卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完。
本文 新智元 编辑:Aeneas 润
【新智元导读】开源万能模型微调工具LLaMA-Adapter发布,支持多模态输入输出。
LLaMA-Adapter,现在已经完全解锁了。
作为一个通用的多模态基础模型,它集成了图像、音频、文本、视频和3D点云等各种输入,同时还能提供图像、文本和检测的输出。
相比于之前已经推出的LLaMA-Adapter,这次的升级版研究人员将它命名为LLaMA-adapter V2。
论文:https://arxiv.org/abs/2304.15010
这是升级之后的多模态和双语功能示意图:
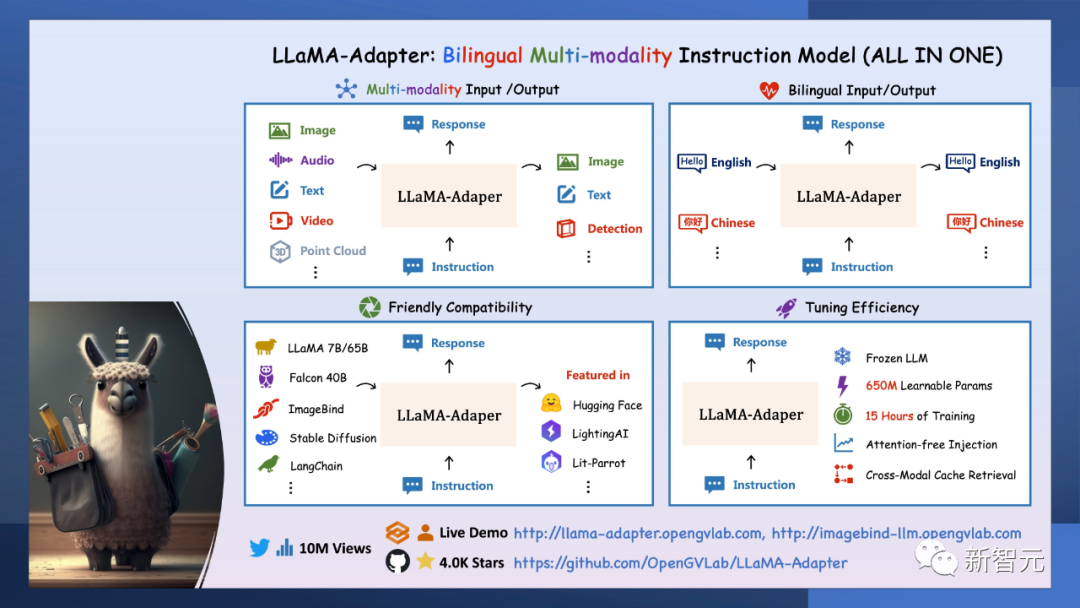
它是唯一可以结合多种模态的模型,例如,从3D点云和背景音频生成真实的图像。
而且,它还支持双语功能,能接收和生成多种语言的文本。
它还能和LLaMA / ImageBind,Falcon,LangChain等模型整合。

在8个A100 GPU上,仅用15个小时就训练出了LLaMA-Adapter,仅仅引入了650M的参数。

真·多模态
接下来,让我们体验下LLaMA-Adapte的魔力。
无论是文本、图像、视频、音频还是3D点云,这些真实世界的输入都可以通过它转换为高质量的文本。
输入一个三角钢琴的3D点云,它就会详细描述出这个三维物体的细节。
显然,英文的回答会比中文的回答详细得多。

3D点云输入令人非常印象深刻,因为它提供了比照片更准确的信息,并且可以集成到摄影测量应用中。
输入一段街道上车辆正在行驶的语音,问它当事人会是什么心情,它就猜测出,现在当事人可能比较愤怒和不满。

输入一段LOL的游戏视频,它就能识别出游戏的名字,还能答出里面的人物。

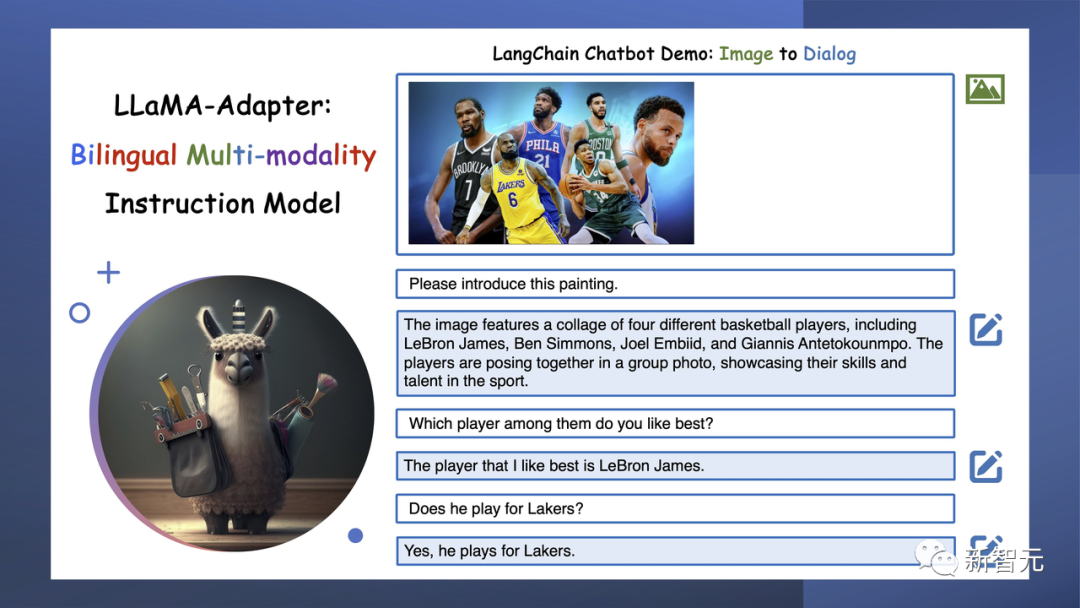
输入一张照片,它能告诉你这是京都的 Fushimi Inari Shrine 。

LLaMA-Adepter不仅仅是可以创建文本,还能够生成检测结果,这就为我们理解世界和与世界互动带来新的维度。
把检测GPT-4的这幅图输给它,它也很顺利地描述出了这幅图的怪异之处在哪里。

从3D点云或音频中,LlaMA-Adapter可以唤起一个生动而令人惊叹的视觉世界。它不仅仅是数据处理,它是从原始输入 创造艺术。
输入一阵海浪声,它会给你生成对应语音的图片。
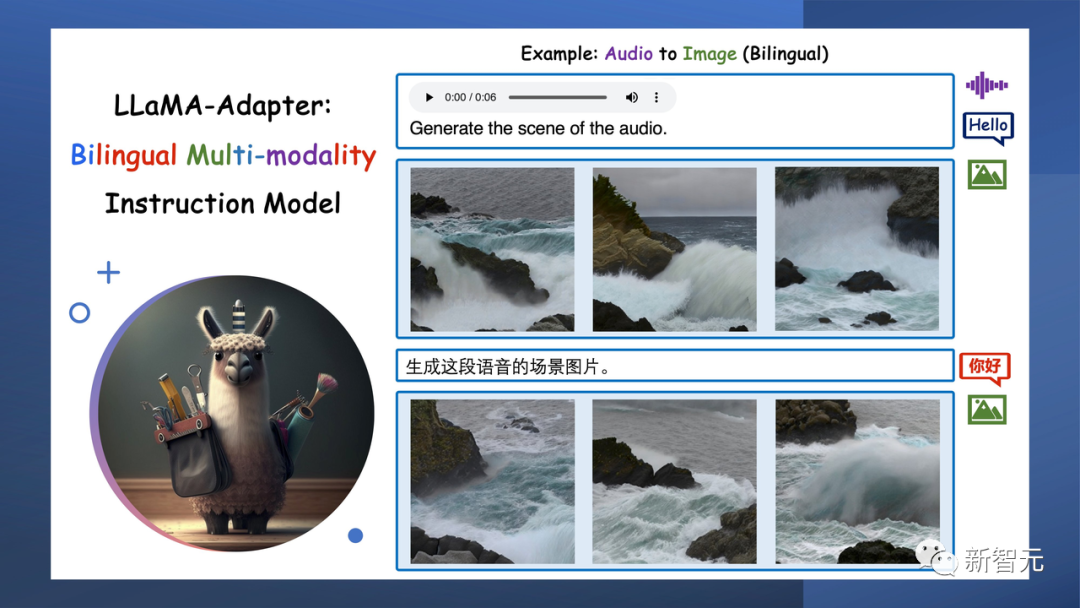
根据3D点云,它可以生成很生动的图片。

LLaMA-Adapter会模拟人类互动,听声音、看视频,还能生成文本,从而与世界建立更深层次的联系,实现AI通信的飞跃。
输入一个视频,它就会告诉你,图中人物正在做瑜伽。

更精彩的是,只要输入3D点云和背景音频,LLaMA-Adapter就可以重建现实世界的镜像。这是一种沉浸式体验的突破!
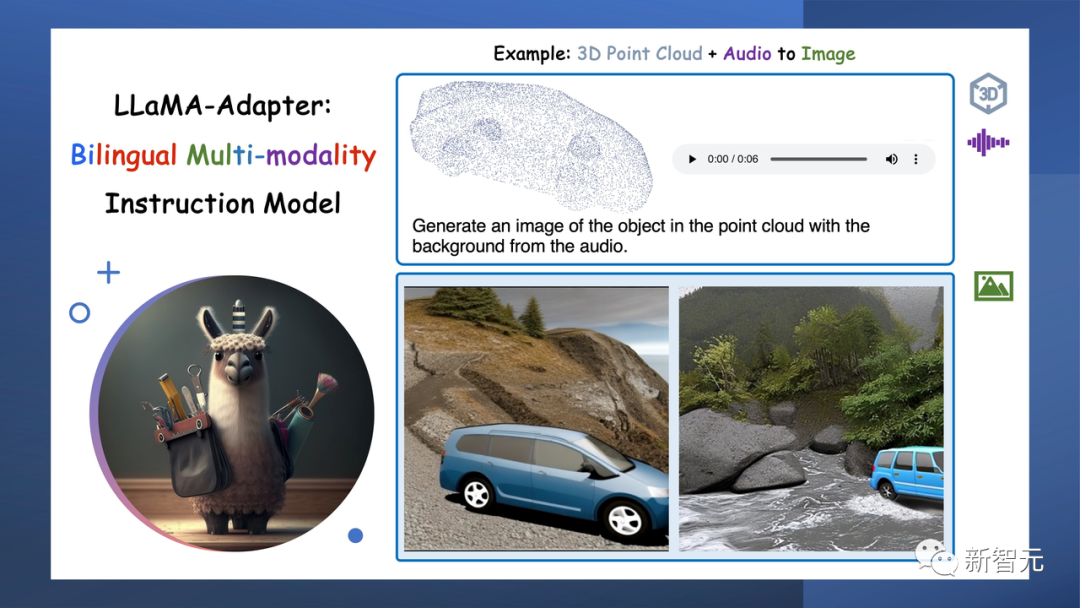
LLaMA-Adapter由LangChainAI提供支持,不仅可以与人类通信,还可以释放AI交互的无限潜力。
GitHub
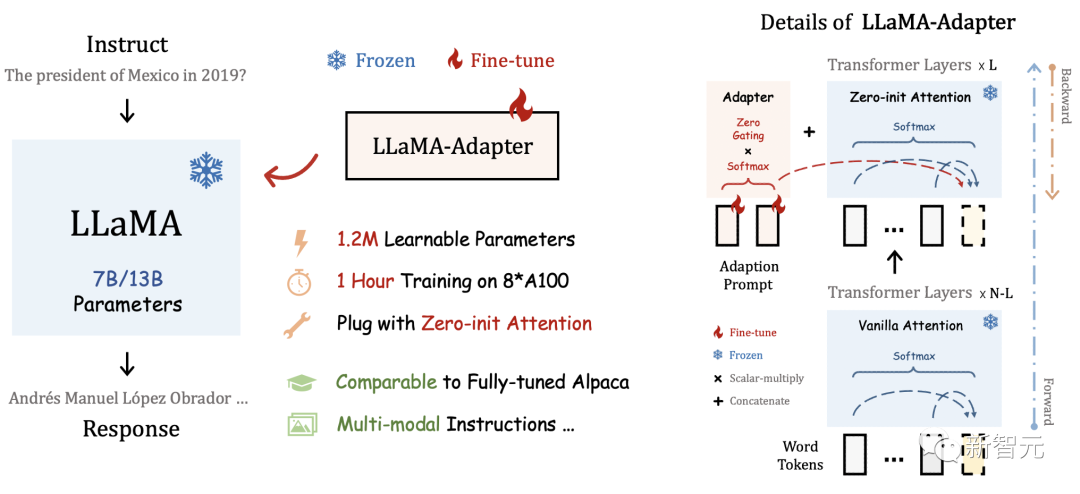
LLaMA-Adapter,这是一种轻量级适配方法,用于微调指令遵循和多模态LLaMA模型。
下图是LLaMA-Adapter和Alpaca的参数对比。
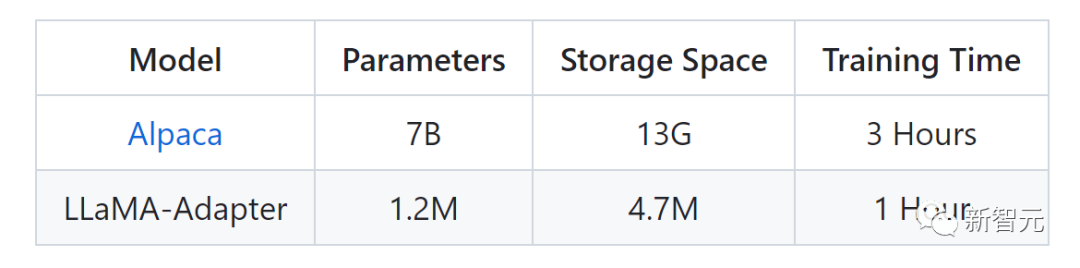
通过将适配器插入LLaMA的Transformer,研究者只引入了1.2M的可学习参数,并在1小时内将LLaMA转换为指令跟随模型。
为了在早期阶段稳定训练,研究者提出了一种具有zero gating机制的新型Zero-init注意力机制,以自适应地合并教学信号。
经过微调后,LLaMA-Adapter可以生成高质量的指令跟随句子,可与完全微调的Alpaca和Alpaca-Lora相媲美。
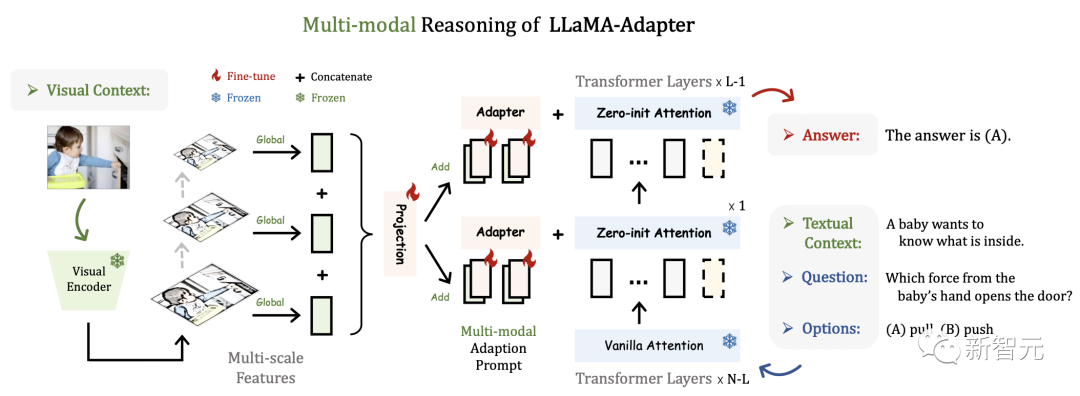
此方法可以简单地扩展到多模态输入指令。用于ScienceQA的图像条件LLaMA-Adapter的推理框架如下,其他模态(如音频和视频)也共享该框架。
LLaMA-Adapter V2让多模态和语言能力进一步提升
针对LLaMA-Adapter V2的重要改进,知友「星空」做了一个比较清晰的总结:
1. 通过线性层的偏差调整来增强语言模型的性能。
2. 使用不相交参数进行联合训练来平衡视觉指令调整。
3. 使用视觉知识的早期融合增强文本和图像的理解能力。
4. 通过与专家集成来提高了多模态的推理能力。
线性层的偏差调整
LLaMA-Adapter在冻结的LLaMA模型上采用可学习的适应提示和零初始化注意机制,从而可以有效地整合新知识。
但是,参数更新受限于自适应提示和门控因子,没有修改LLMs的内部参数,这限制了它进行深度微调的能力。
鉴于此,研究人员提出了一种偏差调整策略,除了适应提示和门控因素之外,进一步将指令提示融合到LLaMa中。
具体来说,为了自适应地处理指令跟随数据的任务,研究人员首先解冻LLaMA 中的所有规范化层。
对于Transformer中的每个线性层,研究人员添加一个偏差和一个比例因子作为两个可学习的参数。
研究人员将某个线性层的输入和预训练权重分别表示为 x 和 W。在LLaMA-Adapter V2中,研究人员使用偏置 b 和尺度 s 修改线性层为
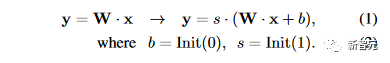
与零初始化注意力类似,研究人员分别用零和一初始化偏差和比例因子,以稳定早期阶段的训练过程。
通过结合偏置调整策略和高质量指令数据,LLaMA-Adapter V2获得了卓越的指令跟随能力。
值得注意的是,新增参数的数量仅占整个LLaMA的 0.04%(∼5M),表明 LLaMA-Adapter V2仍然是一种参数高效的方法。
使用不相交参数进行联合训练
研究人员目标是同时赋予LLaMA-Adapter V2生成长语言响应和多模态理解的能力。
下图所示,研究人员提出了LLaMA-Adapter V2的联合训练范例,以利用图像文本字幕数据和纯语言指令示例。
由于500K图像文本对和50K指令数据之间的数据量差异,直接将它们组合起来进行优化会严重损害LLaMA-Adapter的指令跟随能力。
因此,研究人员的联合训练策略优化了LLaMA-Adapter V2中不相交的参数组,分别用于图像文本对齐和指令跟随。
具体来说,只有视觉投影层和带门控的早期零初始化注意力针对图文字幕数据进行训练,而后期适应提示与零门控、未冻结范数、新添加的偏差和比例因子(或可选的低秩适应)被用于从指令跟随数据学习。
不相交的参数优化很好地解决了图文理解和指令跟随之间的干扰问题,这有助于 LLaMA-Adapter V2的视觉指令跟随能力。

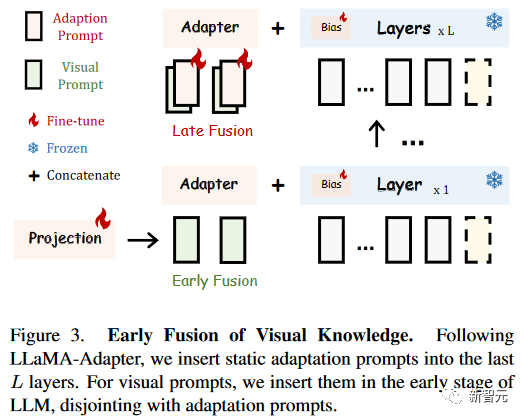
视觉知识的早期融合
为了避免视觉和语言微调之间的干扰,研究人员提出了一种简单的早期融合策略,以防止输入视觉提示和适应提示之间的直接交互。
在LLaMA-Adapter中,输入的视觉提示由具有可学习视觉投影层的冻结视觉编码器顺序编码,然后在每个插入层添加到自适应提示。
在LLaMA-Adapter V2中,研究人员将编码的视觉标记和自适应提示注入不同的Transformer层,而不将它们融合在一起,如下图所示。
对于数据集共享的自适应提示,研究人员跟随LLaMA-Adapter,将它们插入到最后L层(比如,L=30)。
对于输入的视觉提示,研究人员直接将它们与单词标记连接起来,这是具有零初始化注意力的Transformer层,而不是将它们添加到自适应提示中。
与提出的联合训练一起,这种简单的视觉标记早期融合策略可以有效地解决两类微调目标之间的冲突。
这样就使得参数高效的LLaMA-Adapter V2具有良好的多模态推理能力。
与专家集成
最近的视觉指令模型,如MiniGPT4和LLaMA需要大规模的图像文本训练来连接视觉模型和LLM。
相比之下,研究人员的LLaMA-Adapter V2对更小规模的常见图像字幕数据进行了微调,使其数据效率更高。
然而,研究人员的方法的图像理解能力相对较弱,导致偶尔出现不准确或无关的响应。
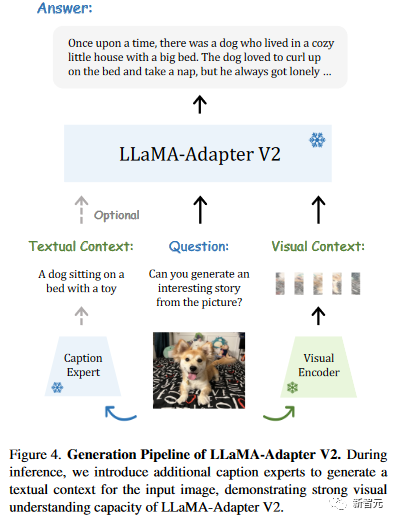
研究人员建议集成字幕、OCR和搜索引擎等专家系统,以补充LLaMA-Adapter V2额外的视觉推理能力,而不是收集更多的图像文本数据或采用更强大的多模态模块。
如下图所示,研究人员利用字幕、检测和OCR等专家系统来增强LLaMA-Adapter V2的视觉指令跟随能力。
小编亲测
小编立马上手试了一波,输入这幅图。

Prompt是,可以向我介绍一下这个电脑游戏吗?

它就会在输出中告诉你,这是“塞尔达传说:旷野之息”,并为你详细介绍游戏内容。

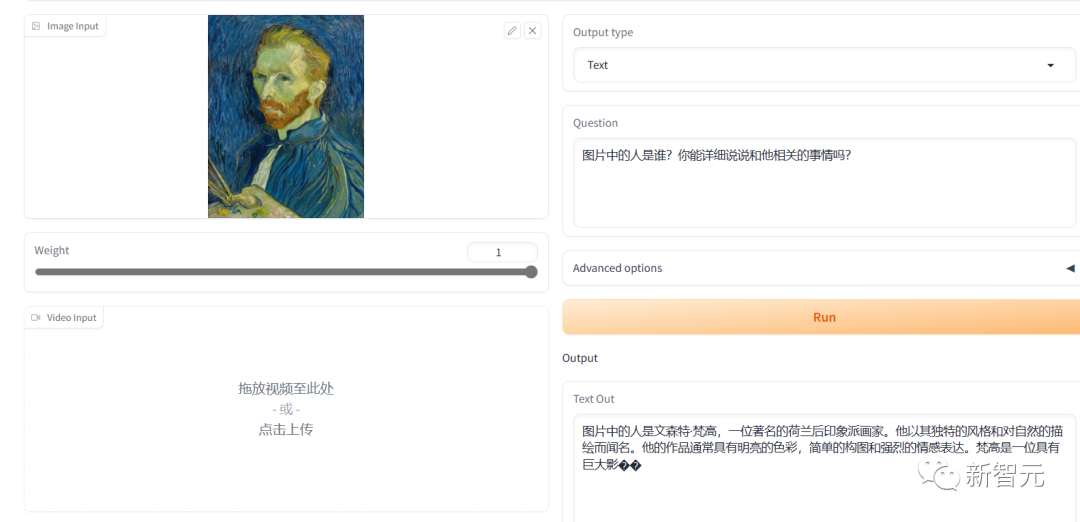
针对双语表现比较好的模型Bilingual (CN / EN) ImageBind-LLM,我们先测了一个比较简单的问题,找了一幅梵高的自画像来给它看。
中文的回答内容上没有问题,但是表达上最后一句话似乎没有说完就断了,类似的情况在后面的测试里还反复出现了。
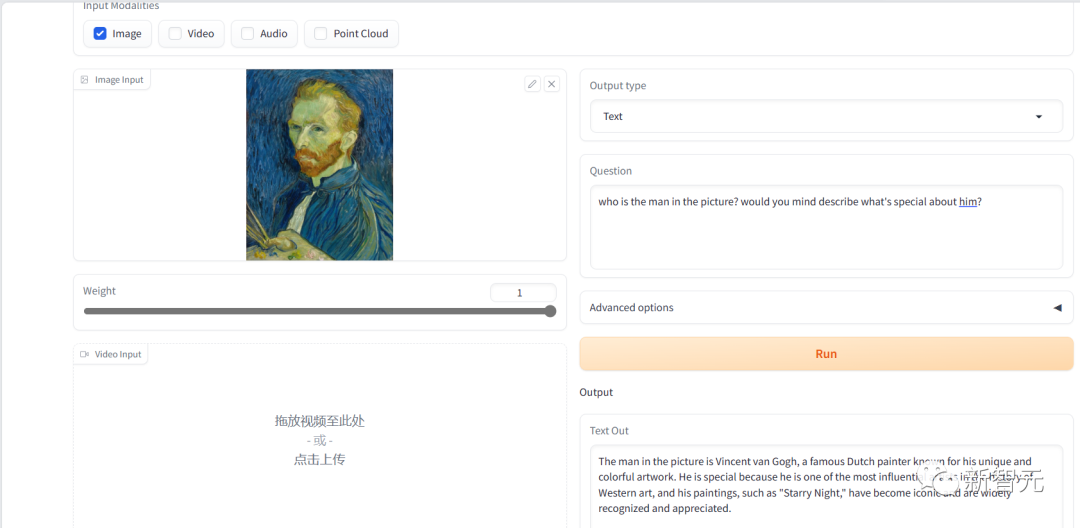
英文的回复内容和表达上都没有问题。
但是如果问题稍微难一点,小编实测后发现,它的英文能力很强,但中文的理解力明显就不是很行。
测狗狗币的时候,它就闹笑话了。
没有看出图片的精髓,还“指狗为猫”。
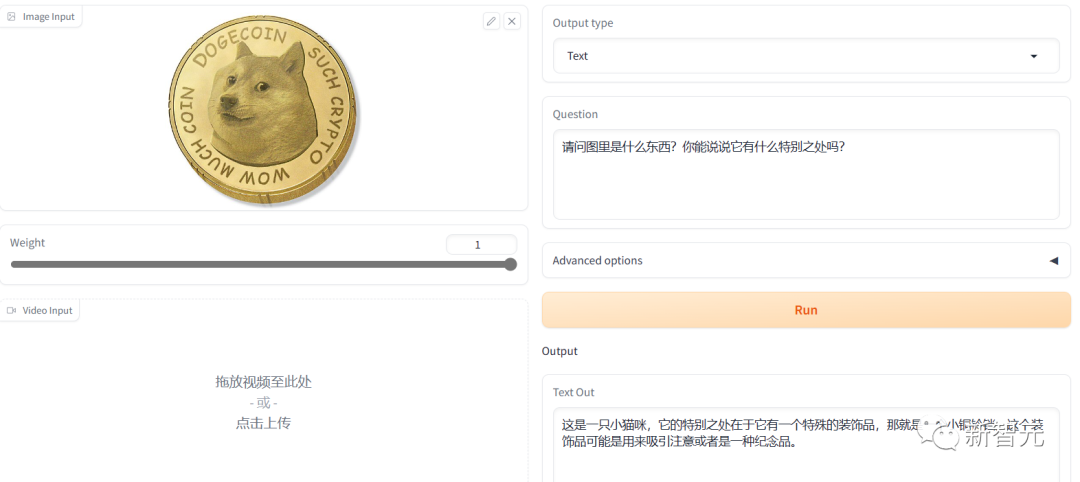
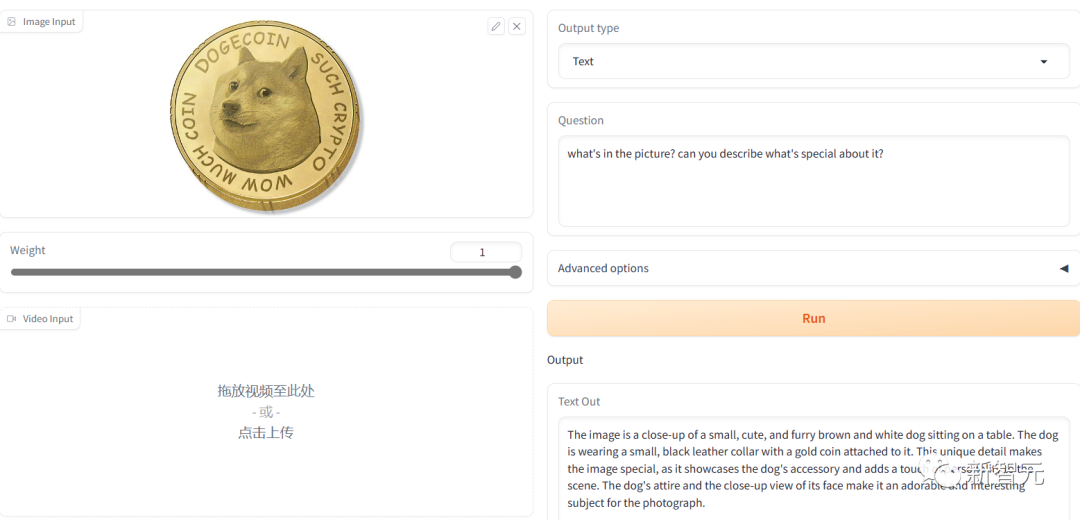
英文生产的答案明显在表达上好一些,但是还是没有识别出狗狗币。
应该是它识别的时候忽略了图中最关键的那一圈文字信息。
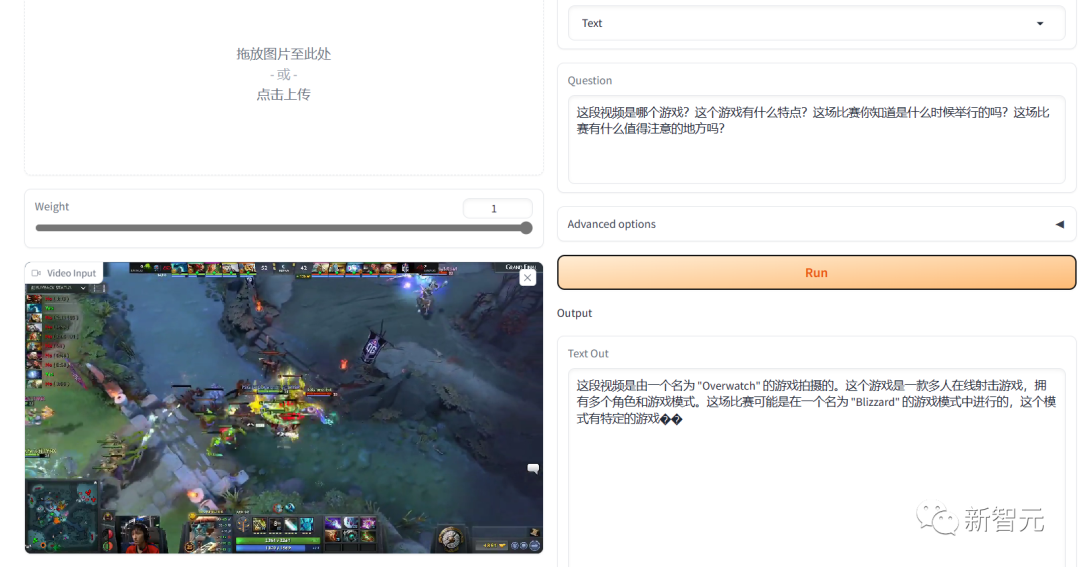
在视频的表现中我们找了一段Dota2 TI8的名局片段,用中文问它,他的回答就完全是不懂装懂。
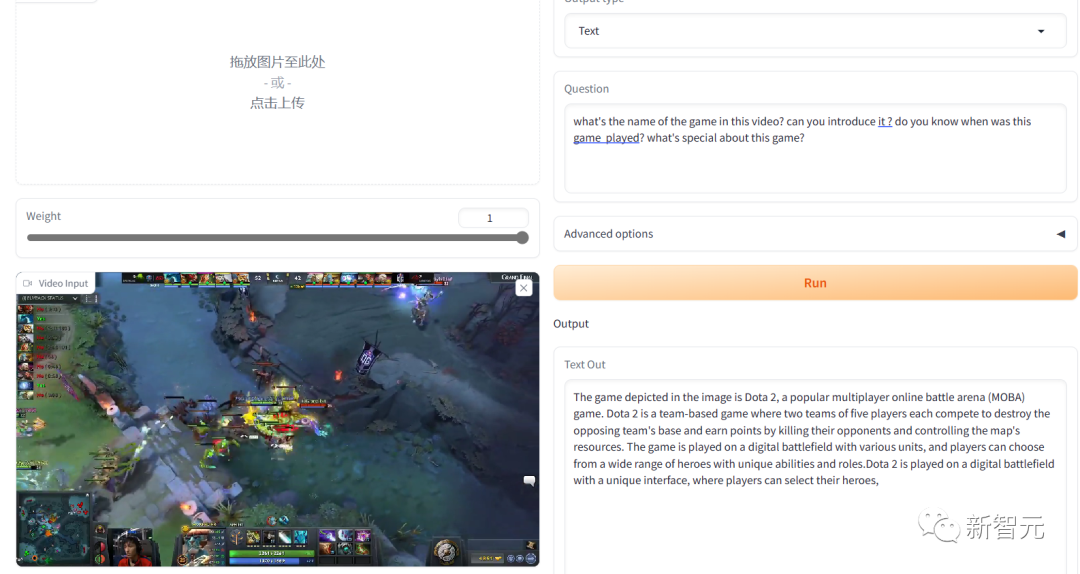
但是同样的游戏录像,用英文提问,回答得就比较令人满意。
游戏识别对了,而且介绍的内容也都很靠谱。
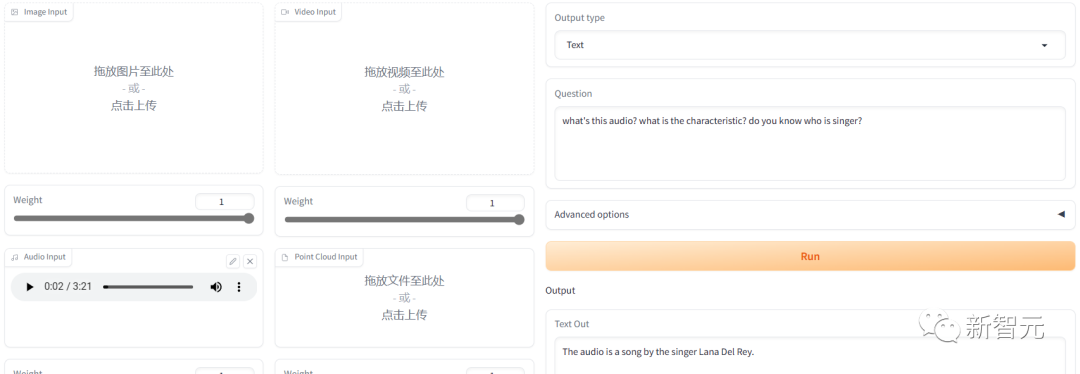
我们再测了一下声音,找了一首霉霉的歌放进去。
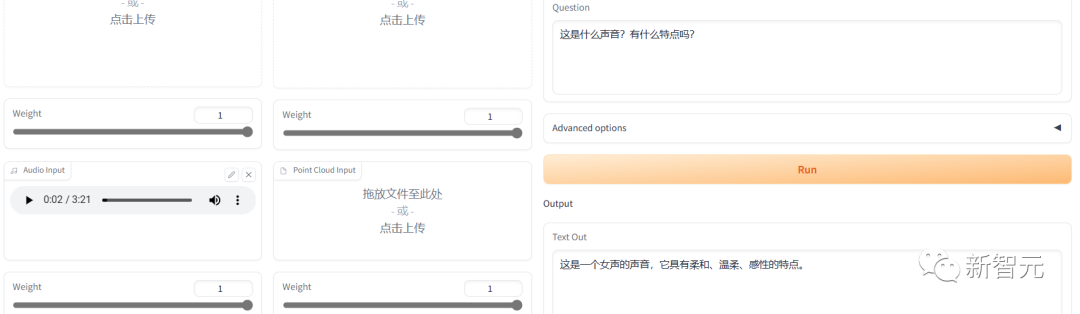
他能识别出人声声音的音调,但是听不出歌曲。
英文的回复直接猜了一个歌手,但是没猜对。
网友反应
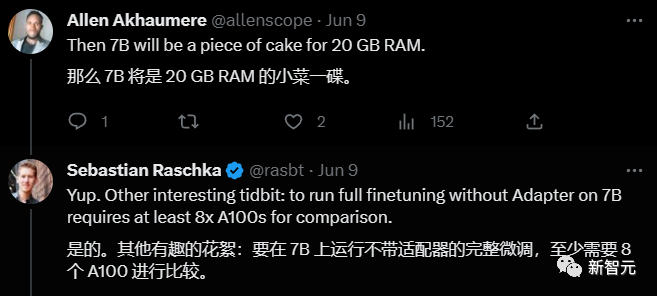
前威斯康星大学教授第一时间发推说自己上手用LLaMA-Adapter微调了一个40B Falcon的模型。

在这条微博下面他回复了大家提出的相关问题,对LLaMA-Adapter的评价非常高。
他说如果不用LLaMA-Adapter微调7B的模型,至少需要8个A100GPU,自己用了LLaMA-Adapter只用了一块GPU,门槛大大降低!
另外一位网友询问和Lora/qlora/full相比,推理质量如何,他回答说自己正在体验,进一步的信息稍后带来。

参考资料:
https://twitter.com/lupantech/status/1668387311011401728
https://zhuanlan.zhihu.com/p/626278423
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击一杯奶茶,成为AIGC+CV视觉的前沿弄潮儿!,加入 AI生成创作与计算机视觉 知识星球!