整张图像在经过CNN模型后得到的特征图张量
,
分别代表特征图的高度、 宽度和通道数。 通过前面所学的知识我们知道,人类的视觉系统分配给图里不同位置的信息的注意力是不同的。所以很自然地,我们将特征图H转化成
,其中
表示空间位置的长度,
表示特征图上某个空间位置的向量表达。 在这个例子中,由于没有明显的 Key,Value之别,所以我们令
,则在给定Query问题的条件下,注意力机制下的输出为:
通过上述例子,我们可以很清晰地看到DNN 是如何利用注意力机制在视觉问答的任务中从图里更加有效地抽取出内容信息的。事实上在DNN中,注意力机制已经被看作一种更具表达力的信息融合手段,其在计算机视觉与自然语言处理中得到了广泛的应用,如在视觉问答,、视觉推理,语言模型,机器翻译、 机器问答等场景中,注意力机制得到了长足的应用与发展。
图注意力层
接下来介绍如何将注意力机制应用到图神经网络聚合邻居的操作中,根据注意力机制里面的三要素:Query,Source,Attention Value,我们可以很自然地将Query设置为当前中心节点的特征向量,将Source设置为其所有邻居的特征向量,将Attention Value 设置为中心节点经过聚合操作后的新的特征向量。
正式的定义如下:设图中任意节点 ,在第l层所对应的特征向量为 , , 表示第l层节点特征向量的长度,经过一个以注意力机制为核心的聚合操作之后,输出的是每个节点新的特征向量 ; , 是输出的特征向量的长度(第l+1层节点特征向量的长度)。 我们将这个聚合操作称为图注意力层(Graph Attention Layer,GAL)(如下图所示).

假设当前中心节点为
(每个节点都可以作为中心节点,实际代码中使用矩阵运算,实现对各个节点并行计算),我们设其中一个邻居节点
到
的权重系数为:
是该层节点特征变换(维度变换)的权重参数。
是计算两个节点(特征向量)相关度的函数。原则上,这里我们可以计算图中任意一个节点到节点
的权重系数,但是为了简化计算,我们将其限制在一阶邻居内(有直接的边相连),需要注意的是在GAT中,作者将每个节点自身也视作自己的邻居。关于函数a的选择,前面我们介绍了可以用向量的内枳来定义一种无参形式的相关度计算
,也可以定义成一种带参的神经网络层,只要满足
,即输出一个标量值表示二者的相关度即可。此处作者选择了一个单层的全连接层:
其中||代表拼接操作,其中权重参数
(注意这里的a是一个权重向量/模型参数,之前的a表示函数),激活函数使用Leaky ReLU。为了更好地分配权重,我们需要将当前中心节点与其所有邻居计算出的相关度进行统一的归一化处理,具体形式为 softmax归一化:
是权重系数,通过上式的处理,保证了当前中心节点所有邻居的权重系数加和为1。下式给出了完整的权重系数的计算公式:
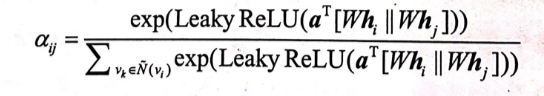
一旦完成上述权重系数的计算,按照注意力机制加权求和的思路,节点
新的特征向量为:
实际上,第l层各个节点的特征向量是同维的,最简单的操作是直接计算内积(在用softmax归一化),至于W是用来做维度变换的(将节点特征向量维度从第l层的 维变为第l+1层的 ),也有可能会增加模型的非线性和表达能力。如果不需要改变节点特征向量的维度,也可以不使用W参数(也就是上述运算中的W和a可以不需要),或者W参数是一个方阵。总之,在实际使用中图注意力机制非常灵活,一定要灵活使用。
多头图注意力层
为了更进一步提升注意力层的表达能力,可以加入多头注意力机制(multi-head attention),也即对上式调用K组相互独立的注意力机制,然后将输出结果拼接在一起:
其中||表示拼接操作,
是第k组注意力机制计算出的权重系数,
是(第k组注意力机制)对应的学习参数。当然为了减少输出的特征向量的维度,也可以将拼接操作替换成平均操作。)
增加多组相互独立的注意力机制,使得多头注意力机制能够将注意力的分配放到中心节点与邻居节点之间多处相关的特征上,可使得系统的学习能力更加强大。多头注意力机制的计算流程如下图所示,其中不同的颜色表示不同注意力头的计算过程,图中K=3,计算完后,将上述结果进行拼接或者平均操作。

GAT和GCN的比较
图注意力层比GCN里面的图卷积层多了一个自适应的边权重系数(模型参数)的维度。 回到GCN 的核心过程 ,我们可以将 分拆成两个部分,引人一个权重矩阵 ,然后核心过程就变成了 .由此可以看到,图注意力模型相较于GCN多了一个可以学习的新的维度,即边上的权重系数。 在之前的模型中,这个权重系数矩阵是图的拉普拉斯矩阵,而图注意力模型可以对其进行自适应的学习,并且通过运用注意力机制,避免引入过多的学习参数。这使得图注意力模型具有非常高效的表达能力。 这种机制从图信号处理的角度来看,相当于学习出一个自适应的图位移算子,对应一种自适应的滤波效应。当然,和GraphSAGE模型一样,图注意力模型的计算也保留了非常完整的局部性,一样能进行归纳学习。
