
Vicuna和StableVicuna都是LLaMA的微调版本,均遵循CC BY-NC-SA-4.0协议,性能方面Stable版本更好些。
CC BY-NC-SA-4.0是一种知识共享许可协议,其全称为"署名-非商业性使用-相同方式共享 4.0 国际"。
即 用的时候要署名原作者,不能商用,下游使用也必须是相同的共享原则。
Vicuna
Vicuna(小羊驼、骆马)是LLaMA的指令微调版本模型,来自UC伯克利,代表模型为Vicuna-13B。
- 博客:Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality
- 项目代码:https://github.com/lm-sys/FastChat
- 评估方法Paper:https://arxiv.org/pdf/2306.05685.pdf
训练过程
用ShareGPT网站的用户分享的ChatGPT对话记录,70k条对话数据对 LLaMA进行监督质量微调训练,性能超越了LLaMa和Stanford Alpaca,达到了与ChatGPT相似的水平。
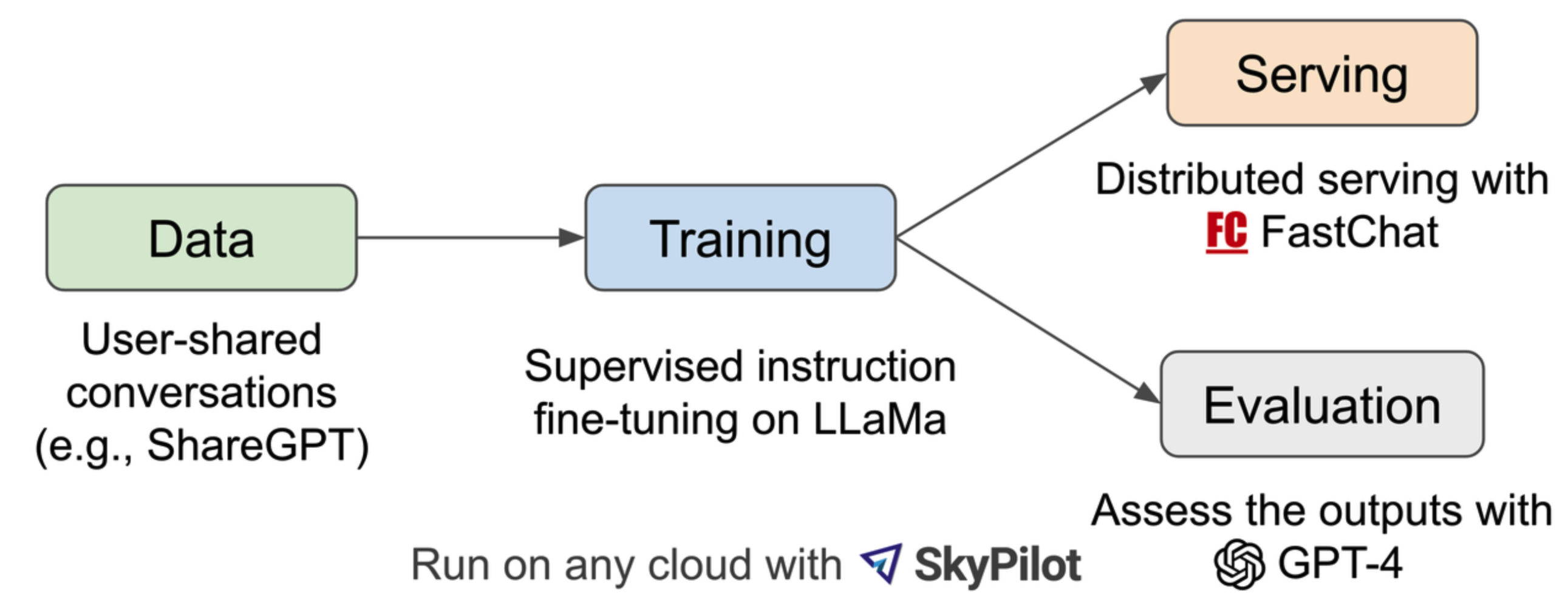
- 从ShareGPT上扒了70k对话语料,将HTML数据转化为markdown并对不合适、低质量的样本进行了过滤,同时对比较长的数据进行了切分,来适应模型的上下文长度;
- 用Alpaca的代码进行多轮对话训练,使用8-A100,基于Pytorch FSDP训练框架训一天;
- **多轮对话训练:**任务还是next token prediction,同时loss只计算文本中chatbot输出的部分;
- **显存优化:**将最大上下文长度从alpac的512调整为2048,然后用 [gradient checkpointing](https://lmsys.org/blog/2023-03-30-vicuna/#:~:text=gradient checkpointing) 和 flash attention 进行了显存节省。
- 省钱:作者使用SkyPilot的算力计算的,就使用了SkyPilot managed spot来降低成本,利用更便宜的spot实例来自动恢复抢占和自动区域切换。13B模型能从$1K节省到$300。
- 在评估模型方面,之前的评估方式对现在的对话模型不再适用了,作者用MT-Betch一个多轮对话数据集和ChatBot Arena(聊天机器人竞技场)的众包平台进行评估。众包平台上是真实的用户来进行打分,另外因为GPT-4是基于强化学习与人类反馈(RLHF)训练出来的模型,具有较好的与人对齐的能力,所以作者用GPT-4也代替人对其他模型进行评判,从而节省成本。具体可作者论文 Judging LLM-as-a-judge with MT-Bench and Chatbot Arena。
现有不足
- 推理能力、数学能力不足;
- 自我感知能力不够、幻觉问题仍然存在;
- 模型本身可能存在潜在的偏见(比如某些言论不正确,毕竟数据集决定了模型的立场)
Stable Vicuna
Stable Vicuna: https://github.com/Stability-AI/StableLM
基于 Vicuna-13B v0 的RLHF微调版本,由StabilityAI发布。没有训练细节纰漏,但应该比 Vicuna 要更优一些。