转自:http://blog.csdn.net/wangyangzhizhou/article/details/77332582
前面已经详细讲了LSTM神经网络(文末有链接回去),接着往下讲讲LSTM的一个很流行的变体。
GRU是什么
GRU即Gated Recurrent Unit。前面说到为了克服RNN无法很好处理远距离依赖而提出了LSTM,而GRU则是LSTM的一个变体,当然LSTM还有有很多其他的变体。GRU保持了LSTM的效果同时又使结构更加简单,所以它也非常流行。
GRU模型
回顾一下LSTM的模型,LSTM的重复网络模块的结构很复杂,它实现了三个门计算,即遗忘门、输入门和输出门。
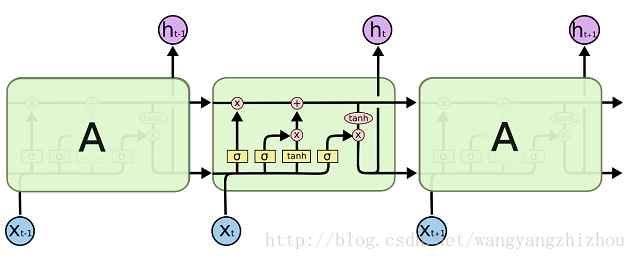
而GRU模型如下,它只有两个门了,分别为更新门和重置门,即图中的
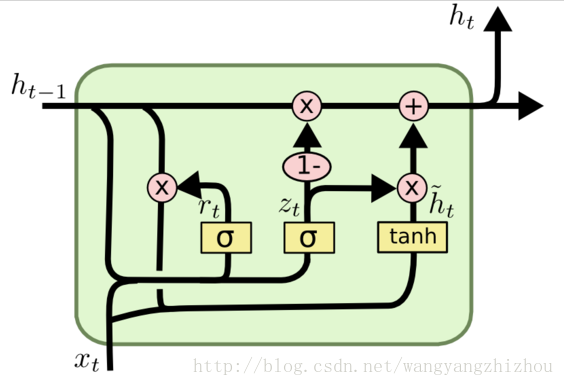
GRU向前传播
根据前面GRU模型图来一步步看他是怎么向前传播的,根据图不难得到以下式子:
其中[]表示两个向量相连接,*表示矩阵元素相乘。
GRU的训练
从前面的公式中可以看到需要学习的参数就是
输出层的输入
设某时刻的损失函数为
与前面LSTM网络类似,最终可以推出
以下是广告和相关阅读
========广告时间========
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
=========================
相关阅读:
欢迎关注:
