来自:Smarter
进NLP群—>加入NLP交流群

论文地址:https://arxiv.org/pdf/2305.15023.pdf
代码地址:https://github.com/luogen1996/LaVIN
将大语言模型适配到多模态指令上通常需要花费大量的训练时间。BLIP2和mini-GPT4都需要大量的图文样本对来进行预训练。同时,LLaVA需要微调整个大语言模型。这些方案都大大增加了多模态适配的成本,同时容易造成大语言模型文本能力的下降。
本文提出了一种高效的混合模态指令微调方案,实现了大语言模型对文本指令和文本+图像指令的快速适配。基于该方案,本文提出了一个新的多模态大模型(LaVIN-7B, LaVIN-13B), 它具有以下优点:
参数高效 (3~5M的训练参数)
训练高效 (在多模态科学问答数据集上,最快只要微调1.4小时)
性能优异 (比LLaMA-Adapter提升了快六个点!)
支持纯文本和文本加图像的指令对话
网络结构和训练
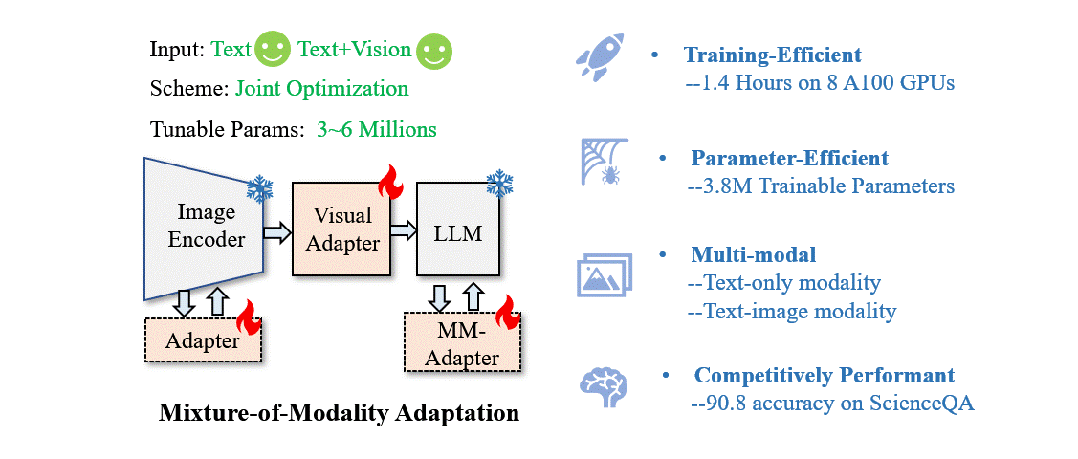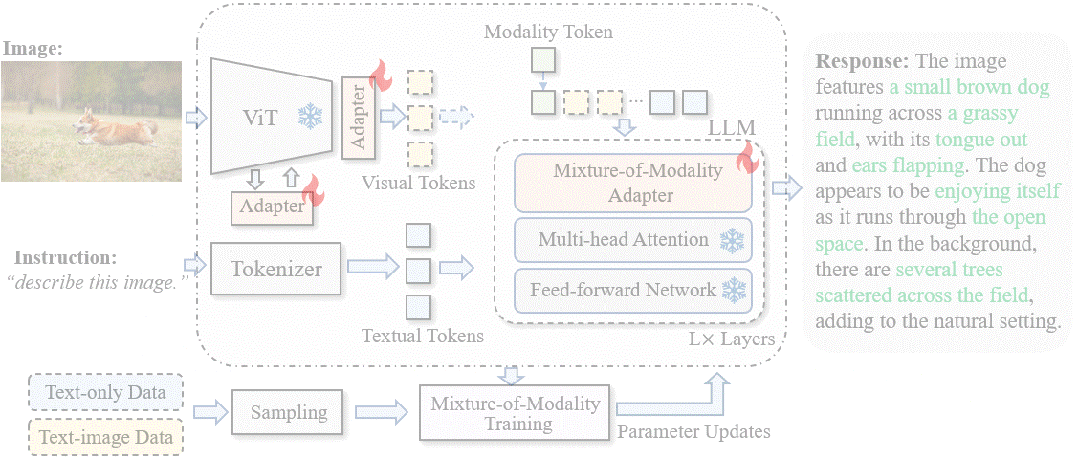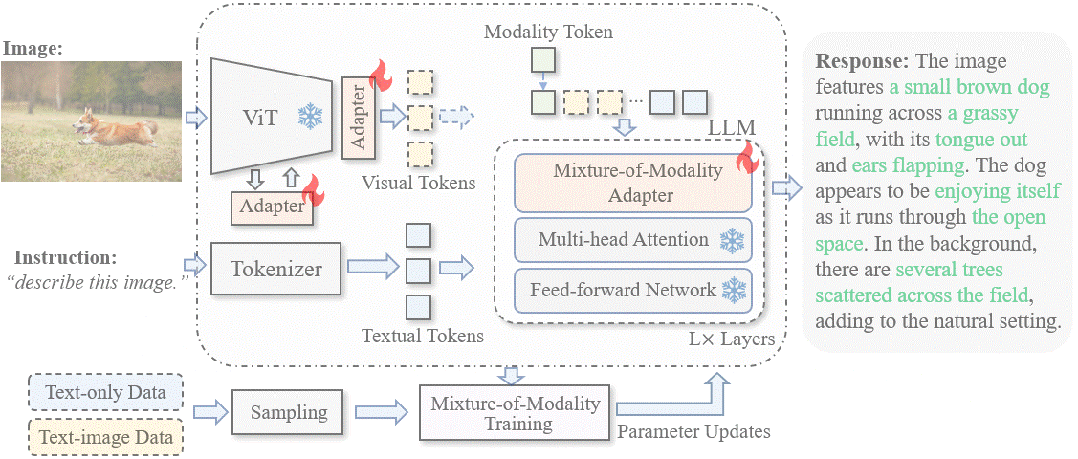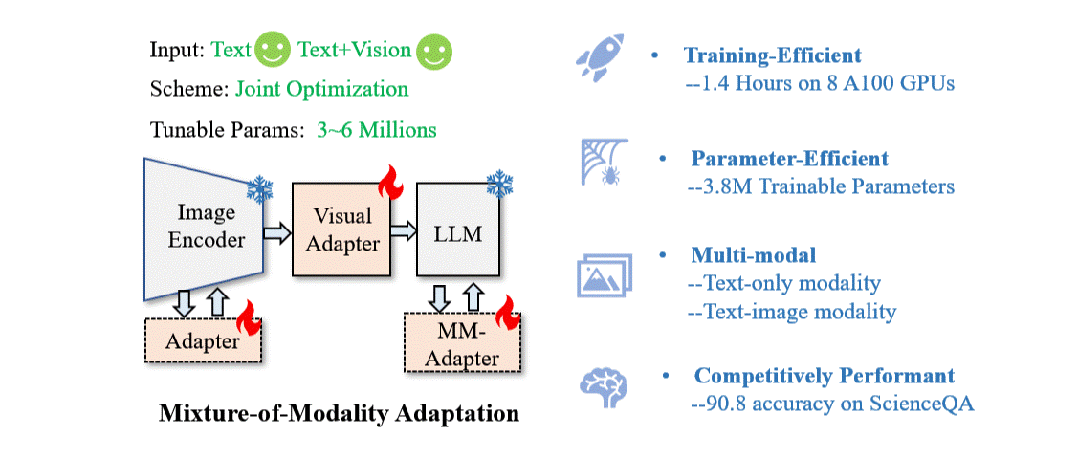
如上图所示,LaVIN基于LLaMA来进行微调,整体结构非常简洁。
端到端联合优化架构。 CLIP的backbone直接接到LLaMA,没有其它复杂的设计。整个CLIP和LLM是完全冻住的,通过加入adapter来进行训练。同时,通过在CLIP中插入了adapter,使得整个模型能够被端到端优化。相比于LLaVA,这种端到端优化节省了CLIP和LLM之间对齐的预训练过程。
多模态动态推理。 在大语言模型中,本文设计了一个新的模块叫Mixture-of-modality adapter。这个模块能够根据输入指令的模态来切换adapter的推理路径。通过这种方式,能够实现两种模态训练时的解耦。简单来说,当输入文本指令时,模型会使用一组adapter路径来进行适配。当输入的是图像+文本指令时,模型会切换到另外一组adapter路径来进行推理。
多模态混合训练。 在训练过程中,LaVIN直接将纯文本数据和图文数据混合,直接打包成batch进行训练。除此之外,没有额外的优化过程和其他复杂的设计。
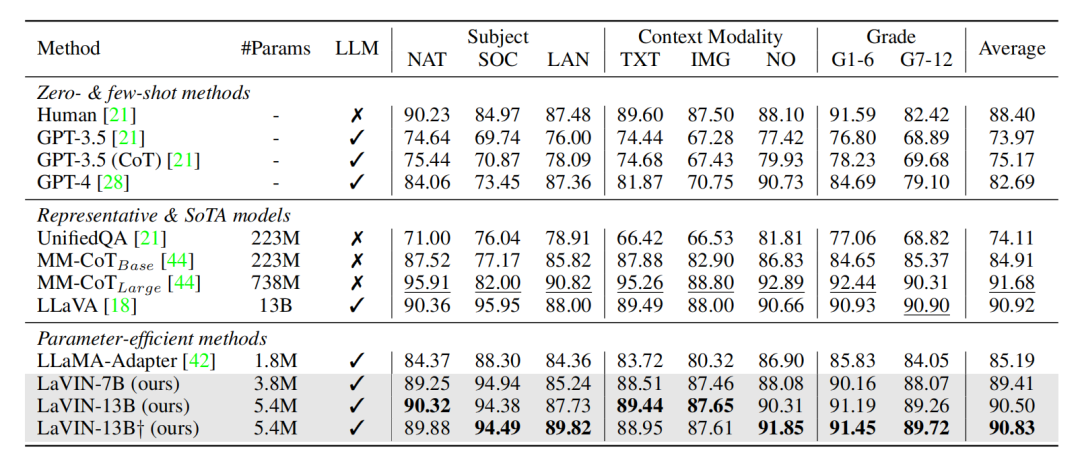
尽管LaVIN的设计和训练非常简单,但是得益于整个模型的联合优化、动态推理以及多模态混合训练。LaVIN的实际性能能够比肩LLaVA。LaVIN在多模态科学问答上,LaVIN 达到了90.8的性能,相比于LLaMA-Adapter提升了将近六个点,和LLaVA(90.9)也非常接近。在经过大约200k条GPT3+4的指令数据微调之后,LaVIN能进行高质量的文本对话以及图文对话。除此之外,这种基于adapter的范式还有非常大的优化空间,文中的训练时间和速度几乎没有采用任何优化策略。在加入QLoRA等量化训练策略之后,LaVIN的训练成本可能会再次降低一个量级。

进NLP群—>加入NLP交流群