从本章开始,我们将正式介绍神经网络。
为什么需要神经网络:手工提取特征→学习特征
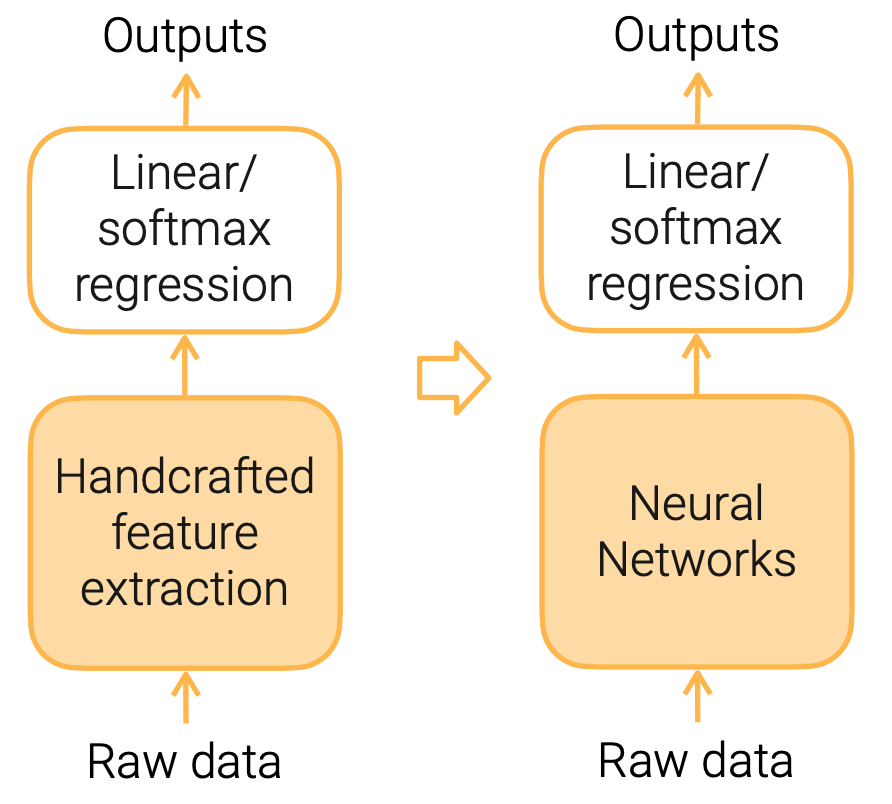
在之前讲过的线性模型中,我们往往需要对原始数据做特征工程,把原始数据表示成线性模型喜欢的特征(即每个向量必须是数,并且语义信息清楚)。
神经网络或者或深度学习,是把我们手工特征提取的部分,换成了一个神经网络。此前我们使用人的知识对特征进行提取,现在则使用神经网络对特征进行提取,它提取出的特征可能对后面的线性归回或者softmax归回来讲更好一些。
优点:神经网络的好处在于我们人不需要再画脑筋去想怎么样提取特征。
缺点:神经网络需要的数据量和计算量大数个数量级的。
一般的神经网络架构:
- 多层感知机
- 卷积神经网络
- 循环神经网络
- Transformer网络
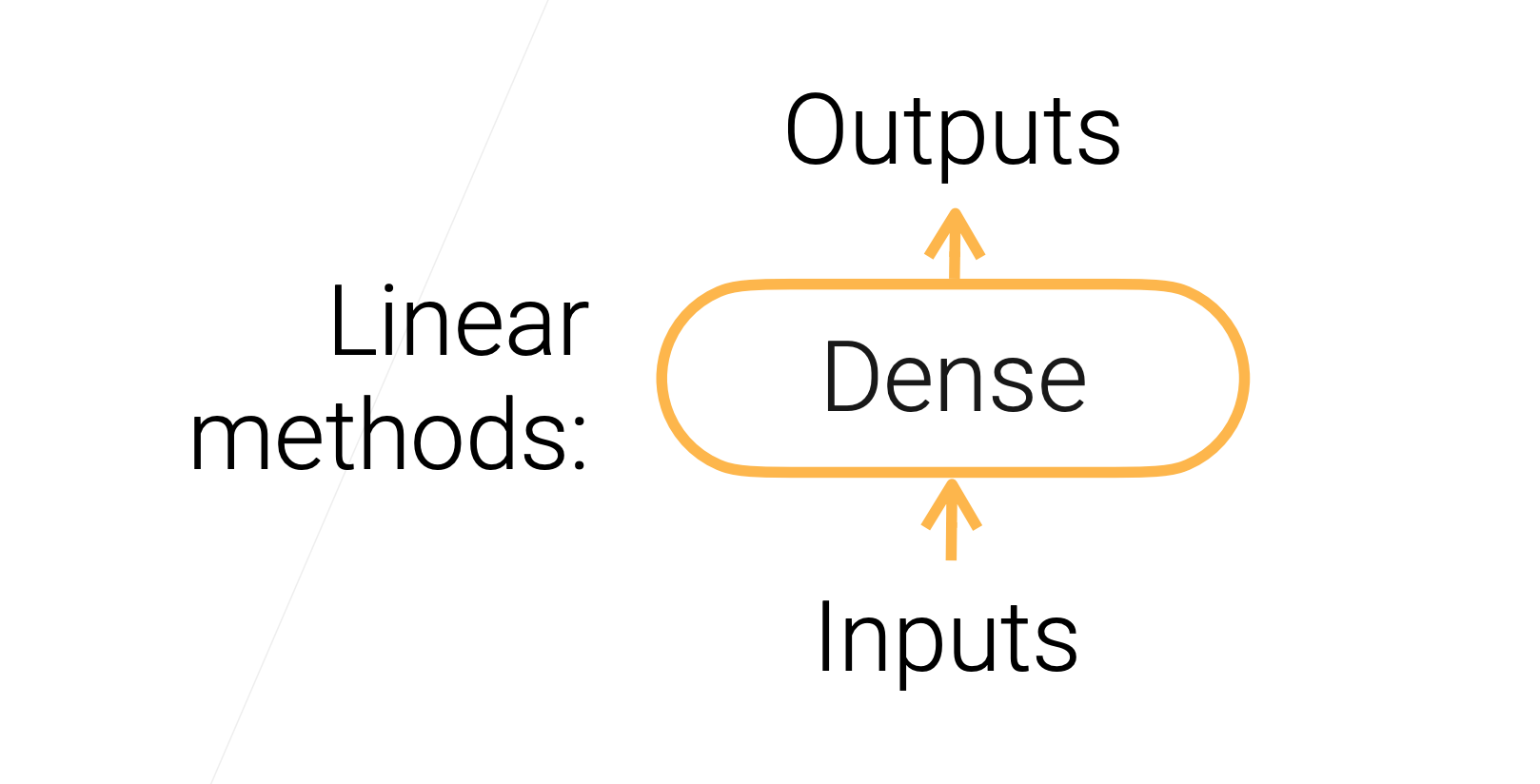
线性方法→多层感知机
多层感知机中最重要的是全连接层(fully connected layer)或叫稠密层(dence layer),这个层中包含可以学习的参数 W ∈ R m × n \mathbf{W} \in \R^{m\times n} W∈Rm×n, b ∈ R m b\in \R^{m} b∈Rm,该层计算输出为 y = W x + b ∈ R m \mathbf{y}=\mathbf{W} \mathbf{x}+\mathbf{b} \in \mathbb{R}^m y=Wx+b∈Rm。
- 线性回归就可以看做只有一个输出( m = 1 m=1 m=1)的全连接层
- Softmax回归可以看做具有 m m m个输出的全连接层+softmax操作子
所以线性模型可以统一表示成:
多层感知机(MLP)
上面的线性模型可以理解为单层感知机,那么如果表示多层感知机呢?
如果我们想得到一个非线性模型(线性模型能力有限),可以使用多个全连接层。但是仅仅使用全连接层是没有用的,因为简单的 n n n个线性操作的叠加还是一个线性操作,所以为了实现非线性,需要加入激活函数。
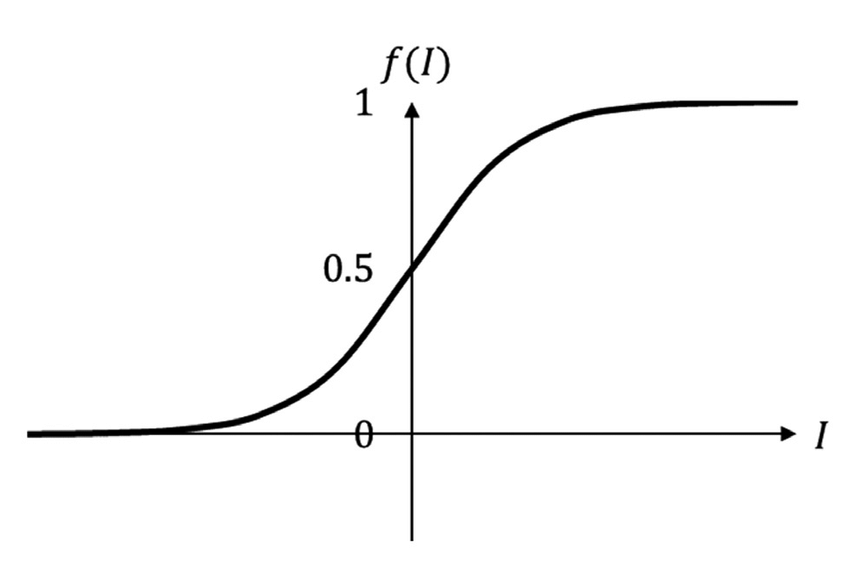
- 激活函数是一个按照元素的(elemental-wise)的非线性函数,例如Sigmoid、ReLU
sigmoid ( x ) = 1 1 + exp ( − x ) \operatorname{sigmoid}(x)=\frac{1}{1+\exp (-x)} sigmoid(x)=1+exp(−x)1
ReLU ( x ) = max ( x , 0 ) \operatorname{ReLU}(x)=\max (x, 0) ReLU(x)=max(x,0)
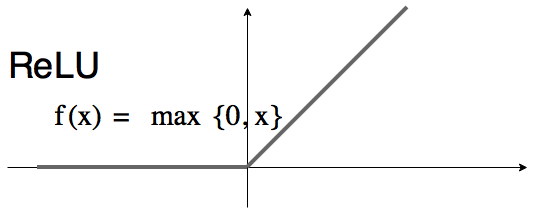
有一层隐藏层的MLP:
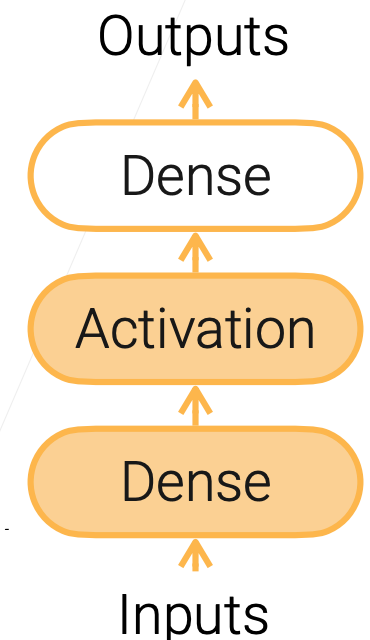
为什么标黄的Dense叫做隐藏层呢?
因为对于输出Outputs来说,只能看到最外层的Dence,所以里面的Dense是被隐藏了。
有多个隐藏层的MLP:
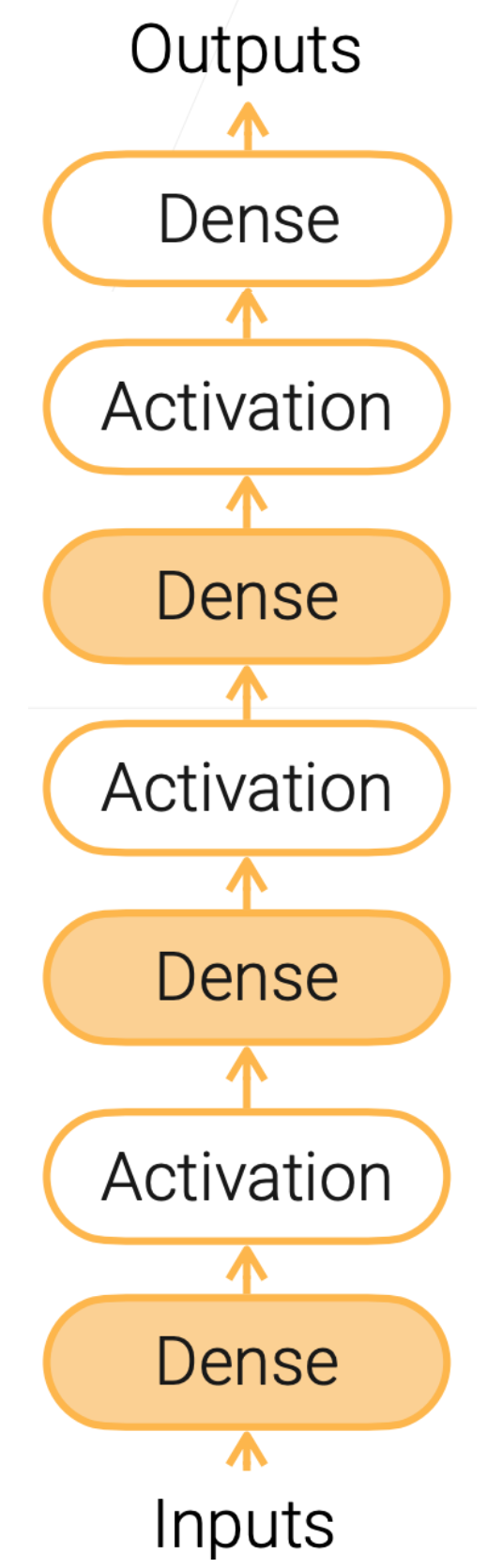
- 超参数:隐藏层的个数、每个隐藏层输出的大小都是需要手动调整的超参。
代码实现(一个隐藏层)
import torch
import torch.nn as nn
def relu(X):
return torch.max(X, 0)
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs) * 0.01)
b2 = nn.Parameter(torch.zeros(num_hiddens))
H = relu(X @ W1 + b1)
Y = H @ W2 + b2
参考资料
3.5 多层感知机【斯坦福21秋季:实用机器学习中文版】_哔哩哔哩_bilibili
https://c.d2l.ai/stanford-cs329p/_static/pdfs/cs329p_slides_5_1.pdf