这是我去年自学神经网络的笔记,笔记本身是以jupyter的格式,我也会直接把jupyter文件放到这里,实测pytorch1.7可直接run all运行。该笔记主要介绍了一些神经网络的小tip,当时是跟着b站的一个up主学习的,但我对他的ppt内容作了许多的手绘添加以便于理解。
jupyter文件如下:
链接:https://pan.baidu.com/s/1sfaekKI-T18f9_STKzGlog
提取码:4dno
复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V4的分享
以下内容便是jupyter上导出来的,暂时没有区分代码和打印的内容,大家复制代码的时候记得看一眼,以后有空的话我会删去打印的内容。
import torch
import torch.nn as nn
import torch.nn.functional as f
def describe(x):
print("Type:{}".format(x.type()))
print("Shape/size:{}".format(x.shape))
print("Values:\n{}".format(x))
pytorch神经网络
在深度学习中实现训练一个神经网络,一定会包含的有神经元(perceptron)、损失函数(loss)、优化器(optimizer).
其中神经元里面包含有激活函数和线性函数(并不是标量上的线性),神经元输入的是能够量化表示的原始数据,输出的是预测的值。
损失函数输入经过神经元处理后的值与实际的值,用于量化神经元处理能力的好坏。
优化器里面包含梯度下降算法,用于告诉神经元改向哪个方向升级优化参数权重。
另外我们的模型参数是未知的,是通过梯度下降来找到的,像我们已知的学习率就是控制寻找模型参数的固定参数,也被称为超参数
感知器(神经元)
# pytorch 实现简单感知器,感知器=模型=神经元,神经网络的基本单位
class Perceptron(nn.Module): # 继承父类nn.Module类的方法
def __init__(self):
super(Perceptron, self).__init__() # 继承父类nn.Module类的init方法
self.fc1 = nn.Linear(2, 1) #一个线性层,即y=w@x+b ;[input_dim=2, output_dim=1]为(输入维度为2,输出维度为1)
def forward(self, x):
return self.fc1(x) # 即输出 out = w@x+b w和x都是矩阵,b看输出维度,@代表矩阵相乘的符号
x = torch.ones(2, 2) # 创建了一个随机的形状为[batch_size=2, input_dim=2]的tensor对象,这里的输入维度与上面设定好的输入维度要一致,都是2
x[0,1] = 2
net = Perceptron() # 实例化一个神经元对象
describe(x)
out = net(x)
print(list(net.parameters())) # 提取参数w和b并打印
describe(out) # 经过神经元处理后形状变为[batch_size=2, output_dim=1]也是根据你设定好的模型而改变
# 我们可以看到输出的确是 y = w^ * x^ + b
Type:torch.FloatTensor
Shape/size:torch.Size([2, 2])
Values:
tensor([[1., 2.],
[1., 1.]])
[Parameter containing:
tensor([[-0.5137, -0.6810]], requires_grad=True), Parameter containing:
tensor([0.2509], requires_grad=True)]
Type:torch.FloatTensor
Shape/size:torch.Size([2, 1])
Values:
tensor([[-1.6248],
[-0.9438]], grad_fn=)
'''
Type:torch.FloatTensor
Shape/size:torch.Size([2, 2])
Values:
tensor([[1., 2.], <--- 输入的张量
[1., 1.]])
[Parameter containing:
tensor([[-0.0791, 0.1809]], requires_grad=True), Parameter containing: <--- w的张量
tensor([0.5969], requires_grad=True)] <--- b的张量
Type:torch.FloatTensor
Shape/size:torch.Size([2, 1])
Values:
tensor([[0.8797], <--- 输出的张量
[0.6988]], grad_fn=<AddmmBackward>)
'''
# 因为这个权重还未启动更新,一开始是随机的,所以每次看到的都不一样
# 可以看见 1 * -0.0791 + 2 * 0.1809 + 0.5969 =0.8797 符合矩阵的运算 输出的张量矩阵 = 输入的张量矩阵 @ w的张量矩阵的转置 + b的张量矩阵
# 可以看见 1 * -0.0791 + 1 * 0.1809 + 0.5969 =0.6988
'''
鉴于大家可能未学过线性代数,所以我简单讲一下矩阵是如何相乘的
[a11, a12] [b11, b12] [a11*b11+a12*b21, a11*b12+a12*b22]
[a21, a22] @ [b21, b22] = [a21*b11+a22*b21, a21*b12+a22*b22]
总的来说就是结果的第n行第m列等于第一个矩阵的第n行乘第二个矩阵的第m列的各个元素的相加
[a]
[b]
[c]的转置就是[a b c],符号用T表示
'''
激活函数
import matplotlib.pyplot as plt
# sigmoid 将任意实数输入并将其压缩到0~1之间的范围。
x = torch.range(-5., 5., 0.1)# 这里torch.range()的用法与numpy.range()相似
y = torch.sigmoid(x) # 使用激活函数sigmoid()
plt.plot(x.numpy(), y.numpy()) #由于x,y本身是tensor对象,无法输入给plt,所以用x.numpu(),y.numpy()转成ndarray对象
plt.grid()
plt.show()

# tanh 被认为是sigmiod函数的线性变换。
x = torch.range(-5., 5., 0.1)
y = torch.tanh(x)
plt.plot(x.numpy(), y.numpy())
plt.grid()
plt.show()

# ReLU 整流线性单元,可以说是最重要的激活函数。将负值映射为零
relu = torch.nn.ReLU()
x = torch.range(-5., 5., 0.1)
y = relu(x)
plt.plot(x.numpy(), y.numpy())
plt.grid()
plt.show()

# PReLU 为负值制造一个较小的梯度
prelu = torch.nn.PReLU(num_parameters=1)
x = torch.range(-5., 5., 0.1)
y = prelu(x)
plt.plot(x.detach().numpy(), y.detach().numpy()) # 你可以试一试删除detach(),解答如下
plt.grid()
plt.show()
# 待转换类型的PyTorch Tensor变量带有梯度,直接将其转换为numpy数据将破坏计算图,因此numpy拒绝进行数据转换,实际上这是对开发者的一种提醒。如果自己在转换数据时不需要保留梯度信息,可以在变量转换之前添加detach()调用。

# softmax 与sigmoid函数一样将输入压缩为0~1之间的实数。然而,softmax函数将每个输出初一所有输出的和,从而得到一个离散的概率分布
softmax = nn.Softmax(dim=1) # 以1号维度为单位转换数据,使得1号维度的值加起来和为1
#x_input = torch.range(-5., 5., 0.1) # 你可以试一试输入只有一个维度的张量
x_input = torch.randn(1, 3, 3)
y_output = softmax(x_input)
print(x_input)
print(y_output)
print(torch.sum(y_output, dim=1))# 将1号维度的值加起来的和为1,因为总概率为1
tensor([[[ 2.3962, -0.7151, 0.2456], [-0.8917, -0.5710, -0.6426], [ 0.6902, -0.7357, 2.2567]]]) tensor([[[0.8204, 0.3190, 0.1126], [0.0306, 0.3685, 0.0463], [0.1490, 0.3125, 0.8411]]]) tensor([[1., 1., 1.]])
损失函数
# MSE 均误差损失 也就是平方差公式
mse_loss = nn.MSELoss()
x = torch.randn(1, 5)
w = torch.randn(1, 5, requires_grad=True)# 对于某变量 w ,其 w.requires_grad == True , 则表示它可以参与求导,也可以从它向后求导
out = torch.sigmoid(x@w.t())# 模拟一个偏置为0的线性层带激活函数。w.t()方法意思是w的转置矩阵
print(out)
targets = torch.ones(1,1)
loss = mse_loss(out, targets)
print(loss)
tensor([[0.2034]], grad_fn=< SigmoidBackward >)
tensor(0.6346, grad_fn=< MseLossBackward >)
# 使用loss.backward()查看权重w的求导
loss.backward()
print(w.grad)
tensor([[ 0.1867, -0.3023, 0.1952, 0.2942, -0.0383]])
# 交叉熵损失 也就是底数为2的对数log运算
ce_loss = nn.CrossEntropyLoss()
outputs = torch.randn(3, 5, requires_grad=True)
targets = torch.tensor([1, 0, 3], dtype=torch.int64)
loss = ce_loss(outputs, targets)
print(loss)
tensor(1.6274, grad_fn=< NllLossBackward >)
# 二分交叉熵损失 标签答案只有0和1 是或不是
bce_loss = nn.BCELoss()
sigmoid = nn.Sigmoid()
probabilities = sigmoid(torch.randn(4, 1, requires_grad=True)) # requires_grad=True将张量设置成自动求导
targets = torch.tensor([1, 0, 1, 0], dtype=torch.float32).view(4, 1) # view(4,1)将张量一行四列重新排列为四行一列,总的大小不变
loss = bce_loss(probabilities, targets)
print(probabilities)
print(loss)
tensor([[0.1444],
[0.8369],
[0.0998],
[0.1994]], grad_fn=< SigmoidBackward >)
tensor(1.5690, grad_fn=< BinaryCrossEntropyBackward >)
优化器
import torch.optim as opt
# 创建一个优化器实例
lr = 0.001 # 学习率
perceptron = Perceptron()# 实例化感知器
bce_loss = nn.BCELoss()
# SGD优化器,随机梯度下降(SGD)是一种经典的算法,但对于复杂的优化问题存在收敛性的问题
#optimizer = opt.SGD(params=perceptron.parameters(), lr=lr)# 将权重偏差参数与学习率输入进优化其中
# adam优化器,自适应优化算法,使用关于随时间更新的信息
optimizer = opt.Adam(params=perceptron.parameters(), lr=lr)# 将权重偏差参数与学习率输入进优化其中
# 我们的神经元Perceptron()简单而言长这样子out = sigmoid(w@x+b),那么perceptron.parameters()这个方法获取的就是[w, b]
监督学习基本步骤(简单构建网络)
监督学习指提供了目标(也就是标签)的深度学习
# 一种用于感知器和二分类的监督训练循环的步骤
# 第一步:确定各超参数
num = 4 # 训练集总数
batch_size = 4 # 每个训练批次的个数
lr = 0.01 # 学习率
epochs = 100 # 训练次数
batches = int(num/batch_size) # 每个训练批次含有个数4,总数为4,所以每次训练只训练1个训练批次
# 第二步:量化数据和标签并读取,我这里为仿造
x = torch.randn(batch_size, 6, requires_grad=True) # 这里仿造了一个批次的四个数据,每个批次的数据形状为[batch_size, input_dim]
target = torch.tensor([1, 0, 1, 0], dtype=torch.float32).view(4, 1)
# 这里仿造了四个(对应每批次四个)二分类标签,一个数据一个标签,形状为[batch_size, output_dim]
# 比如问四个数据是不是表示人?那么这个标签就是回答第一个是人,第二个不是,第三个是人,第四个不是
# 第三步:自定义网络结构
class Perceptron(nn.Module):
def __init__(self):
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(6, 1) # 注意这个2与上面的数据形状对应,我们也可根据数据的形状直接传递变量到这里,形状为[input_dim, output_dim]
def forward(self, x):
return torch.sigmoid(self.fc1(x))
# 第四步:实例化各组件
net = Perceptron()
bce_loss = nn.BCELoss()
optimizer = opt.Adam(params=net.parameters(), lr=lr)
# 第五步:训练 带入模型计算loss并启动优化器
for epoch_i in range(epochs):
for batch_i in range(batches):
# 获取数据
x_data = x
y_target = target
# 清空梯度
net.zero_grad()
# 计算模型的前向传播,获取预测值
y_pred = net(x_data)
# 计算损失函数
loss = bce_loss(y_pred, y_target)
# 反向传递损失函数的值
loss.backward()
# 触发器执行一次更新
optimizer.step()
if epoch_i%10 == 0: # 每训练十次打印一次
print('epoch:{} loss:{}'.format(epoch_i, loss.item())) # 可以看到损失函数有在下降
# 第六步:拿训练好的模型验证测试
# 理论上除了训练集以外,还会有测试集和验证集,这里就全部拿训练集的数据来验证
text_1 = net(x[0,:]) # 拿0号行的数据来验证,上面的标签写明他是1
text_2 = net(x[1,:]) # 拿1号行的数据来验证,上面的标签写明他是0
print(text_1) # 打印结果的确靠近1,这里直接用看来验证,实际并不是这样
print(text_2) # 打印结果的确靠近0
# 第七步:保存模型等等......
epoch:0 loss:0.6327000856399536
epoch:10 loss:0.5508567094802856
epoch:20 loss:0.49135684967041016
epoch:30 loss:0.4451417922973633
epoch:40 loss:0.40553781390190125
epoch:50 loss:0.3711619973182678
epoch:60 loss:0.3410440683364868
epoch:70 loss:0.3142414391040802
epoch:80 loss:0.2901421785354614
epoch:90 loss:0.2683735191822052
tensor([0.8738], grad_fn=< SigmoidBackward>)
tensor([0.1295], grad_fn=< SigmoidBackward>)
将模型转移到GPU部署
device = torch.device('cuda')
net = Perceptron()
net.to(device)
Perceptron(
(fc1): Linear(in_features=6, out_features=1, bias=True)
)
保存或加载 save and load
# 以防断电等不可测情况,每训练多少次便保存一次模型
torch.save(net.state_dict(), 'ckpt.mdl')
net.load_state_dict(torch.load('ckpt.mdl'))
< All keys matched successfully>
切换train/test状态
# 切换至train, 对于dropout和batch norm(下面有讲),train和test的模型状态是不一样的,手动调整太麻烦,pytorch提供了这两个开关。
net.train()
#......
# test
net.eval()# pytorch会自动把BN和DropOut固定住,不会取平均,而是用训练好的值。
#......
# 你可以先去下面看完dropout和batch norm再反上来理解这个的实际意义
Perceptron(
(fc1): Linear(in_features=6, out_features=1, bias=True)
)
计算图
对于一个简单的y=x*w+b,构建一个计算图(数据流动架构)。tensorflow的取名就是这么来的,所以你也可以看出张量的流动是深度学习的核心,最应关注的点。
感知器中__init__()函数定义了每一层中具体的计算步骤。其中数学运算便是节点,例如乘法和加法。操作的输入是节点的输入边缘,每个操作的输出是输出边缘。
forward()函数则是定义数据流动的前进方向,张量只能向前一步一步运算得出最后的输出,被叫做正向/前向传播。
在训练中会实现参数梯度的自动微分用__backward__()函数来调用,更新梯度会是从最后一个权重开始计算一步一步反推之前的梯度,被称为反向传播。
你可以理解为你每次的写类、实例化类其实是在构建计算图。而真正获取答案需要一个启动键,使数据在图中流动起来。就像先写公式再求答案,而不是答案直接套公式得出。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E0zvI5vl-1613897890654)(attachment:2a66a0beb88e26219f63eb45eafa4d5.jpg)]](https://img-blog.csdnimg.cn/20210221170529322.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80NTU2OTYxNw==,size_16,color_FFFFFF,t_70)
正则化regularization
正则化是防止模型过拟合的一种手段,下图红色情况便是过拟合的模型。
根据泰勒公式,一个函数的阶数越高,他的曲线越不平整;阶数越低曲线越顺滑。所以规范化就是把高次方变量的权重降低,使得过拟合的模型越来越顺滑。
常见的有L1 正则化(pytorch的优化器没有L1的参数集成)和L2 正则化
optimizer = opt.Adam(params=net.parameters(), lr=lr, weight_decay=0.01) # 设置weight_decay参数即可实现L2正则化,weight_decay意为权重衰减

动量Momentum
optimizer = opt.SGD(params=net.parameters(), lr=lr, weight_decay=0.01,momentum=0.78) # 设置momentum参数即可实现,Adam优化器没有这个参数

学习率衰减
# 学习率在社团推送里已经讲得很明白了,这里不讲原理,提供一种学习率衰减的pytorch实现方法
lr_list = []
net = Perceptron()
LR = 0.01
optimizer = opt.Adam(net.parameters(),lr = LR)
scheduler = opt.lr_scheduler.StepLR(optimizer,step_size=5,gamma = 0.8) # 每5步,学习率乘以0.8
for epoch in range(100):
scheduler.step()
lr_list.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(100),lr_list,color = 'r')
D:\dev\anaconda\envs\torch38\lib\site-packages\torch\optim\lr_scheduler.py:118:
UserWarning: Detected call oflr_scheduler.step()before
optimizer.step(). In PyTorch 1.1.0 and later, you should call them
in the opposite order:optimizer.step()before
lr_scheduler.step(). Failure to do this will result in PyTorch
skipping the first value of the learning rate schedule. See more
details at
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
warnings.warn("Detected call oflr_scheduler.step()beforeoptimizer.step(). "[<matplotlib.lines.Line2D at 0x1cd88d491f0>]

多层感知器MLP
层数越深,学习的也就越深入,深度学习因此而来。线性层一般都用作模型网络输出的全连接层。
# 创建一个多层感知器的类
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
'''
input_dim(int):输入size
hidden_dim(int):第一个线性层输出的size
output_dim(int):第二个线性层输出的size
这里是两层,且层的维度数由外面来给定
__init__()为设定好的模型函数
'''
super().__init__()# python3.x的继承父类缩略写法
self.fc1 = nn.Linear(input_dim, hidden_dim)# 设 y1 = w1@x+b1 这是第一层线性层
self.fc2 = nn.Linear(hidden_dim, output_dim)# 设 y2 = w2@x+b2 这是第二层线性层,一层以上即为多层感知器
def forward(self, x, apply_softmax=False):
'''
x_in:输入的tensor数据。x_in.shape == (batch,input_dim)
apply_softmax:softmax函数的激活标志
此函数最终返回一个处理后的tensor。tensor.shape == (batch, output_dim)
forward()这里才是具体的模型算术操作
'''
intermediate = f.relu(self.fc1(x)) # intermediate = relu(w1@x+b1)
output = self.fc2(intermediate) # output = w2@intermediate+b2
if apply_softmax:# 是否激活softmax,转为概率运算
output = f.softmax(output, dim=1)# output = softamx(output)
return output
# 也就是说这个MLP的模型公式为:y = w2@relu(w1@x+b1) + b2 或者是 y = softmax(w2@relu(w1@x+b1) + b2)
# 而他的参数perceptron.parameters()为:[w1, b1, w2, b2]
# 模型应输入的张量形状:[batch_size, input_dim]
# 模型输出的张量形状:[batch_size, output_dim]
# 实例化多层感知器
batch_size = 2
input_dim = 3
hidden_dim = 100
output_dim = 4
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
# 随机输入测试MLP
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
# 使用多层感知器产生概率输出(softmax)
y_output = mlp(x_input, apply_softmax=True)
describe(y_output)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 3])
Values:
tensor([[0.5448, 0.4999, 0.6706],
[0.7208, 0.3210, 0.3161]])
Type:torch.FloatTensor
Shape/size:torch.Size([2, 4])
Values:
tensor([[ 0.1771, 0.1004, 0.2207, -0.0866],
[ 0.1332, 0.0881, 0.2139, -0.0106]], grad_fn=< AddmmBackward>)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 4])
Values:
tensor([[0.2675, 0.2477, 0.2794, 0.2055],
[0.2560, 0.2447, 0.2775, 0.2217]], grad_fn=< SoftmaxBackward>)
带有正则化dropout的MLP
模型对数据的过度拟合
假设我们要识别车,但我们的训练集全部都是奥迪车。过拟合的意思就是很可能我们的模型经过这个训练以后只认识奥迪车或者只认识训练集上的奥迪车。
前者避免模型只认识奥迪车就是丰富训练集,把其他的车都放进去。后者的解决过拟合的方法比较好的便是正则化dropout。
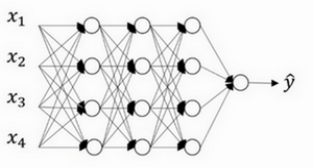
dropout通过概率性地断开单元之间地连接,超参数为probability缩写为p,也就是断开概率的大小。
请看下图,一个圆代表一个节点。经过节点完成加乘运算操作。
输入的张量是[[1, 2],[1, 1]],那这个输入数据的形状就是[batch_size=2, input_dim=2]
假设我们第一层的w权重是[[1, 2],[3, 4]],形状是[input_dim=2,out_dim=2],并且这个线性层不带激活函数。
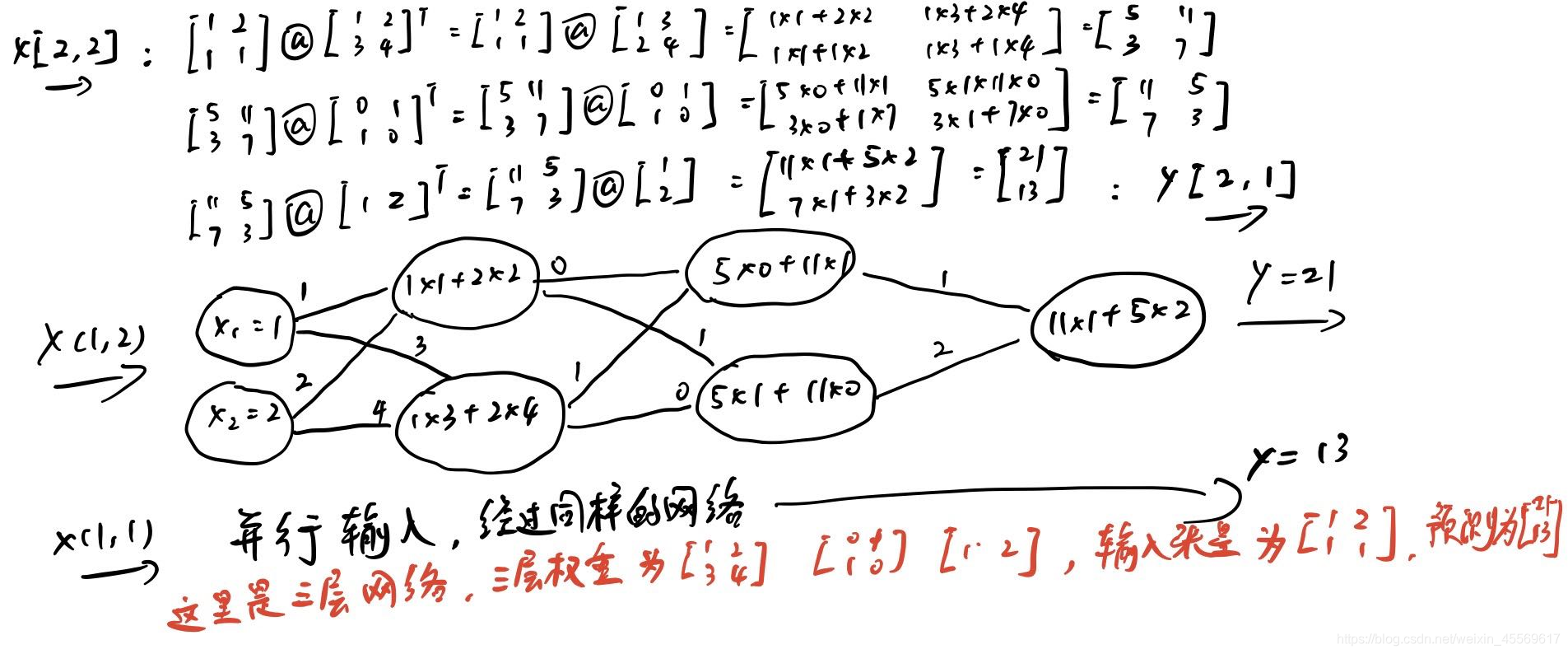
下图是一个三层神经网络感知器,每一个圆可以理解为一个节点,每一列代表一层线性全连接层。
当我们添加正则化,且超参数probability=0.5时,每个层中会有0.5的概率使那个节点失效。那么张量的流动将不再经过这些节点输出,这个节点权重也不会被更新。
这就好比为什么训练只是奥迪车的训练集会只识别奥迪车?
因为感知器网络提取到了奥迪车标等标志性的特征。这个特征可能是x1,x2,x3,x4中的某一个与某一组权重作用产生从而学习到的。
所以通过人为的手段正则化,降低这种概率的发生。
如果关闭了较好的节点权重是比较糟糕的,那将会减轻这个糟糕权重对整个网络梯度影响;如果关闭了较差的节点权重是非常好的,那么其他糟糕权重的梯度更新将不会影响到它。
换句话说,正则化可以理解为防止我们的模型学习学习傻了,不会举一反三。
另外dropout只针对训练,测试时我们不希望有节点被关闭,所以不应该使用。

# 创建一个带有正则化的多层感知器的类
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
'''
input_dim(int):输入size
hidden_dim(int):第一个线性层输出的size
output_dim(int):第二个线性层输出的size
'''
super().__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
'''
x_in:输入的tensor数据。x_in.shape == (batch,input_dim)
apply_softmax:softmax函数的激活标志
此函数最终返回一个处理后的tensor。tensor.shape == (batch, output_dim)
'''
intermediate = f.relu(self.fc1(x_in))
output = self.fc2(f.dropout(intermediate, p=0.5))# 正则化的用法类似激活函数,对第二个线性层添加正则化
if apply_softmax:
output = f.softmax(output, dim=1)
return output
# 实例化带正则化的多层感知器
batch_size = 2
input_dim = 3
hidden_dim = 100
output_dim = 4
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
# 随机输入测试带正则化的MLP
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
# 使用多层感知器产生概率输出(softmax)
y_output = mlp(x_input, apply_softmax=True)
describe(y_output)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 3])
Values:
tensor([[0.5250, 0.5245, 0.5465],
[0.4157, 0.4700, 0.7243]])
Type:torch.FloatTensor
Shape/size:torch.Size([2, 4])
Values:
tensor([[0.3354, 0.2249, 0.2417, 0.1980],
[0.2519, 0.3375, 0.2142, 0.1965]], grad_fn=< SoftmaxBackward>)
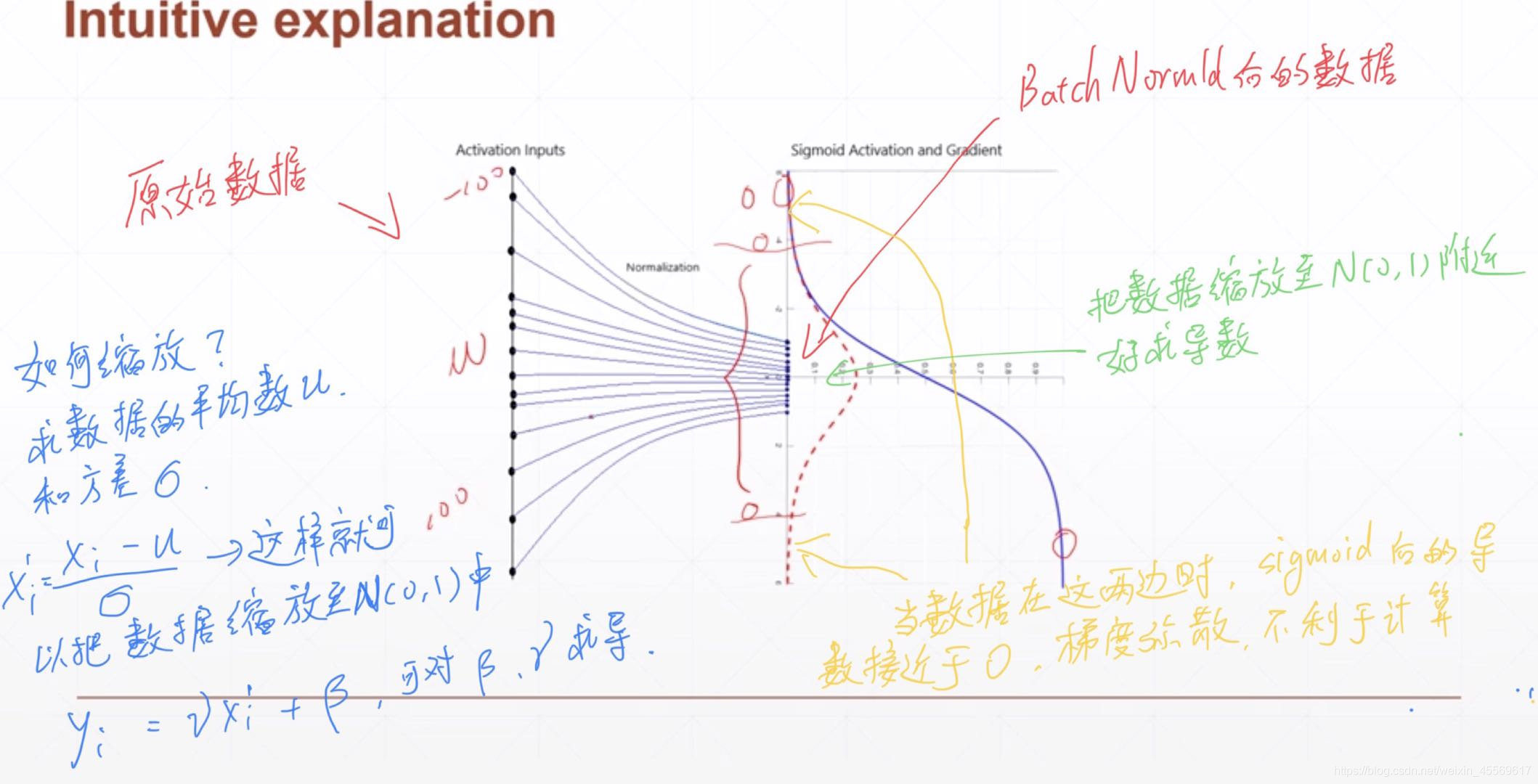
批规范化BatchNorm
没有BatchNorm,需要小心的调整学习率和权重初始化,但是有了BN可以放心的使用大学习率,较大的学习率极大的提高了学习速度。
Batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等
batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果。
能够加快收敛速度,提高精度。
同样,测试时没必要进行批规范化。
x = torch.rand(1, 16, 7, 7)# 产生随机均匀分布(0,1)之间,形状是[b=1, c=16, h=7, w=7]
layer = nn.BatchNorm2d(16) # c=16 和输入形状的channels一致
out = layer(x)
print(x.shape)
print(out.shape)
print(layer.weight) # 新的权重,图片中的那个符号
print(layer.bias) # 新的偏置,图片中的β
print(layer.running_mean) # 输入的数据以channel来看每层的平均数
print(layer.running_var) # 输入的数据以channel来看每层的平方差
torch.Size([1, 16, 7, 7])
torch.Size([1, 16, 7, 7])
Parameter containing:
tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.],
requires_grad=True)
Parameter containing:
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
requires_grad=True)
tensor([0.0530, 0.0509, 0.0420, 0.0489, 0.0530, 0.0539, 0.0488, 0.0588, 0.0557,
0.0504, 0.0559, 0.0507, 0.0523, 0.0431, 0.0449, 0.0454])
tensor([0.9095, 0.9084, 0.9074, 0.9087, 0.9090, 0.9086, 0.9093, 0.9070, 0.9076,
0.9060, 0.9087, 0.9087, 0.9078, 0.9093, 0.9077, 0.9082])
卷积神经网络CNN
# 创造一个图片的张量数据
batch_size = 2
channels = 3
height = 28
width = 28
data = torch.randn(batch_size, channels, height, width) # data.shape=[2, 3, 28, 28]每批次两张图,三通道RGB的彩色图,高28宽28的图片数据
print(data.shape)
torch.Size([2, 3, 28, 28])
# 对于图片一般用二维卷积Conv2d(输入通道数=3,输出通道数=16,卷积核的大小=5*5,滑动步长=1,填充=2)
conv_a = nn.Conv2d(in_channels=channels, out_channels=16, kernel_size=5, stride=1, padding=2)
intermediate1 = conv_a(data)# 这其中有16个5*5大小的卷积核扫描这三个通道的信息,最后输出为16个通道
print(intermediate1.shape)# new_height = (height − kernel_size + 2*padding )/stride+1 根据滑动窗计算得出
torch.Size([2, 16, 28, 28])
# 一维卷积可以卷积三维张量,二维卷积卷积四维张量,三位卷积卷五维张量
# (2+x)维张量:[batch_size, channels, x维信息] 使用x维卷积
conv_b = nn.Conv1d(in_channels=10, out_channels=16, kernel_size=3, stride=1)
intermediate2 = conv_b(torch.randn(batch_size, 10, 7))
print(intermediate2.shape) # 5 = (7 − kernel_size + 2*padding )/stride+1
torch.Size([2, 16, 5])
# 批规范化(BatchNorn)
#通过将激活量缩放为零的均方值和单位方差,对cnn的输出进行转换,也有1d,2d,3d之分
conv_c = nn.Conv3d(10, 16, 3) # 简写
intermediate3 = conv_c(torch.randn(batch_size, 10, 9, 9, 9))
bn = nn.BatchNorm3d(16) # 批规范化,注意这个16,卷积的输出维度==批规范化的输入维度,
intermediate3 = bn(intermediate3)
print(intermediate3.shape) # 7 = (7 − kernel_size + 2*padding )/stride+1
torch.Size([2, 16, 7, 7, 7])
# 池化层(pooling) 常见有最大值池化,平均值池化 也有1d,2d,3d之分
pool = nn.MaxPool1d(kernel_size=2, stride=2) # 最大值池化
intermediate4 = pool(intermediate2)
print(intermediate2.shape) # 5 = (7 − kernel_size + 2*padding )/stride+1
print(intermediate4.shape) # 2 = (5 − max_kernel_size + 2*max_padding )/max_stride+1 取整
torch.Size([2, 16, 5])
torch.Size([2, 16, 2])
# 卷积神经网络
# 一维卷积网络输入张量的size[batch_size, channels, input_dim]
class ConvNet(nn.Module):
def __init__(self, channels, input_dim, output_dim):
'''
self.layer1:第一个包含卷积层、BN层、激活函数、最大值池化层的容器层,提取一层抽象特征
self.layer2:第二个包含卷积层、BN层、激活函数、最大值池化层的容器层,提取一层抽象特征
self.fc:一个线性层=全连接层,将提取出来的抽象特征进行预测
'''
super().__init__()
self.layer1 = nn.Sequential( # 这是一个容器,可以在里面记录模型顺序
nn.Conv1d(in_channels=channels, out_channels=16, kernel_size=5, stride=1, padding=2), # h1 = (input_dim − 5 + 2*2 )/1+1
nn.BatchNorm1d(16), # 对这16个结果进行批规范处理,能够加快收敛速度,提高精度。
nn.ReLU(), # 激活函数
nn.MaxPool1d(kernel_size=2, stride=1))# h2 = (h1 − 2 + 2*0 )/1+1
self.layer2 = nn.Sequential(
nn.Conv1d(16, 32, kernel_size=3, stride=1, padding=2), # h3 = (h2 − 3 + 2*2 )/1+1
nn.BatchNorm1d(32),
nn.ReLU(),
nn.MaxPool1d(kernel_size=3, stride=1)) # h4 = (h3 − 3 + 2*0 )/1+1 此时size为[batch_size, 32, h4]
self.fc = nn.Linear((input_dim-1)*32, output_dim) # 真正进入线性层的input_dim == 32*h4
# 前馈网络过程
def forward(self, x):
out = self.layer1(x) # 不使用容器的话,就需要一层一层地跑。有了容器,我们可以将几层堆成一组,一组一组地跑。
out = self.layer2(out)
out = out.reshape(out.size(0), -1)# 输入进线性层需要将out.size[batch_size, 32, h4]打平为out.size[batch_size, 32*h4]
out = self.fc(out)
return out
这就相当于之前我们是直接拿输入的数据来全连接层,现在是拿经过卷积处理的数据来全连接层。
经过卷积层的张量会被挖掘出原张量的不显而易见的特征,这对于后面的计算预测有着关键作用。
权值共享
如何理解卷积核带来的权值共享?比方说我们输入的二维图像张量size=(1, 3, 3),长下面这样:
[[1, 3, 4],
[1, 3, 4],
[1, 3, 4]]
标签张量size=(1, 1),长下面这样:
[1]
我们将它打平成这个样子[1, 3, 4, 1, 3, 4, 1, 3, 4]进入线性层,很明显线性层中会有需要有9个权重参数和1个偏置参数。(y = w^ * x^ + b)
那如果是一张100 * 100的图片,就需要10^4个权重参数和1个偏置参数。每一个像素点都需要一个权重,所以说他们的权重是不共享的。
这时候我们用一个大小为5 * 5步长为5的卷积核去卷积这个图片,会得到20 * 20的特征图,接下去可以再卷积或者直接打平。
我们再用一个大小为5 * 5步长为5的池化层去沉淀这个特征图,会得到4 * 4的特征图,然后直接打平。
可以看到我们现在只需要16个权重参数加上5 * 5的卷积核需要25个权重参数,所以这次只需要41个权重参数和1个偏置参数
41对比10000,显然少了很多参数,加快了运算,又提取了特征。由于这张图一开始都是用这25个权重参数获取新的形态,这25个权重参数也就被所有的像素点所共享。
这就是权值共享,实际意义便是减少参数量,使得更深层次的卷积有可能实现。
batch_size = 2
channels = 3
input_dim = 7
out_dim = 1
x = torch.randn(batch_size, channels, input_dim)
describe(x)
cnn = ConvNet(channels, input_dim, out_dim)
y = cnn(x)
describe(y)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 3, 7])
Values:
tensor([[[-1.5294, 0.3121, -1.6591, -0.3043, 0.7956, -1.7886, -0.4614],
[ 0.0155, -1.4529, 0.7872, -0.1117, 0.8347, 0.8125, 0.5622],
[ 0.6974, 0.5934, -0.2643, 0.3309, -0.2314, 0.0508, 1.4656]],[[-2.5783, -0.7624, -0.7206, 1.7653, -0.7309, -1.2428, 0.2016], [ 0.1978, 1.3439, -0.5423, -0.4561, 3.0734, 0.6790, -0.4076], [ 0.7416, 2.2095, 1.7724, 1.0179, -0.9893, -0.0058, -1.1747]]]) Type:torch.FloatTensor Shape/size:torch.Size([2, 1]) Values: tensor([[-0.0659], [-0.4749]], grad_fn=< AddmmBackward>)
残差网络ResNet
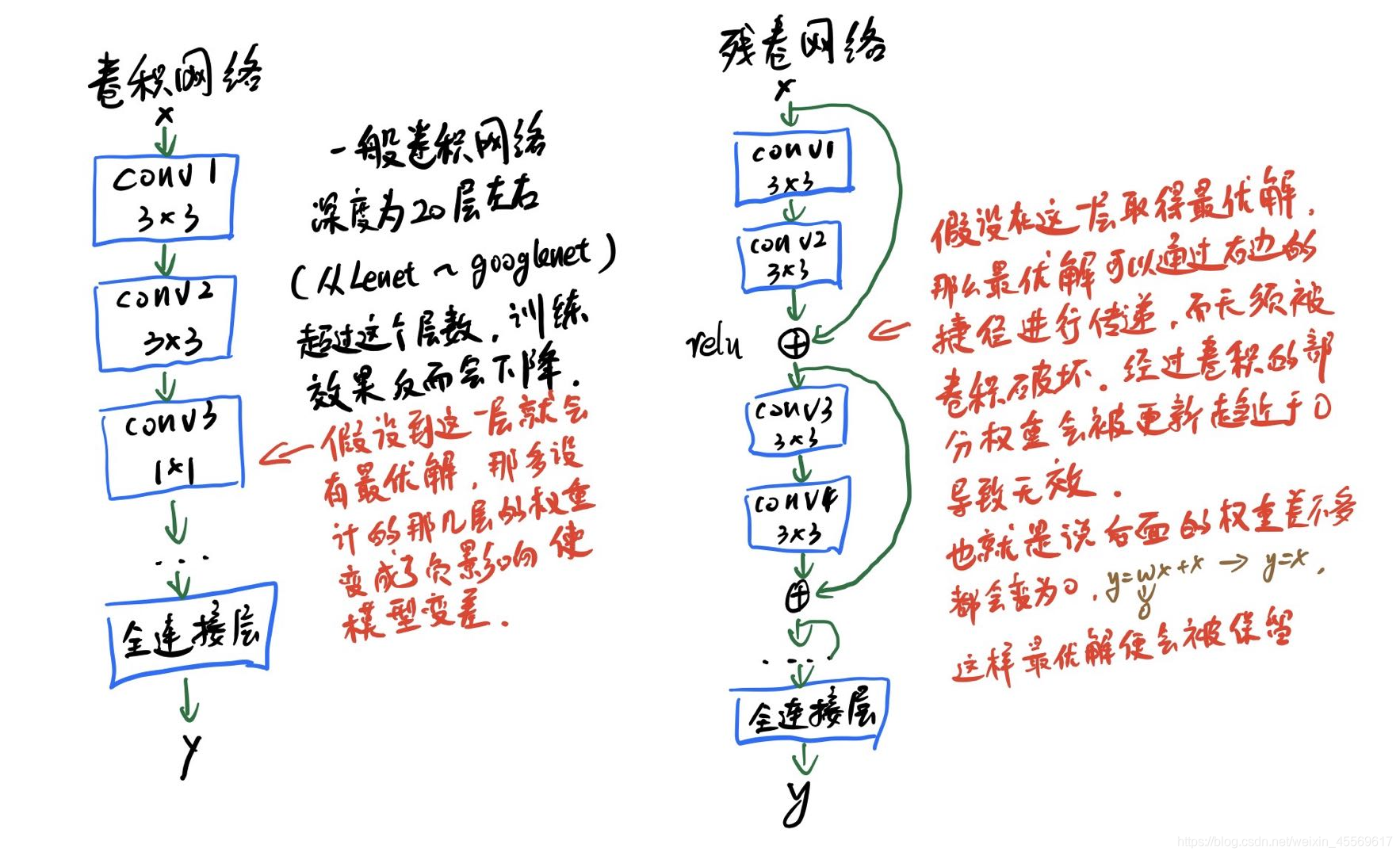
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
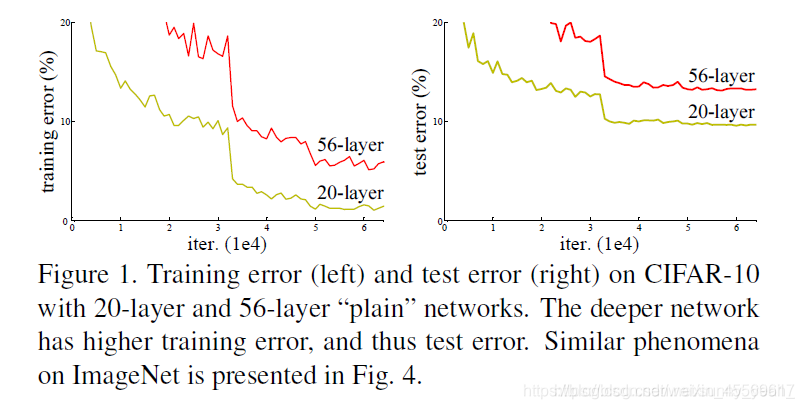
目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
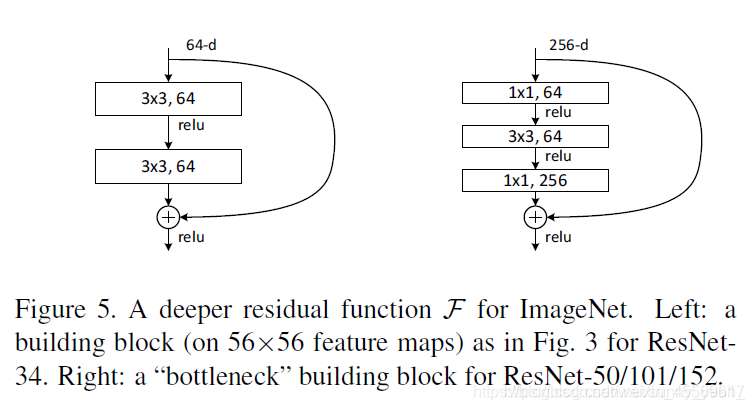
再放一遍ResNet结构图。要知道咱们要介绍的核心就是这个图啦!(ResNet block有两种,一种两层结构,一种三层结构)
现在咱们将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x
残差:观测值与估计值之间的差。
这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。
我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。
那么咱们要求解的问题变成了H(x) = F(x)+x。
咱们干嘛非要经过F(x)之后在求解H(x)啊!整这么麻烦干嘛!
咱们开始看图说话:如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值对不?那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧?
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了?
当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈
其中有几层就叫resnet几,例如我圈着的那一列,1 + 1 + 3 * 3 + 3 * 4 + 3 * 6 + 3 * 3 = 50,最后的全连接层不算。

这里演示下设计一个resnet18的感知器,resnet18网络的输入size大约为[b, 3, 224, 224]
class ResBlock(nn.Module):
'''
残差块:对应图片中的conv2_x、conv3_x、conv4_x、conv5_x
'''
def __init__(self, ch_in, ch_out):
super().__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
'''
如果某一残差层的输入和输出维度不一样,那是进行矩阵相加。
所以这里先进行判断,如果一样,不改变输入的size;如果不一样,则将输入的size与输出的size保持一致(尽量不改变或少改变输入张量特征)
'''
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] ---> [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
out = f.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out = self.extra(x) + out # 残差相加
return out
class ResNet18(nn.Module):
'''
18层的残差网络
'''
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.blk1 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
ResBlock(64, 128),
ResBlock(128, 128),
)
self.blk2 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
ResBlock(128, 256),
ResBlock(256, 256),
)
self.blk3 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
ResBlock(256, 512),
ResBlock(512, 512),
)
self.blk4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
ResBlock(512, 512),
ResBlock(512, 512),
)
self.outlayer = nn.Linear(512*1*1, 1)
def forward(self, x):
x = f.relu(self.conv1(x)) # 一层卷积层
x = self.blk1(x) # 四层卷积
x = self.blk2(x) # 四层卷积
x = self.blk3(x) # 四层卷积
x = self.blk4(x) # 四层卷积
x = f.adaptive_avg_pool2d(x, [1, 1]) # 自适应池化层 平均池
x = x.view(x.size(0), -1)
x = f.softmax(self.outlayer(x), dim=1) # 一层全连接层, 一共18层
return x
net = ResNet18()
x = torch.randn(2, 3, 224, 224)
out = net(x)
describe(out)
Type:torch.FloatTensor
Shape/size:torch.Size([2, 1])
Values:
tensor([[1.],
[1.]], grad_fn=< SoftmaxBackward>)
循环神经网络RNN
卷积神经网络是针对二维位置相关的图片,自然界除了位置相关的信息以外,还存在另一种跟时序相关的数据类型,例如:序列信号,语音信号。对于按时间轴不停产生的信号,神经网络中,我们称其为temporal signals,而循环神经网络处理的就是拥有时序相关或者前后相关的数据类型(Sequence)。
embedding
在循环神经网络中,将文字编码成下面的格式进行表示训练数据:[ b, seq_len, fearture_len ]
b:batchsize。seq_len:时序数据的长度(一句话有seq_len个单词,一段录音有seq_len时刻等)。fearture_len:对于每一个seq_len,我们用多少纬度来表示
例如: '你好吗’embedding成变量x
x.shape = [ 1, 3, 2 ]
x[:,0,:] = ‘你’ = [0.2,0.1]
x[:,1,:] = ‘好’ = [0.3,0.2]
x[:,2,:] = ‘吗’ = [0.6,0.5]
embedding的操作是为了让计算机能看懂文字,并且能用文字进行操作运算
word_to_ix = {
"你":0, "好":1, "吗":2}
lookup_tensor = torch.tensor([word_to_ix["你"]], dtype=torch.long)# 获取单词的索引号
embeds = nn.Embedding(3, 2) # 随机初始化表格,(3,2)对应上面的,也可以用word2vec或者GloVe的现成表格(对大部分的单词进行了唯一编码)
_embed = embeds(lookup_tensor) # 查询表格中对"你"的编码
print(_embed)
tensor([[0.4558, 0.6416]], grad_fn=< EmbeddingBackward>)
'''
from torchnlp.word_to_vector import GloVe # 需要下载还挺大的,所以这段代码给注释了,想要研究nlp的可以试一试
vectors = GloVe()
vectors['hello'] # 使用glove来查表hello这个单词的编码
'''
rnn原理
通过word embedding,我们可以把句子中的所有单词数值化后,映射到向量空间中去,为了得到最佳的word embedding结果,我们会把数值化的单词输入全连接网络中进行训练

针对参数上述问题,我们提出权重共享的思想,即每一个全连接层共享同一个w和b:
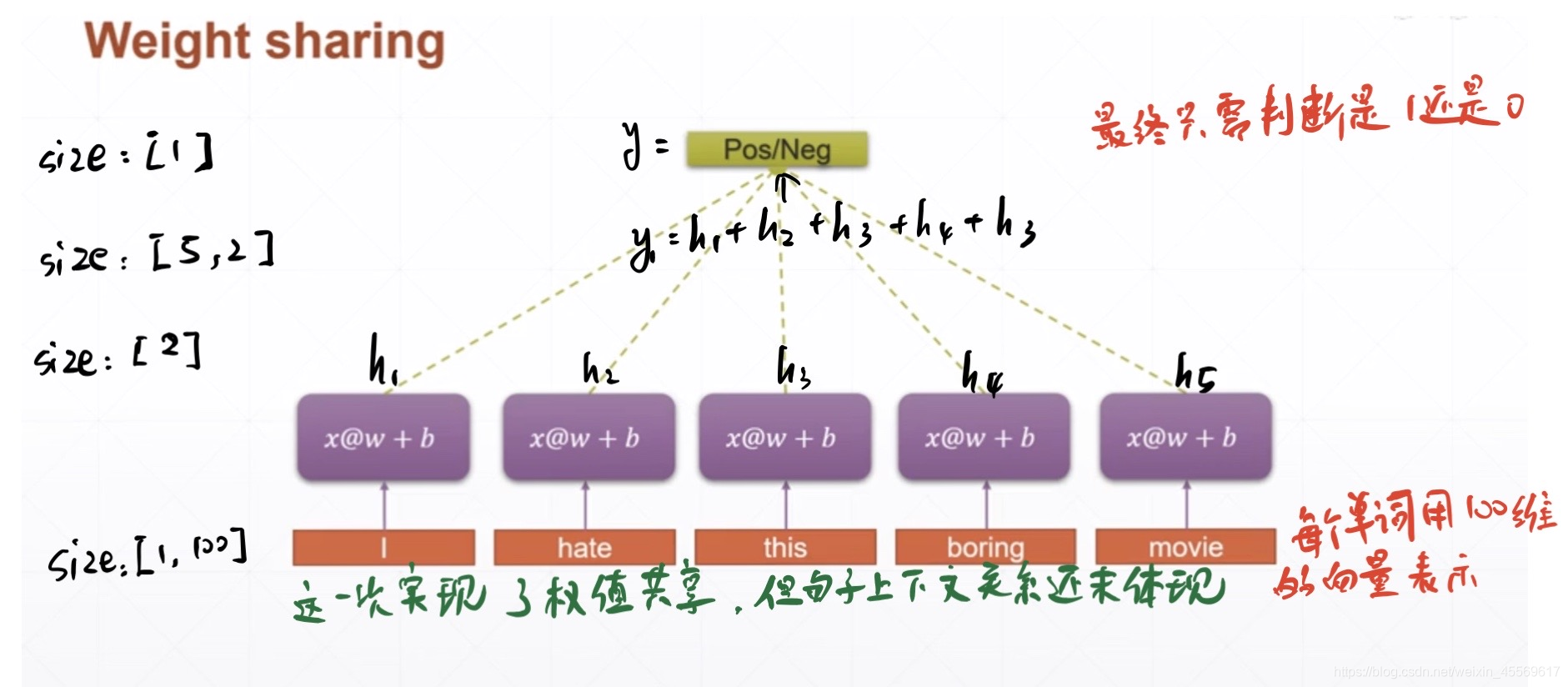
针对语义信息,由于现有网络没有全局的综合的高层的语义信息抽取过程,所以,我们需要一个全局的数据去存储整个句子的语义信息,即需要一个容器去存储从第一个单词到最后一个单词的总体语义信息,该容器被称为memory。
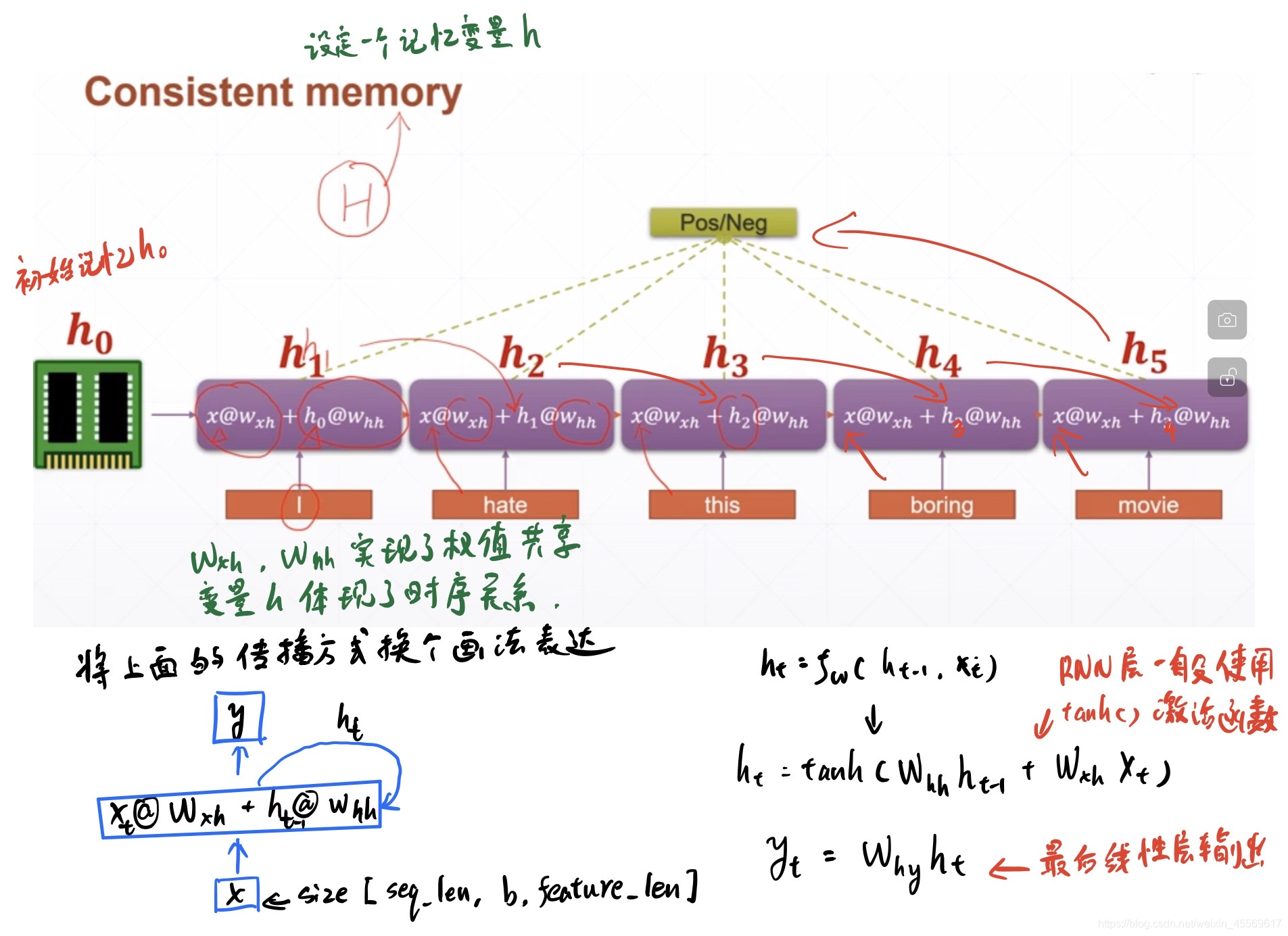
所有神经网络结构,都需要能进行反向梯度更新,那么,RNN是怎么求解梯度的呢?首先,我们把RNN网络按时间轴进行展开:

从上图的最后我们也可以看出,k时刻会得到{W_hh}的k次方,这一项会导致RNN很容易出现梯度弥散或者梯度爆炸。
RNN训练时数据纬度的变化
输入一个批次的训练数据集(由embedding转换后的句子) [ b, seq_len, fearture_len ] = [ 128, 80, 100 ],由于seq_len是句子的长度,而一次RNN网络处理的是一个单词,所以,我们按seq_len进行展开,则数据纬度变成:[ b, fearture_len ] = [ 128, 100 ]。
根据公式h_t=x_t@w_x + h_t-1@w_hh可得:
h = [b,feature_len]@[fearture_len, hidden_len] + [b, hidden_len]@[hidden_len, hidden_len]
则[fearture_len, hidden_len] = [ 100, 64],[b, hidden_len]=[128, 64],[bidden_len, hidden_len]=[64,64],这样我们就可以把[b, 100]纬度的数据降纬到[ b, 64 ]。
h_0则可以设为[b, hidden_len]=[128, 64]的全0矩阵
由于我们称之为记忆的h_t在学术界被称作隐状态,所以与h_t有关的变量一般取名为hidden
单层rnn
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=1)# 输入fearture_len=100,每次rnn模块输出fearture_len=20,层数为1
print(rnn)
x = torch.randn(10, 3, 100)# 输入张量,形状为[seq_len, b, fearture_len ] = [ 10, 3, 100 ] seq_len和b的位置可以不一样
out, h = rnn(x, torch.zeros(1, 3, 20))# torch.zeros(1, 3, 20)初始化h_0,形状为[num_layers, b, hidden_size ] = [ 1, 3, 20 ]
print(out.shape, h.shape)# out.size = [seq_len, b, hidden_size ] = [ 10, 3, 20 ] h形状不变
# out为一句话中所有单词的状态和,h为最后一个单词的状态
RNN(100, 20)
torch.Size([10, 3, 20]) torch.Size([1, 3, 20])
多层rnn
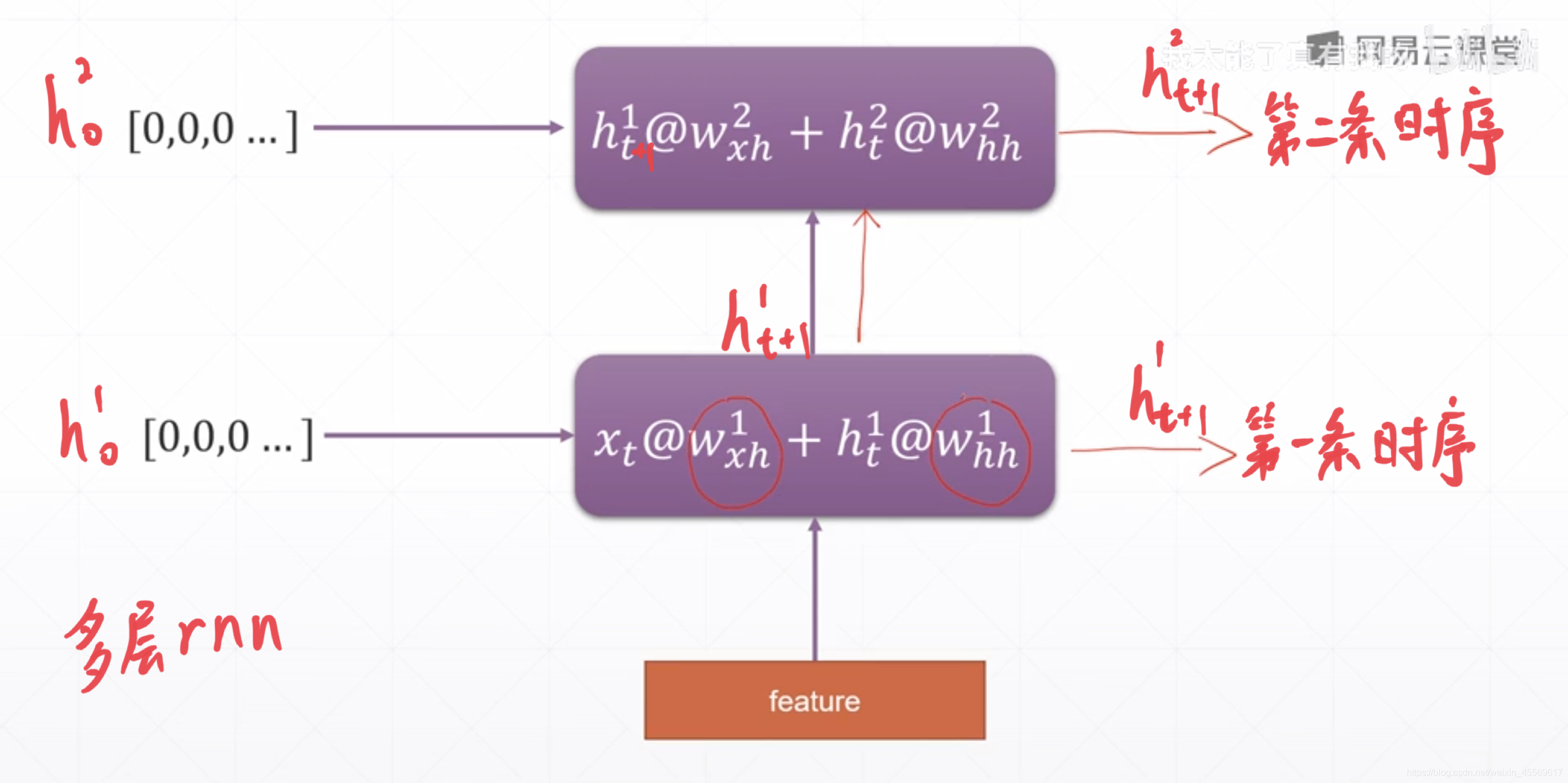
rnn = nn.RNN(input_size=100, hidden_size=20, num_layers=4)# 输入fearture_len=100,每次rnn模块输出fearture_len=20,层数为4
print(rnn)
x = torch.randn(10, 3, 100)# 输入张量,形状为[seq_len, b, fearture_len ] = [ 10, 3, 100 ] seq_len和b的位置可以不一样
out, h = rnn(x)# 未输入h_0,默认为 0,形状为[num_layers, b, hidden_size ] = [ 4, 3, 20 ]
print(out.shape, h.shape)# out.size = [seq_len, b, hidden_size ] = [ 10, 3, 20 ] h形状不变
# out为最后一层的所有单词的状态和,h为每一层的最后一个单词的状态
RNN(100, 20, num_layers=4)
torch.Size([10, 3, 20]) torch.Size([4, 3, 20])
# 我们除了可以直接调用这个rnn网络,也可以单独使用rnn单元构建rnn网络
cell1 = nn.RNNCell(100, 30)
cell2 = nn.RNNCell(30, 20)
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1)
h2 = cell2(h1, h2)
print(h2.shape)
torch.Size([3, 20])
梯度爆炸/梯度弥散
我们在求RNN的梯度时发现存在一个W权重的k次方,显然如果0<W<1,那么Wk会趋近于0(梯度弥散);如果W>1,那么Wk会趋近于无穷大(梯度爆炸)。
CNN其实也有类似的问题,在反向传播时,最后几层保留的梯度信息较多,而前面几层的梯度信息则较少。残差网络就是保留一个捷径,让梯度信息能更多地传递到前面。
解决办法一:针对梯度爆炸,最简单有效的方法就是对每次求得的梯度,都进行缩放。即保持其梯度方向不变,梯度模长度缩放到某一范围。这样做能使得当前梯度前进的距离控制在某一个较小范围。
#...
rnn.zero_grad() # 清空梯度
#loss.backward() # 反向传播
for p in rnn.parameters(): # 遍历所有的权重
torch.nn.utils.clip_grad_norm_(p, 10) # 将所有权重的梯度模长度缩放至不大于10
#optimizer.step() # 更新梯度
# ...
解决办法二:针对梯度弥散和memory记忆不足的缺陷,我们可以使用长短期记忆网络(LSTM)或者GRU。
LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
一个句子中,并不是所有单词都是有用的,也不是所有单词之间的语义是需要记住的,所以,LSTM网络在传统RNN网络中设置了三道闸门用于控制不同对象的输出量,达到选择性记忆的目的。
在这里h_t仅代表输出,记忆memory由专门的C_t来表示。
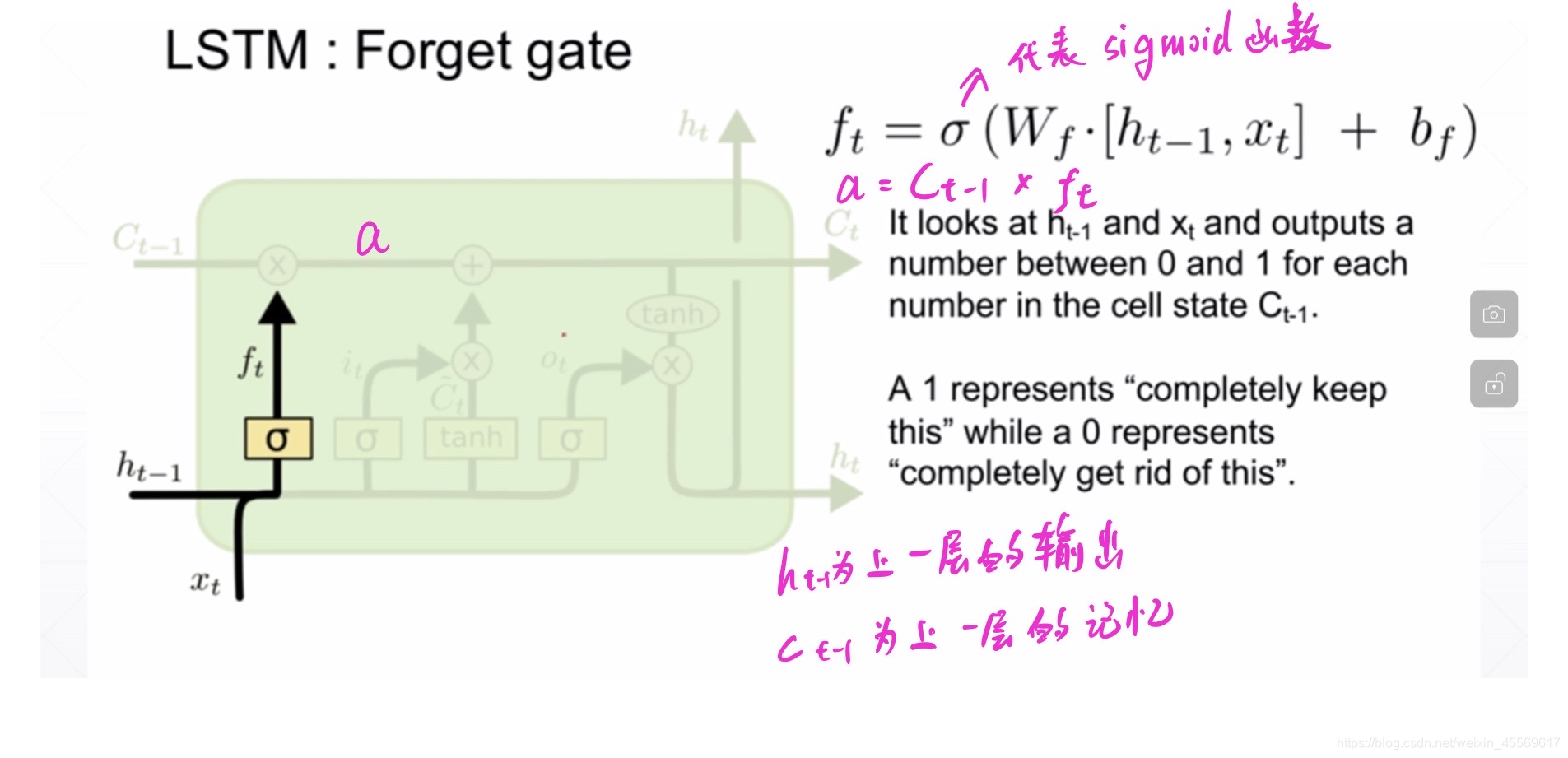
б为sigmoid函数,通过这个函数可以将数据变换为0-1范围内的数值,从而来充当门控信号。
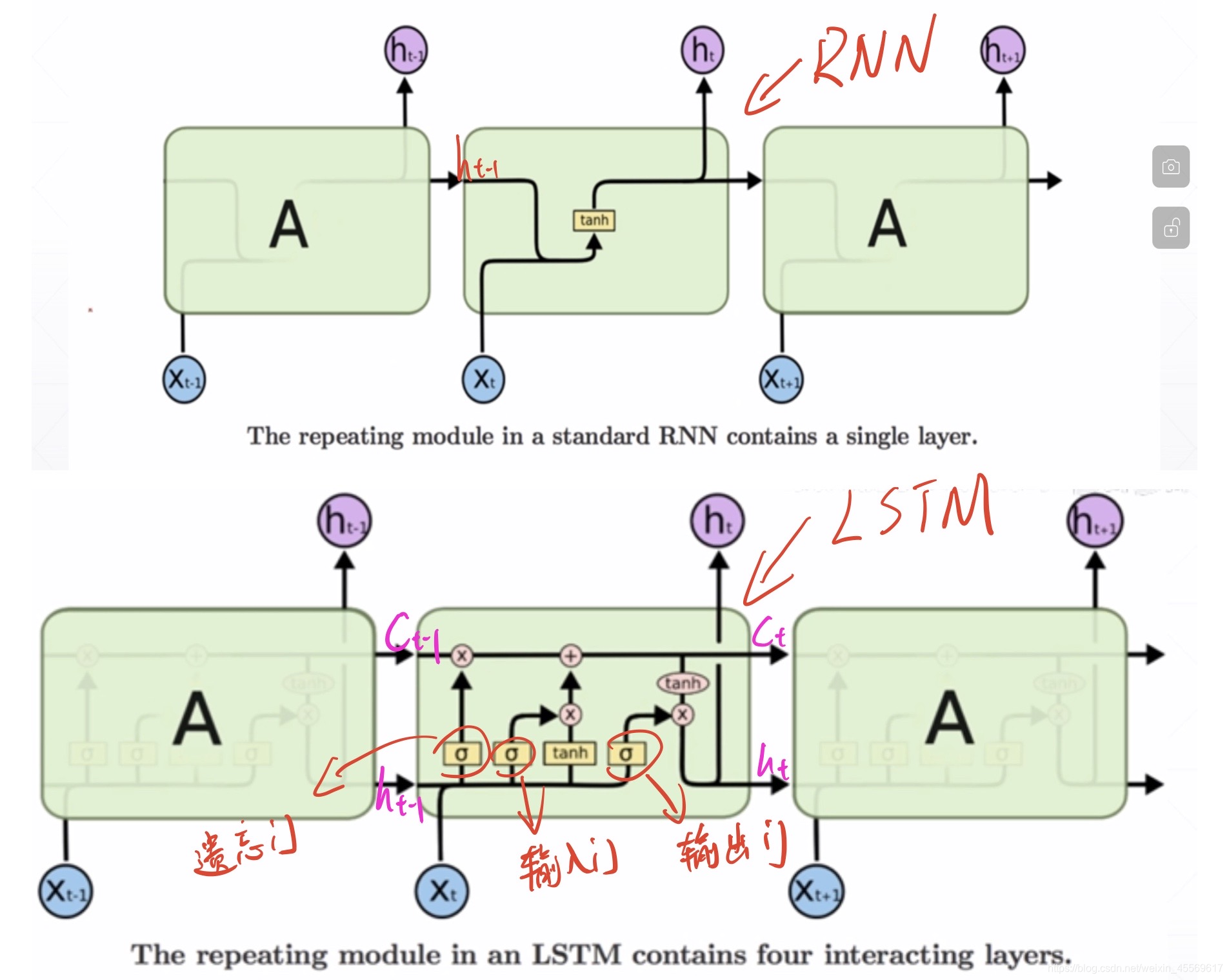
遗忘门或记忆门
输入门

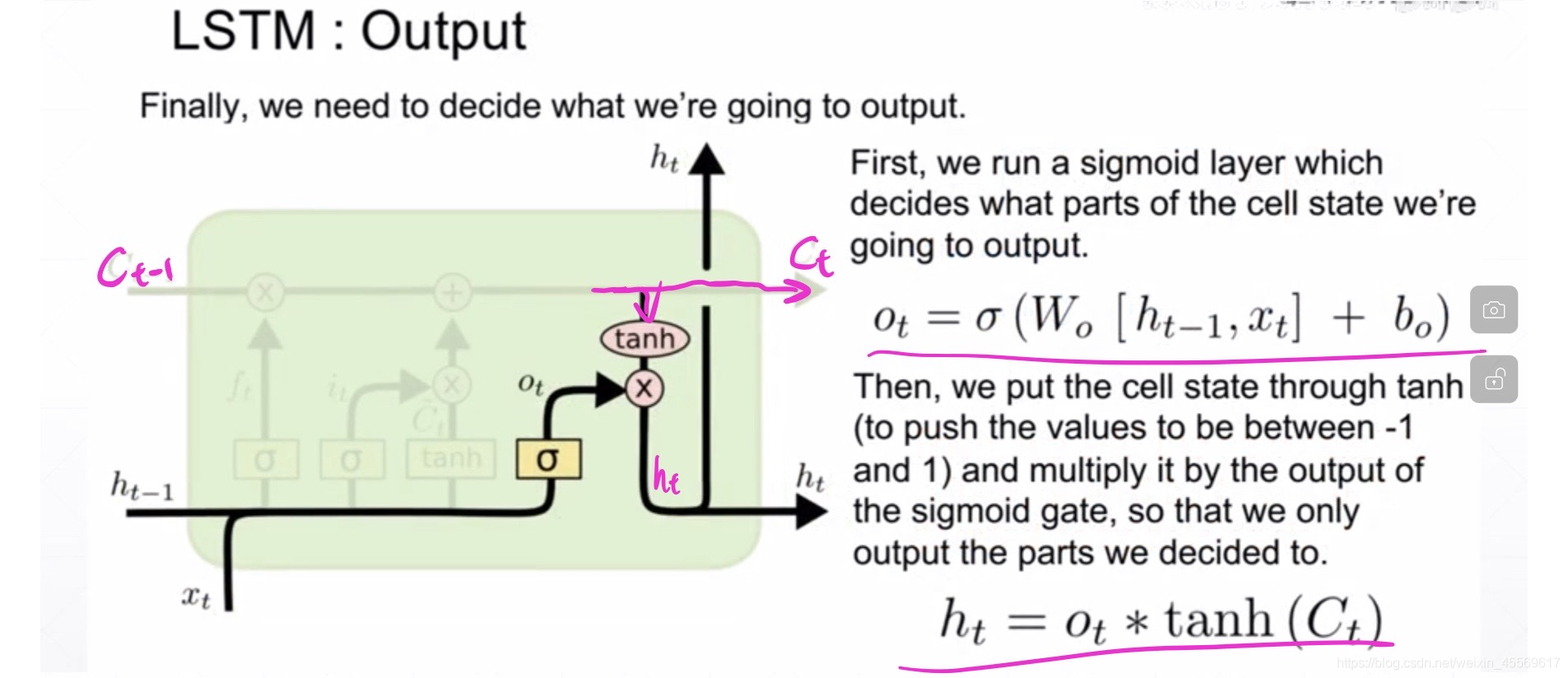
输出门

如何避免梯度爆炸/弥散
在LSTM网络中,其梯度由原来相乘的形式变成了三道门相加的形式,避免了W_hh的k次方的出现,所以,不会轻易的出现梯度弥散的情况,也减轻了memory信息衰退的情况,其具体求导公式如下:
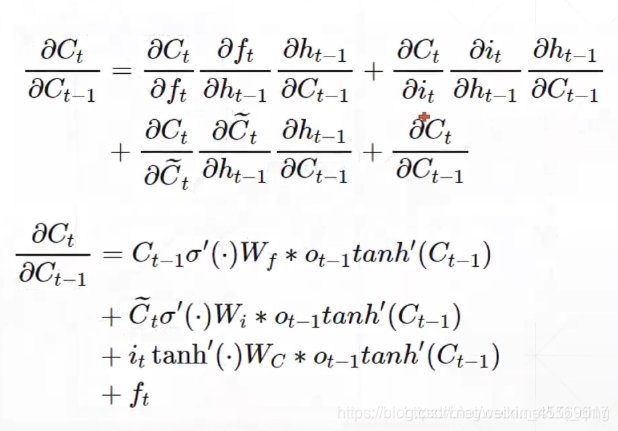
lstm = nn.LSTM(input_size=100, hidden_size=20, num_layers=4)
print(lstm)
x = torch.randn(10, 3, 100)
out, (h, c) = lstm(x)
print(out.shape, h.shape, c.shape)
LSTM(100, 20, num_layers=4)
torch.Size([10, 3, 20]) torch.Size([4, 3, 20]) torch.Size([4, 3, 20])
cell1 = nn.LSTMCell(input_size=100, hidden_size=30)
cell2 = nn.LSTMCell(input_size=30, hidden_size=20)
h1 = torch.zeros(3, 30)
c1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
c2 = torch.zeros(3, 20)
for xt in x:
h1, c1 = cell1(xt, [h1, c1])
h2, c2 = cell2(h1, [h2, c2])
print(h2.shape, c2.shape)
torch.Size([3, 20]) torch.Size([3, 20])
GRU(Gate Recurrent Unit)
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
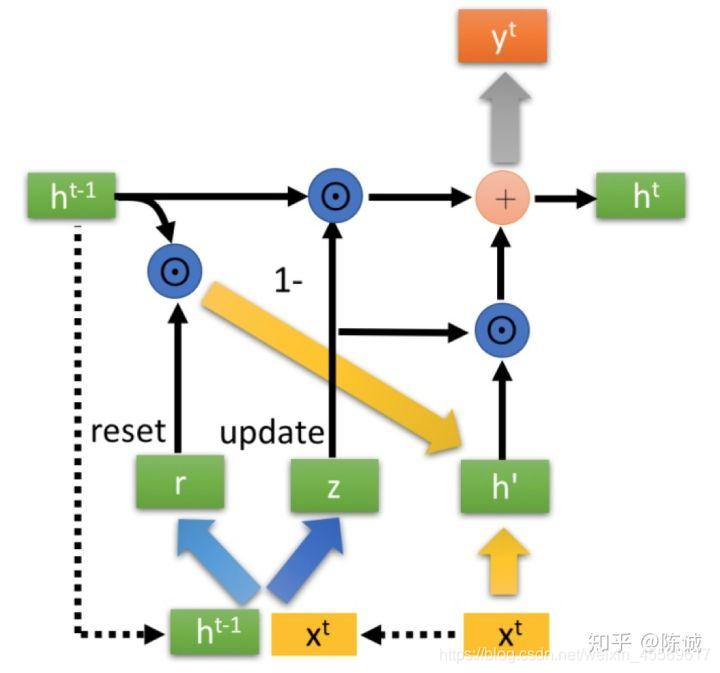
重置门reset gate

更新门update gate

gru = nn.GRU(input_size=100, hidden_size=20, num_layers=4)
print(gru)
x = torch.randn(10, 3, 100)
out, h = gru(x)
print(out.shape, h.shape)
GRU(100, 20, num_layers=4)
torch.Size([10, 3, 20]) torch.Size([4, 3, 20])
cell1 = nn.GRUCell(100, 30)
cell2 = nn.GRUCell(30, 20)
h1 = torch.zeros(3, 30)
h2 = torch.zeros(3, 20)
for xt in x:
h1 = cell1(xt, h1)
h2 = cell2(h1, h2)
print(h2.shape)
torch.Size([3, 20])