baichuan-7B介绍
2023年6月15日,搜狗创始人王小川创立的百川智能公司,发布了70 亿参数量的中英文预训练大模型——baichuan-7B。
baichuan-7B 基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。
baichuan-7B 不仅在 C-Eval、AGIEval 和 Gaokao 中文权威评测榜单上,以显著优势全面超过了 ChatGLM-6B 等其他大模型,并且在 MMLU 英文权威评测榜单上,大幅领先 LLaMA-7B。
C-Eval榜单
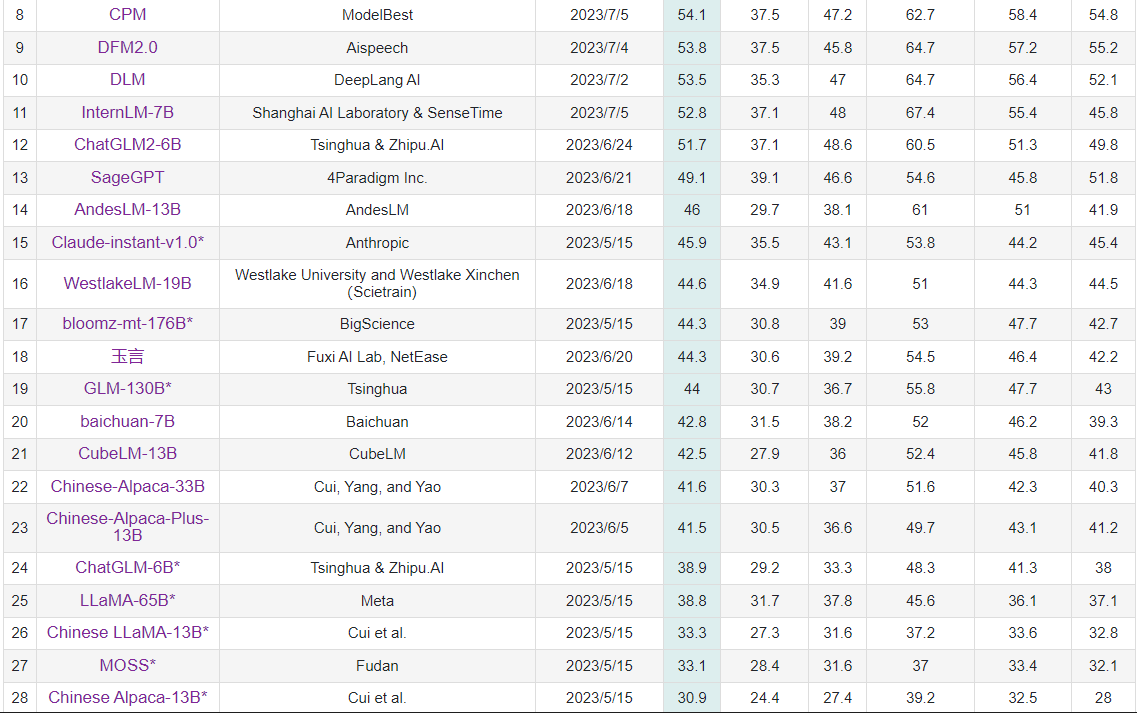
在中文 C-EVAL 的评测中,baichuan-7B 的综合评分达到了 42.8 分,超过了 ChatGLM-6B 的 38.9 分,甚至比某些参数规模更大的模型还要出色。
开源地址:
Hugging Face:https://huggingface.co/baichuan-inc/baichuan-7B
Github:https://github.com/baichuan-inc/baichuan-7B
Model Scope:https://modelscope.cn/models/baichuan-inc/baichuan-7B/summary
baichuan-7B 推理
编辑predict.py文件如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("/data/sim_chatgpt/baichuan-7B", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("/data/sim_chatgpt/baichuan-7B", device_map="auto", trust_remote_code=True)
inputs = tokenizer('登鹳雀楼->王之涣\n夜雨寄北->', return_tensors='pt')
inputs = inputs.to('cuda:0')
pred = model.generate(**inputs, max_new_tokens=64,repetition_penalty=1.1)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
运行代码
python predict.py
显存报错

显存不够,本GPU显存为16G,但模型加载需要27-28G,故考虑使用其量化版本进行加载。
修改如下:
model = AutoModelForCausalLM.from_pretrained("/data/sim_chatgpt/baichuan-7B", device_map="auto", load_in_4bit = true, trust_remote_code=True)
还需要安装下面两个包
pip install bitsandbytes
pip install scipy
运行后结果如下:
登鹳雀楼->王之涣 夜雨寄北->
2.杜甫
3. 夜雨寄北 还家十余日,家住洛桥边. 白日依山尽,思归多苦颜,(崔颢《黄鹤楼》) 黄河入海口. (崔颢《黄鹤楼》) 王之涣的《登鹳雀楼》诗. 日出江花红胜火: 黄河远上,归期何时道,一别西风又一年.” 4,洛阳亲友如相问? 白日依山尽.
-----杜甫《春日忆李白》 王之涣《凉州词(黄河远上白云间)》 《凉州词(黄河远上白云间)》 (王之涣) 黄河远上
开放协议
baichuan-7B 代码采用 Apache-2.0 协议,模型权重采用了免费商用协议,只需进行简单登记即可免费商用。
尽管baichuan-7B在一些评估数据集上效果很好,但是并不能开箱即用,因为它没有 supervised finetune 这一步,没有和人类意图进行对齐,经常听不懂你下达的指令。
baichuan-7B 微调
本次微调参考项目:https://github.com/wp931120/baichuan_sft_lora
下载项目仓库
git clone https://github.com/wp931120/baichuan_sft_lora.git
cd baichuan_sft_lora
配置环境
conda create -n baichuan-7b python=3.9
conda activate baichuan-7b
pip install -r requirements.txt
数据集下载
下载地址:https://huggingface.co/datasets/BelleGroup/train_0.5M_CN/tree/main
该数据集一共有519255条样本。
微调过程
- 先将百川LLM 采用qlora的 nf4 和双重量化方式进行量化
- 再采用lora进行指令微调
修改并运行sft_lora.py文件
- 将sft_lora.py中的模型路径设置为自己的模型路径
- 执行python sft_lora.py运行代码
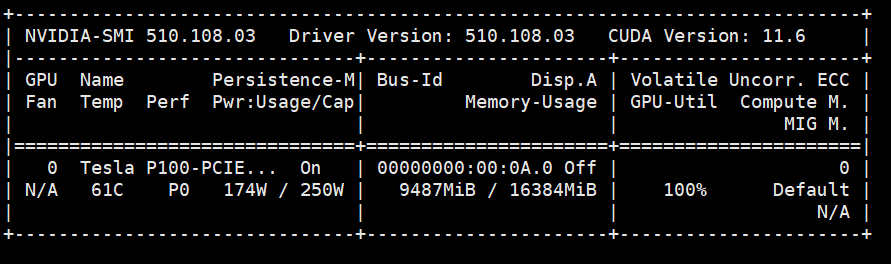 显存占用为9G左右。
显存占用为9G左右。
测试过程如下图所示:
相关参数的设置在sft_lora.py中可以找到。
验证集数量:VAL_SET_SIZE = 2000
文本最大长度:CUTOFF_LEN=1024
训练eochs数: num_train_epochs=1
训练batch_size:per_device_train_batch_size=1
验证batch_size:per_device_eval_batch_size=1
学习率:learning_rate=3e-4
梯度累积:gradient_accumulation_steps=4
LoRA中低秩近似的秩:r=8
低秩矩阵缩放超参数:lora_alpha=16
LoRA层的dropout:lora_dropout=0.05
使用微调后的模型推理
训练速度还是比较慢的,花了大概48个小时的时间,训练了72000(18000 * 4)条数据,loss基本在1.4左右。(因为梯度累积参数为4,所以训练集517255/4正好是129313)
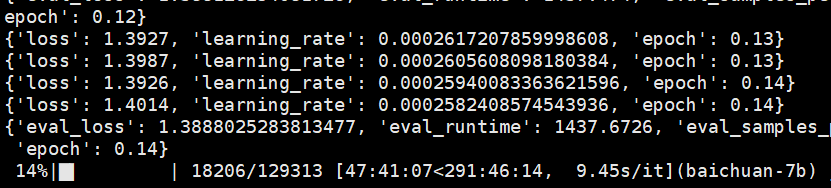
train loss
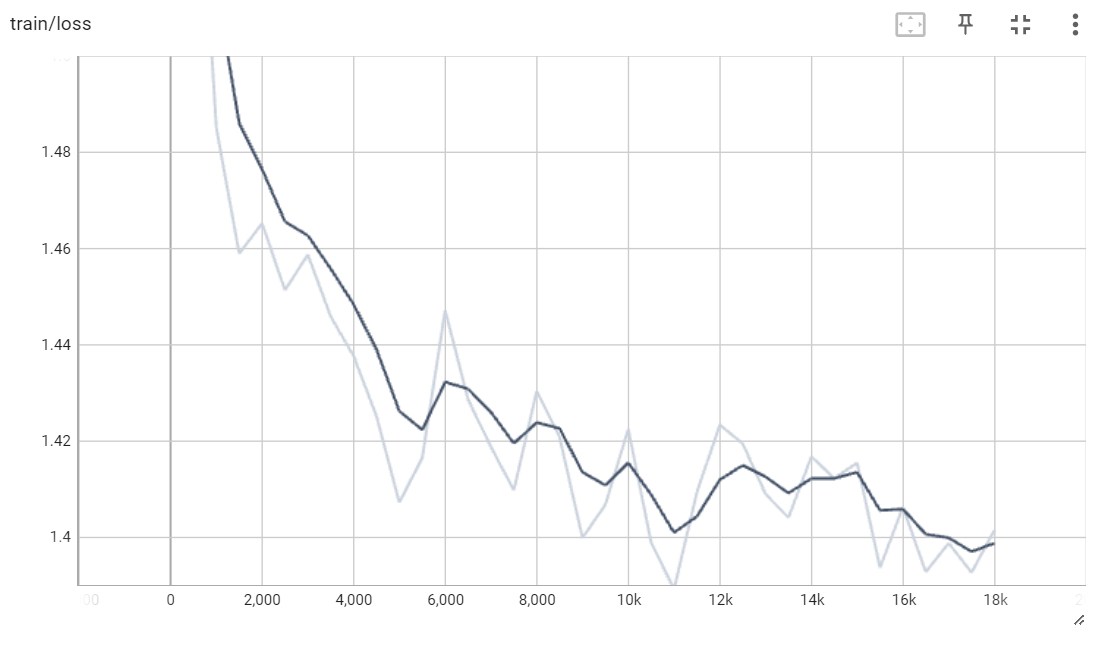
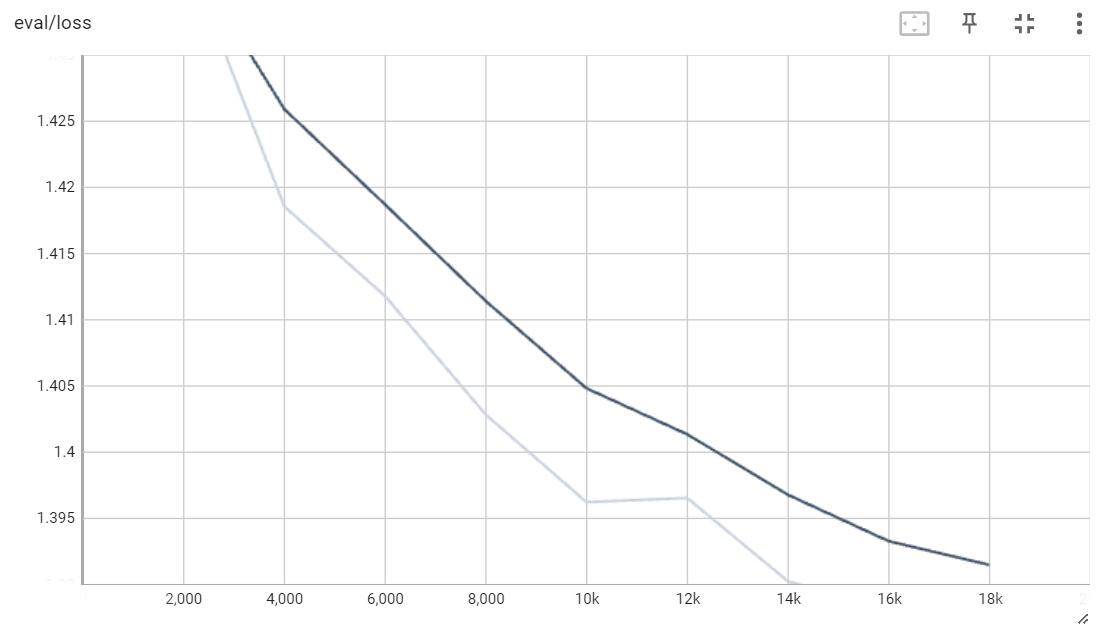
挑选数据集中的数据:
输入:"写一个制作披萨的步骤指南。 "
输出:“1. 准备面团:将面粉、盐、酵母和水混合搅拌,揉成面团,放在温暖通风处发酵。 2. 切配佐料:准备用于披萨的酱料、奶酪和各种佐料,如蔬菜、香肠、火腿等。 3. 擀面皮:将发酵好的面团擀成薄饼状,越薄越好。 4. 加入酱料:把酱料均匀地涂在面皮上。 5. 撒上奶酪和佐料:撒上足够的奶酪和各种佐料。 6. 烘烤:将披萨放进预热好的烤箱,烘烤10-15分钟,或者直到表面变为金黄色。 7. 切片享用:取出披萨,切成适当的大小,稍微冷却一下,即可食用。”
我们先看下未经过微调的模型,推理看下。

未经微调的模型仅仅是一个生成模型。
我们使用微调18000条数据后的模型进行推理,看效果还是可以的,但推理速度还是挺慢的,大概需要1~2分钟。

可以看出,已经能够明白意图了。
我们再下载已经微调好的权重来看下。
下载地址:https://huggingface.co/wp931120x/baichuan_4bit_lora

参考:
https://zhuanlan.zhihu.com/p/637343740
https://zhuanlan.zhihu.com/p/637785176
https://github.com/wp931120/baichuan_sft_lora